Semiconductor & Computer Engineering
(→Entire SoC Overview) |
(→Execution engine) |
||
| (262 intermediate revisions by 37 users not shown) | |||
| Line 1: | Line 1: | ||
| − | {{intel title|Skylake|arch}} | + | {{intel title|Skylake (client)|arch}} |
{{microarchitecture | {{microarchitecture | ||
| − | | atype | + | |atype=CPU |
| − | | name | + | |name=Skylake (client) |
| − | | designer | + | |designer=Intel |
| − | | manufacturer | + | |manufacturer=Intel |
| − | | introduction | + | |introduction=August 5, 2015 |
| − | + | |process=14 nm | |
| − | | process | + | |cores=2 |
| − | | cores | + | |cores 2=4 |
| − | | cores 2 | + | |type=Superscalar |
| − | | | + | |type 2=Superpipeline |
| − | + | |oooe=Yes | |
| − | + | |speculative=Yes | |
| − | + | |renaming=Yes | |
| − | + | |stages min=14 | |
| − | | type | + | |stages max=19 |
| − | | | + | |isa=x86-64 |
| − | | speculative | + | |extension 2=MMX |
| − | | renaming | + | |extension 3=SSE |
| − | + | |extension 4=SSE2 | |
| − | + | |extension 5=SSE3 | |
| − | | stages min | + | |extension 6=SSSE3 |
| − | | stages max | + | |extension 7=SSE4.1 |
| − | | | + | |extension 8=SSE4.2 |
| − | + | |extension 9=POPCNT | |
| − | + | |extension 10=AVX | |
| − | + | |extension 11=AVX2 | |
| − | + | |extension 12=AES | |
| − | | extension 2 | + | |extension 13=PCLMUL |
| − | | extension 3 | + | |extension 14=FSGSBASE |
| − | | extension 4 | + | |extension 15=RDRND |
| − | | extension 5 | + | |extension 16=FMA3 |
| − | | extension 6 | + | |extension 17=F16C |
| − | | extension 7 | + | |extension 18=BMI |
| − | | extension 8 | + | |extension 19=BMI2 |
| − | | extension 9 | + | |extension 20=VT-x |
| − | | extension 10 | + | |extension 21=VT-d |
| − | | extension 11 | + | |extension 22=TXT |
| − | | extension 12 | + | |extension 23=TSX |
| − | | extension 13 | + | |extension 25=ADCX |
| − | | extension 14 | + | |extension 27=CLFLUSHOPT |
| − | | extension 15 | + | |extension 28=XSAVE |
| − | | extension 16 | + | |l1i=32 KiB |
| − | | extension 17 | + | |l1i per=core |
| − | | extension 18 | + | |l1i desc=8-way set associative |
| − | | extension 19 | + | |l1d=32 KiB |
| − | | extension 20 | + | |l1d per=core |
| − | | extension 21 | + | |l1d desc=8-way set associative |
| − | | extension 22 | + | |l2=256 KiB |
| − | | extension 23 | + | |l2 per=core |
| − | + | |l2 desc=4-way set associative | |
| − | | extension 25 | + | |l3=2 MiB |
| − | + | |l3 per=core | |
| − | | extension 27 | + | |l3 desc=Up to 16-way set associative |
| − | | extension 28 | + | |side cache=128 MiB |
| − | + | |side cache per=package | |
| − | + | |side cache desc=on Iris Pro GPUs only | |
| − | + | |core name=Skylake Y | |
| − | + | |core name 2=Skylake U | |
| − | + | |core name 3=Skylake H | |
| − | | l1i | + | |core name 4=Skylake S |
| − | | l1i per | + | |core name 5=Skylake DT |
| − | | l1i desc | + | |predecessor=Broadwell |
| − | | l1d | + | |predecessor link=intel/microarchitectures/broadwell |
| − | | l1d per | + | |successor=Kaby Lake |
| − | | l1d desc | + | |successor link=intel/microarchitectures/kaby lake |
| − | | l2 | + | |contemporary=Skylake (server) |
| − | | l2 per | + | |contemporary link=intel/microarchitectures/skylake (server) |
| − | | l2 desc | + | |pipeline=Yes |
| − | | l3 | + | |OoOE=Yes |
| − | | l3 per | + | |issues=5 |
| − | | l3 desc | + | |core names=Yes |
| − | | | ||
| − | | | ||
| − | | | ||
| − | |||
| − | |||
| − | | core name | ||
| − | | core name 2 | ||
| − | | core name 3 | ||
| − | | core name 4 | ||
| − | | core name 5 | ||
| − | |||
| − | |||
| − | |||
| − | | predecessor | ||
| − | | predecessor link = intel/microarchitectures/broadwell | ||
| − | | successor | ||
| − | | successor link | ||
}} | }} | ||
| − | '''Skylake''' ('''SKL''') is [[Intel]]'s successor to {{\\|Broadwell}}, a [[14 nm process]] [[microarchitecture]] for mainstream desktops | + | '''Skylake''' ('''SKL''') '''Client Configuration''' is [[Intel]]'s successor to {{\\|Broadwell}}, a [[14 nm process]] [[microarchitecture]] for mainstream workstations, desktops, and mobile devices. Skylake succeeded the short-lived {{\\|Broadwell}} which experienced severe delays. Skylake is the "Architecture" phase as part of Intel's {{intel|PAO}} model. The microarchitecture was developed by Intel's R&D center in [[wikipedia:Haifa, Israel|Haifa, Israel]]. |
| − | For desktop and mobile, Skylake is branded as 6th Generation Intel {{intel|Core i3}}, {{intel|Core i5}} | + | For desktop and mobile, Skylake is branded as 6th Generation Intel {{intel|Core i3}}, {{intel|Core i5}}, {{intel|Core i7}} processors. For workstations it's branded as {{intel|Xeon E3|Xeon E3 v5}}. |
== Codenames == | == Codenames == | ||
| + | {{see also|intel/microarchitectures/skylake_(server)#Codenames|l1=Server Skylake's Codenames}} | ||
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
| − | ! Core !! Abbrev !! Target | + | ! Core !! Abbrev !! Platform !! Target |
| + | |- | ||
| + | | {{intel|Skylake Y|l=core}} || SKL-Y || || 2-in-1s detachable, tablets, and computer sticks | ||
| + | |- | ||
| + | | {{intel|Skylake U|l=core}} || SKL-U || || Light notebooks, portable All-in-Ones (AiOs), Minis, and conference room | ||
| + | |- | ||
| + | | {{intel|Skylake H|l=core}} || SKL-H || || Ultimate mobile performance, mobile workstations | ||
| + | |- | ||
| + | | {{intel|Skylake S|l=core}} || SKL-S || || Desktop performance to value, AiOs, and minis | ||
| + | |- | ||
| + | | {{intel|Skylake DT|l=core}} || SKL-DT || {{intel|Greenlow|l=platform}} || Workstations & entry-level servers | ||
| + | |} | ||
| + | |||
| + | == Brands == | ||
| + | {{see also|intel/microarchitectures/skylake_(server)#Brands|l1=Server Skylake's Brands}} | ||
| + | Intel released Skylake under 6 main brand families for mainstream workstations, desktops, and mobile. | ||
| + | |||
| + | {| class="wikitable tc4 tc5 tc6 tc7 tc8" style="text-align: center;" | ||
| + | |- | ||
| + | ! rowspan="2" | Logo !! rowspan="2" | Family !! rowspan="2" | General Description !! colspan="7" | Differentiating Features | ||
| + | |- | ||
| + | ! Cores !! {{intel|Hyper-Threading|HT}} !! {{x86|AVX}} !! {{x86|AVX2}} !! {{intel|Turbo Boost|TBT}} !! [[ECC]] | ||
| + | |- | ||
| + | | rowspan="2" | [[File:intel celeron (2015).png|50px|link=intel/celeron]] || rowspan="2" | {{intel|Celeron}} || style="text-align: left;" | Entry-level Budget || rowspan="2" | [[dual-core|dual]] || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} | ||
| + | |- | ||
| + | | style="text-align: left;" | Entry-level Budget (Embedded) || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|yes}} | ||
| + | |- | ||
| + | | rowspan="2" | [[File:intel pentium (2015).png|50px|link=intel/pentium_(2009)]] || rowspan="2" | {{intel|Pentium (2009)|Pentium}} || style="text-align: left;" | Budget (Mobile) || rowspan="2" | dual || {{tchk|yes}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} | ||
| + | |- | ||
| + | | style="text-align: left;" | Budget (Desktop) || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|no}} || {{tchk|yes}} | ||
| + | |- | ||
| + | | rowspan="2" | [[File:core i3 logo (2015).png|50px|link=intel/core_i3]] || rowspan="2" | {{intel|Core i3}} || style="text-align: left;" | Low-end Performance || rowspan="2" | dual || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|no}} | ||
|- | |- | ||
| − | | | + | | style="text-align: left;" | Low-end Performance<br>(Desktop/Embedded) || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|yes}} |
|- | |- | ||
| − | | | + | | rowspan="2" | [[File:core i5 logo (2015).png|50px|link=intel/core_i5]] || rowspan="2" | {{intel|Core i5}} || rowspan="2" style="text-align: left;" | Mid-range Performance || dual || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} |
|- | |- | ||
| − | | | + | |[[quad-core|quad]] || {{tchk|no}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} |
|- | |- | ||
| − | | | + | | rowspan="2" | [[File:core i7 logo (2015).png|50px|link=intel/core_i7]] || rowspan="2" | {{intel|Core i7}} || rowspan="2" style="text-align: left;" | High-end Performance || dual || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} |
|- | |- | ||
| − | | | + | |quad || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} |
|- | |- | ||
| − | | | + | | [[File:xeon logo (2015).png|50px|link=intel/xeon e3]] || {{intel|Xeon E3}} || style="text-align: left;" | Workstation/dense servers || quad || {{tchk|some}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} |
|} | |} | ||
| Line 117: | Line 132: | ||
== Process Technology == | == Process Technology == | ||
{{main|intel/microarchitectures/broadwell#Process_Technology|l1=Broadwell § Process Technology}} | {{main|intel/microarchitectures/broadwell#Process_Technology|l1=Broadwell § Process Technology}} | ||
| − | Skylake uses the same [[14 nm process]] used for the Broadwell microarchitecture. | + | Skylake uses the same [[14 nm process]] used for the Broadwell microarchitecture for all mainstream consumer parts (Core, Celeron, et al). |
| + | |||
| + | == Compatibility == | ||
| + | {| class="wikitable" | ||
| + | ! Vendor !! OS !! Version !! Notes | ||
| + | |- | ||
| + | | rowspan="4" | [[Microsoft]] || rowspan="4" | Windows || style="background-color: #ffdad6;" | Windows Vista || No Support | ||
| + | |- | ||
| + | | style="background-color: #d6ffd8;" | Windows 7 || rowspan="2" | Support ends July 2018 | ||
| + | |- | ||
| + | | style="background-color: #d6ffd8;" | Windows 8.1 | ||
| + | |- | ||
| + | | style="background-color: #d6ffd8;" | Windows 10 || Support | ||
| + | |- | ||
| + | | Linux || Linux || style="background-color: #d6ffd8;" | Kernel 3.19 || Initial Support (MPX support) | ||
| + | |- | ||
| + | | Google || Chromium || style="background-color: #d6ffd8;" | Chromium || Support | ||
| + | |- | ||
| + | | Wind River || VxWorks || style="background-color: #d6ffd8;" | VxWorks 5.5? || Support | ||
| + | |} | ||
== Compiler support == | == Compiler support == | ||
| Line 131: | Line 165: | ||
|- | |- | ||
| [[Visual Studio]] || <code>/arch:AVX2</code> || <code>/tune:skylake</code> | | [[Visual Studio]] || <code>/arch:AVX2</code> || <code>/tune:skylake</code> | ||
| + | |} | ||
| + | |||
| + | === CPUID === | ||
| + | {| class="wikitable tc1 tc2 tc3 tc4" | ||
| + | ! Core !! Extended<br>Family !! Family !! Extended<br>Model !! Model | ||
| + | |- | ||
| + | | rowspan="2" | {{intel|Skylake Y|Y|l=core}}/{{intel|Skylake U|U|l=core}} || 0 || 0x6 || 0x4 || 0xE | ||
| + | |- | ||
| + | | colspan="4" | Family 6 Model 78 | ||
| + | |- | ||
| + | | rowspan="2" | {{intel|Skylake DT|DT|l=core}}/{{intel|Skylake H|H|l=core}}/{{intel|Skylake S|S|l=core}} || 0 || 0x6 || 0x5 || 0xE | ||
| + | |- | ||
| + | | colspan="4" | Family 6 Model 94 | ||
|} | |} | ||
| Line 137: | Line 184: | ||
=== Key changes from {{\\|Broadwell}} === | === Key changes from {{\\|Broadwell}} === | ||
| + | [[File:skylake buff window.png|right|350px]] | ||
* 8x performance/watt over {{\\|Nehalem}} (Up from 3.5x in {{\\|Haswell}}) | * 8x performance/watt over {{\\|Nehalem}} (Up from 3.5x in {{\\|Haswell}}) | ||
* Mainstream chipset | * Mainstream chipset | ||
| Line 143: | Line 191: | ||
*** {{intel|Direct Media Interface|DMI 3.0}} (from 2.0) | *** {{intel|Direct Media Interface|DMI 3.0}} (from 2.0) | ||
**** Skylake S and Skylake H cores, connected by 4-lane DMI 3.0 | **** Skylake S and Skylake H cores, connected by 4-lane DMI 3.0 | ||
| − | **** Skylake Y and Skylake U cores have chipset in the same package (simplified {{intel|on Package I/O|OPIO}}) | + | **** {{intel|Skylake Y|l=core}} and Skylake U cores have chipset in the same package (simplified {{intel|on Package I/O|OPIO}}) |
**** Increase in transfer rate from 5.0 GT/s to 8.0 GT/s (~3.93GB/s up from 2GB/s) per lane | **** Increase in transfer rate from 5.0 GT/s to 8.0 GT/s (~3.93GB/s up from 2GB/s) per lane | ||
| − | **** Limits motherboard trace design to 7 inches max from (down from 8) | + | **** Limits motherboard trace design to 7 inches max from the CPU to chipset (down from 8) |
| + | ** PCIe & DMI upgraded to Gen3 | ||
| + | ** More I/O (configurable as PCIe/SATA/USB3) | ||
| + | ** Lower-power I/O (eMMC, UFS, SDXC) | ||
| + | ** CSI-2 for the integrated IPU (mobile SKUs) | ||
| + | ** Intel Sensor Solution Hub integration | ||
| + | ** Larger Line Fill Buffer? | ||
| + | |||
* [[System Agent]] | * [[System Agent]] | ||
** New Image Processing Unit (IPU) | ** New Image Processing Unit (IPU) | ||
*** Incorporates an [[image signal processor]] (ISP) | *** Incorporates an [[image signal processor]] (ISP) | ||
*** Mobile client models only | *** Mobile client models only | ||
| + | ** Can now have its own variable voltage and frequency | ||
* Core | * Core | ||
** Front End | ** Front End | ||
| − | |||
| − | |||
*** Allocation Queue (IDQ) | *** Allocation Queue (IDQ) | ||
| + | **** Wider Allocation path (5-way, up from 4-way in broadwell) | ||
**** Larger delivery (6 µOPs, up from 4) | **** Larger delivery (6 µOPs, up from 4) | ||
**** 2.28x larger buffer (64/thread, up from 56) | **** 2.28x larger buffer (64/thread, up from 56) | ||
| Line 167: | Line 222: | ||
*** Larger [[re-order buffer]] (224 entries, up from 192) | *** Larger [[re-order buffer]] (224 entries, up from 192) | ||
*** Larger scheduler (97 entries, up from 64) | *** Larger scheduler (97 entries, up from 64) | ||
| − | **** Larger Integer Register File (180 entries, up from | + | **** Larger Integer Register File (180 entries, up from 168) |
| − | **** Larger Retire ( | + | **** Larger Retire (4 µOPs/cycle/thread, up from 4 µOPs/cycle/core)? |
** Memory Subsystem | ** Memory Subsystem | ||
*** Larger store buffer (56 entries, up from 42) | *** Larger store buffer (56 entries, up from 42) | ||
*** [[L2$]] was changed from 8-way to 4-way set associative | *** [[L2$]] was changed from 8-way to 4-way set associative | ||
*** Page split load penalty reduced 20-fold | *** Page split load penalty reduced 20-fold | ||
| + | *** Larger Write-back buffer | ||
* Memory | * Memory | ||
| Line 189: | Line 245: | ||
** The fully integrated voltage regulator (FIVR) is moved back to the motherboard | ** The fully integrated voltage regulator (FIVR) is moved back to the motherboard | ||
*** Originally intended to be a cost-cutting measure by moving the FIVR on-die as well as making it more efficient, the move resulted in unintentionally making the FIVR the limiting factor when it came to overclocking. | *** Originally intended to be a cost-cutting measure by moving the FIVR on-die as well as making it more efficient, the move resulted in unintentionally making the FIVR the limiting factor when it came to overclocking. | ||
| + | ** DMI/PEG are now on a discrete clock domain with BCLK sitting on its own domain with full-range granularity (1 MHz intervals) | ||
* Testability | * Testability | ||
** New support for {{intel|Direct Connect Interface}} (DCI), a new debugging transport protocol designed to allow debugging of closed cases (e.g. laptops, embedded) by accessing things such as [[JTAG]] through any [[USB 3]] port. | ** New support for {{intel|Direct Connect Interface}} (DCI), a new debugging transport protocol designed to allow debugging of closed cases (e.g. laptops, embedded) by accessing things such as [[JTAG]] through any [[USB 3]] port. | ||
| + | |||
| + | * {{intel|Gen9|Gen 9 GPUs|l=arch}} | ||
| + | ** Improved underlying implementation of the memory QoS for higher resolution displays and the integrated [[image signal processor]] (ISP) | ||
| + | *** Allow for higher concurrent bandwidth | ||
| + | ** Skylake retires VGA support, multi-monitor support for up to 3 displays via HDMI 1.4, DP 1.2, and eDP 1.3 interfaces. | ||
| + | ** Direct X 12, OpenCL 2.0, OpenGL 4.4 | ||
| + | ** Up to 24 EUs GT2 (same as {{\\|Haswell}}); 48 EUs for GT3, and up to 72 EUs on {{intel|Iris Pro Graphics}} | ||
| + | *** 384 GFLOPS @ 1 GHz (GT2) | ||
==== CPU changes ==== | ==== CPU changes ==== | ||
| − | * | + | * Like Haswell, most general purpose ALU operations execute at up to 4 ops/cycle for 8, 32 and 64-bit registers. (16-bit throughput varies per op, can be 4, 3.5 or 2 op/cycle). |
| − | * | + | * ADC and SBB are single uop (like Broadwell), down from 2 in Haswell. Throughput of 1 op/cycle, or 2/c if not bottlenecked by one long dependency, same as Haswell. |
| − | + | * Vector moves have throughput of 4 op/cycle (improved move elimination for nothing-but-move microbenchmarks) | |
| − | * Vector moves have throughput of 4 op/cycle (move elimination) | + | * vPCMPGTx on the same register is recognized as a zeroing idiom (4 ops/cycle, no execution unit) like vpXORxx and vPSUBx zeroing. |
| − | * | + | * Vector ALU ops are often "standardized" to latency of 4. for example, vADDPS and vMULPS used to have L of 3 and 5 in HSW, or both 3 in BDW, now both are 4. |
| − | * Vector ALU ops are often "standardized" to latency of 4. for example, vADDPS and vMULPS used to have L of 3 and 5, now both are 4. | + | * Fused multiply-add ops have latency of 4 and throughput of 0.5 op/cycle, improved from 5 cycle latency. |
| − | * Fused multiply-add ops have latency of 4 and throughput of 0.5 op/cycle. | + | * Throughput of vADDps, vSUBps, vCMPps, vMAXps, their scalar and double analogs is increased to 2 op/cycle. Lower latency SIMD FP-add unit on port 1 removed in favour of running all FP math on the FMA units. |
| − | * Throughput of vADDps, vSUBps, vCMPps, vMAXps, their scalar and double analogs is increased to 2 op/cycle. | + | * Throughput of vPSLxx and vPSRxx with immediate (i.e. fixed vector shifts) is increased to 2 op/cycle, along with VPSxxVx variable shifts. |
| − | * Throughput of vPSLxx and vPSRxx with immediate (i.e. fixed vector shifts) is increased to 2 op/cycle. | ||
* Throughput of vANDps, vANDNps, vORps, vXORps, their scalar and double analogs, vPADDx, vPSUBx is increased to 3 op/cycle. | * Throughput of vANDps, vANDNps, vORps, vXORps, their scalar and double analogs, vPADDx, vPSUBx is increased to 3 op/cycle. | ||
* vDIVPD, vSQRTPD have approximately twice as good throughput: from 8 to 4 and from 28 to 12 cycles/op. | * vDIVPD, vSQRTPD have approximately twice as good throughput: from 8 to 4 and from 28 to 12 cycles/op. | ||
* Throughput of some MMX ALU ops (such as PAND mm1, mm2) is decreased to 2 or 1 op/cycle (users are expected to use wider SSE/AVX registers instead). | * Throughput of some MMX ALU ops (such as PAND mm1, mm2) is decreased to 2 or 1 op/cycle (users are expected to use wider SSE/AVX registers instead). | ||
| − | + | ====New instructions ==== | |
| − | + | {{see also|intel/microarchitectures/skylake_(server)#New instructions|l1=Server Skylake's New instructions}} | |
| − | + | Skylake introduced a number of {{x86|extensions|new instructions}}: | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | * {{x86|SGX1|<code>SGX1</code>}} - Software Guard Extensions, Version 1 | |
| − | * | + | * {{x86|MPX|<code>MPX</code>}} -Memory Protection Extensions |
| − | + | * {{x86|XSAVEC|<code>XSAVEC</code>}} - Save processor extended states with compaction to memory | |
| − | + | * {{x86|XSAVES|<code>XSAVES</code>}} - Save processor supervisor-mode extended states to memory. | |
| − | * | + | * {{x86|CLFLUSHOPT|<code>CLFLUSHOPT</code>}} - Flush & Invalidates memory operand and its associated cache line (All L1/L2/L3 etc..) |
| − | * | ||
| − | * | ||
| − | |||
| − | |||
| − | + | === Block Diagram === | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | ==== | + | ==== Entire SoC Overview (dual) ==== |
| − | + | [[File:skylake soc block diagram (dual).svg|800px]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | ==== Entire SoC Overview (quad) ==== | |
| − | |||
| − | |||
[[File:skylake soc block diagram.svg|900px]] | [[File:skylake soc block diagram.svg|900px]] | ||
| − | ==== | + | ==== Individual Core ==== |
| − | [[File:skylake | + | [[File:skylake block diagram.svg|900px]] |
| − | |||
| − | |||
| − | |||
| − | + | ==== Gen9 ==== | |
See {{intel|Gen9#Gen9|l=arch}}. | See {{intel|Gen9#Gen9|l=arch}}. | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
=== Memory Hierarchy === | === Memory Hierarchy === | ||
Other than a few organizational changes (e.g. L2$ went from 8-way to 4-way set associative), the overall memory structure is identical to {{\\|Broadwell}}/{{\\|Haswell}}. | Other than a few organizational changes (e.g. L2$ went from 8-way to 4-way set associative), the overall memory structure is identical to {{\\|Broadwell}}/{{\\|Haswell}}. | ||
| + | |||
| + | <!-- ===================== START IF YOU CHANGE HERE, CHANGE ON KABY LAKE!! ============================= --> | ||
* Cache | * Cache | ||
** L0 µOP cache: | ** L0 µOP cache: | ||
*** 1,536 µOPs, 8-way set associative | *** 1,536 µOPs, 8-way set associative | ||
| − | **** 32 | + | **** 32 sets, 6-µOP line size |
| + | **** statically divided between threads, per core, inclusive with L1I | ||
** L1I Cache: | ** L1I Cache: | ||
| − | *** 32 [[KiB]] 8-way set associative | + | *** 32 [[KiB]], 8-way set associative |
| − | **** 64 B line size | + | **** 64 sets, 64 B line size |
**** shared by the two threads, per core | **** shared by the two threads, per core | ||
** L1D Cache: | ** L1D Cache: | ||
| − | *** 32 KiB 8-way set associative | + | *** 32 KiB, 8-way set associative |
| − | *** 64 B line size | + | *** 64 sets, 64 B line size |
*** shared by the two threads, per core | *** shared by the two threads, per core | ||
*** 4 cycles for fastest load-to-use (simple pointer accesses) | *** 4 cycles for fastest load-to-use (simple pointer accesses) | ||
**** 5 cycles for complex addresses | **** 5 cycles for complex addresses | ||
| − | *** 64 | + | *** 64 B/cycle load bandwidth |
| − | *** 32 | + | *** 32 B/cycle store bandwidth |
*** Write-back policy | *** Write-back policy | ||
** L2 Cache: | ** L2 Cache: | ||
| − | *** | + | *** Unified, 256 KiB, 4-way set associative |
| − | *** 64 B line size | + | *** 1024 sets, 64 B line size |
| + | *** Non-inclusive | ||
*** 12 cycles for fastest load-to-use | *** 12 cycles for fastest load-to-use | ||
| − | *** | + | *** 64 B/cycle bandwidth to L1$ |
*** Write-back policy | *** Write-back policy | ||
** L3 Cache/LLC: | ** L3 Cache/LLC: | ||
| Line 312: | Line 337: | ||
*** Per package | *** Per package | ||
*** Only on the Iris Pro GPUs | *** Only on the Iris Pro GPUs | ||
| − | *** Read: | + | *** Read: 32 B/cycle (@ [[eDRAM]] clock) |
| − | *** Write: | + | *** Write: 32 B/cycle (@ eDRAM clock) |
** System [[DRAM]]: | ** System [[DRAM]]: | ||
*** 2 Channels | *** 2 Channels | ||
| − | *** | + | *** 8 B/cycle/channel (@ memory clock) |
*** 42 cycles + 51 ns latency | *** 42 cycles + 51 ns latency | ||
| − | Skylake TLB consists of dedicated | + | Skylake TLB consists of dedicated L1 TLB for instruction cache (ITLB) and another one for data cache (DTLB). Additionally there is a unified L2 TLB (STLB). |
* TLBs: | * TLBs: | ||
** ITLB | ** ITLB | ||
*** 4 KiB page translations: | *** 4 KiB page translations: | ||
**** 128 entries; 8-way set associative | **** 128 entries; 8-way set associative | ||
| − | **** dynamic | + | **** dynamic partitioning |
*** 2 MiB / 4 MiB page translations: | *** 2 MiB / 4 MiB page translations: | ||
| − | **** 8 entries; fully associative | + | **** 8 entries per thread; fully associative |
**** Duplicated for each thread | **** Duplicated for each thread | ||
** DTLB | ** DTLB | ||
*** 4 KiB page translations: | *** 4 KiB page translations: | ||
**** 64 entries; 4-way set associative | **** 64 entries; 4-way set associative | ||
| − | **** fixed partition | + | **** fixed partition |
*** 2 MiB / 4 MiB page translations: | *** 2 MiB / 4 MiB page translations: | ||
**** 32 entries; 4-way set associative | **** 32 entries; 4-way set associative | ||
| Line 345: | Line 370: | ||
**** 16 entries; 4-way set associative | **** 16 entries; 4-way set associative | ||
**** fixed partition | **** fixed partition | ||
| + | <!-- ===================== END IF YOU CHANGE HERE, CHANGE ON KABY LAKE!! ============================= --> | ||
| + | |||
| + | |||
| + | * '''Note:''' STLB is incorrectly reported as "6-way" by CPUID leaf 2 (EAX=02H). Skylake erratum SKL148 recommends software to simply ignore that value. | ||
== Overview == | == Overview == | ||
| Line 368: | Line 397: | ||
The Skylake [[system on a chip]] consists of a five major components: CPU core, [[last level cache|LLC]], Ring interconnect, System agent, and the [[integrated graphics]]. The image shown on the right, presented by Intel at the Intel Developer Forum in 2015, represents a hypothetical model incorporating all available features Skylake has to offer (i.e. [[superset]] of features). Skylake features an improved core (see [[#Pipeline|§ Pipeline]]) with higher performance per watt and higher performance per clock. The number of cores depends on the model, but mainstream mobile models are typically [[dual-core]] while mainstream desktop models are typically [[quad-core]] with dual-core desktop models still offered for value models (e.g. {{intel|Celeron}}). Accompanying the cores is the LCC ([[last level cache]] or [[L3$]] as seen from the CPU perspective). On mainstream parts the LLC consists of 2 MiB for each core with lower amounts for value models. Connecting the cores together is the ring interconnect. The ring extends to the GPU and the system agent as well. Intel further optimized the ring in Skylake for low-power and higher bandwidth. | The Skylake [[system on a chip]] consists of a five major components: CPU core, [[last level cache|LLC]], Ring interconnect, System agent, and the [[integrated graphics]]. The image shown on the right, presented by Intel at the Intel Developer Forum in 2015, represents a hypothetical model incorporating all available features Skylake has to offer (i.e. [[superset]] of features). Skylake features an improved core (see [[#Pipeline|§ Pipeline]]) with higher performance per watt and higher performance per clock. The number of cores depends on the model, but mainstream mobile models are typically [[dual-core]] while mainstream desktop models are typically [[quad-core]] with dual-core desktop models still offered for value models (e.g. {{intel|Celeron}}). Accompanying the cores is the LCC ([[last level cache]] or [[L3$]] as seen from the CPU perspective). On mainstream parts the LLC consists of 2 MiB for each core with lower amounts for value models. Connecting the cores together is the ring interconnect. The ring extends to the GPU and the system agent as well. Intel further optimized the ring in Skylake for low-power and higher bandwidth. | ||
| − | Accompanying the cores is the {{\\|Gen9}} [[integrated graphics]] unit which comes in a number of different tiers ranging from just 12 execution units (used in the ultra-low power models) all the way the GT4 ({{\\|gen9#Scalability|Gen9 § Pipeline}}) with 72 execution units boasting a peak performance of up to 2,534.4 GFLOPS (HF) / 1,267.2 GFLOPS (SP) on the highest-end workstation model. The two highest-tier models are also accompanied by dedicated [[eDRAM]] ranging from 64 | + | Accompanying the cores is the {{\\|Gen9}} [[integrated graphics]] unit which comes in a number of different tiers ranging from just 12 execution units (used in the ultra-low power models) all the way the GT4 ({{\\|gen9#Scalability|Gen9 § Pipeline}}) with 72 execution units boasting a peak performance of up to 2,534.4 GFLOPS (HF) / 1,267.2 GFLOPS (SP) on the highest-end workstation model. The two highest-tier models are also accompanied by dedicated [[eDRAM]] ranging from 64 to 128 MiB in capacity. The eDRAM is packaged along with the SoC in the same package. |
On the other side is the {{intel|System Agent}} (SA) which houses the various functionality that's not directly related to the cores or graphics. Skylake features an upgraded [[integrated memory controller]] (IMC) with most mainstream models supporting faster memory and dual-channel [[DDR4]]. The SA in Skylake also includes the [[Display Controller]] which now supports higher resolution displays with up to three displays for all mainstream models. | On the other side is the {{intel|System Agent}} (SA) which houses the various functionality that's not directly related to the cores or graphics. Skylake features an upgraded [[integrated memory controller]] (IMC) with most mainstream models supporting faster memory and dual-channel [[DDR4]]. The SA in Skylake also includes the [[Display Controller]] which now supports higher resolution displays with up to three displays for all mainstream models. | ||
| Line 387: | Line 416: | ||
Intel has been experiencing a growing divergence in functionality over the last number of iterations of [[intel/microarchitectures|their microarchitecture]] between their mainstream consumer products and their high-end HPC/server models. Traditionally, Intel has been using the same exact core design for everything from their lowest end value models (e.g. {{intel|Celeron}}) all the way up to the highest-performance enterprise models (e.g. {{intel|Xeon E7}}). While the two have fundamentally different chip architectures, they use the same exact CPU core architecture as the building block. | Intel has been experiencing a growing divergence in functionality over the last number of iterations of [[intel/microarchitectures|their microarchitecture]] between their mainstream consumer products and their high-end HPC/server models. Traditionally, Intel has been using the same exact core design for everything from their lowest end value models (e.g. {{intel|Celeron}}) all the way up to the highest-performance enterprise models (e.g. {{intel|Xeon E7}}). While the two have fundamentally different chip architectures, they use the same exact CPU core architecture as the building block. | ||
| − | This design philosophy has changed with Skylake. In order to better accommodate the different functionalities of each segment without sacrificing features or making unnecessary compromises Intel went with a configurable core. The Skylake core is a single development project, making up a master superset core. The project result in two derivatives: one for servers and one for clients. All mainstream models (from {{intel|Celeron}}/{{intel|Pentium (2009)|Pentium}} all the way up to {{intel|Core i7}}/{{intel|Xeon E3}}) use the client core configuration. Server models (e.g. {{intel|Xeon | + | This design philosophy has changed with Skylake. In order to better accommodate the different functionalities of each segment without sacrificing features or making unnecessary compromises Intel went with a configurable core. The Skylake core is a single development project, making up a master superset core. The project result in two derivatives: {{\\|skylake (server)|one for servers}} and one for clients (the topic of this article). All mainstream models (from {{intel|Celeron}}/{{intel|Pentium (2009)|Pentium}} all the way up to {{intel|Core i7}}/{{intel|Xeon E3}}) use the client core configuration. Server models (e.g. {{intel|Xeon Gold}}/{{intel|Xeon Platinum}}) will be using {{\\|Skylake (server)|the new server configuration}}. |
| − | The | + | The server core is considerably larger than the client one, featuring [[Advanced Vector Extensions 512]] (AVX-512). Skylake servers support what was formerly called AVX3.2 (AVX512F + AVX512CD + AVX512BW + AVX512DQ + AVX512VL). Additionally, those processors Memory Protection Keys for Userspace (PKU), {{x86|PCOMMIT}}, and {{x86|CLWB}}. |
=== Pipeline === | === Pipeline === | ||
| Line 405: | Line 434: | ||
Some µOPs deal with memory access (e.g. [[instruction load|load]] & [[instruction store|store]]). Those will be sent on dedicated scheduler ports that can perform those memory operations. Store operations go to the store buffer which is also capable of performing forwarding when needed. Likewise, Load operations come from the load buffer. Skylake features a dedicated 32 KiB level 1 data cache and a dedicated 32 KiB level 1 instruction cache. It also features a core-private 256 KiB L2 cache that is shared by both of the L1 caches. | Some µOPs deal with memory access (e.g. [[instruction load|load]] & [[instruction store|store]]). Those will be sent on dedicated scheduler ports that can perform those memory operations. Store operations go to the store buffer which is also capable of performing forwarding when needed. Likewise, Load operations come from the load buffer. Skylake features a dedicated 32 KiB level 1 data cache and a dedicated 32 KiB level 1 instruction cache. It also features a core-private 256 KiB L2 cache that is shared by both of the L1 caches. | ||
| − | Each core enjoys a slice of a third level of cache that is shared by all the core. | + | Each core enjoys a slice of a third level of cache that is shared by all the core. For Skylake, there are either [[two cores]] or [[four cores]] connected together on a single chip. |
{{clear}} | {{clear}} | ||
==== Front-end ==== | ==== Front-end ==== | ||
| − | The front-end | + | The front-end is tasked with the challenge of fetching the complex [[x86]] instructions from memory, decoding them, and delivering them to the execution units. In other words, the front end needs to be able to consistently deliver enough [[µOPs]] from the instruction code stream to keep the back-end busy. When the back-end is not being fully utilized, the core is not reaching its full performance. A poorly or under-performing front-end will translate directly to a poorly performing core. This challenge is further complicated by various redirection such as branches and the complex nature of the [[x86]] instructions themselves. |
===== Fetch & pre-decoding ===== | ===== Fetch & pre-decoding ===== | ||
| − | On their first pass, instructions should have already been prefetched from the [[L2 cache]] and into the [[L1 cache]]. The L1 is a 32 [[KiB]], 8-way set associative cache, identical in size and organization to {{intel|microarchitectures|previous generations}}. Skylake fetching is done on a 16-byte fetch window. A window size that has not changed in a number of generations. Up to 16 bytes of code can be fetched each cycle. At this point they are still [[macro-ops]] (i.e. variable-length [[x86]] architectural instruction). Instructions are brought into the pre-decode buffer for initial preparation. | + | On their first pass, instructions should have already been prefetched from the [[L2 cache]] and into the [[L1 cache]]. The L1 is a 32 [[KiB]], 8-way set associative cache, identical in size and organization to {{intel|microarchitectures|previous generations}}. Skylake fetching is done on a 16-byte fetch window. A window size that has not changed in a number of generations. Up to 16 bytes of code can be fetched each cycle. Note that fetcher is shared evenly between the two threads so that each thread gets every other cycle. At this point they are still [[macro-ops]] (i.e. variable-length [[x86]] architectural instruction). Instructions are brought into the pre-decode buffer for initial preparation. |
[[File:skylake fetch.svg|left|300px]] | [[File:skylake fetch.svg|left|300px]] | ||
| − | [[x86]] instructions are complex, variable length, have inconsistent encoding, and may contain multiple operations. At the pre-decode buffer the instructions boundaries get detected and marked. This is a fairly difficult task because each instruction can vary from a single byte all the way up to fifteen. Moreover, determining the length requires inspecting a couple of bytes of the instruction. In addition boundary marking, prefixes are also decoded and checked for various properties such as branches. As with previous microarchitectures, the pre-decoder has a [[throughput]] of 6 [[macro-ops]] per cycle or until all 16 bytes are consumed, whichever happens first. Note that the predecoder will not load a new 16-byte block until the previous block has been fully exhausted. For example, suppose a new chunk was loaded, resulting in 7 instructions. In the first cycle, 6 instructions will be processed and a whole second cycle will be wasted for that last instruction. This will produce the much lower throughput of 3.5 instructions per cycle which is considerably less than optimal. Likewise, if the 16-byte block resulted in just 4 instructions with 1 byte of the 5th instruction received, the first 4 instructions will be processed in the first cycle and a second cycle will be required for the last instruction. This will produce an average throughput of 2.5 instructions per cycle. Note that there is a special case for {{x86|length-changing prefix}} (LCPs) which will incur additional pre-decoding costs. Real code is often less than 4 bytes which usually results in a good rate. | + | [[x86]] instructions are complex, variable length, have inconsistent encoding, and may contain multiple operations. At the pre-decode buffer, the instructions boundaries get detected and marked. This is a fairly difficult task because each instruction can vary from a single byte all the way up to fifteen. Moreover, determining the length requires inspecting a couple of bytes of the instruction. In addition to boundary marking, prefixes are also decoded and checked for various properties such as branches. As with previous microarchitectures, the pre-decoder has a [[throughput]] of 6 [[macro-ops]] per cycle or until all 16 bytes are consumed, whichever happens first. Note that the predecoder will not load a new 16-byte block until the previous block has been fully exhausted. For example, suppose a new chunk was loaded, resulting in 7 instructions. In the first cycle, 6 instructions will be processed and a whole second cycle will be wasted for that last instruction. This will produce the much lower throughput of 3.5 instructions per cycle which is considerably less than optimal. Likewise, if the 16-byte block resulted in just 4 instructions with 1 byte of the 5th instruction received, the first 4 instructions will be processed in the first cycle and a second cycle will be required for the last instruction. This will produce an average throughput of 2.5 instructions per cycle. Note that there is a special case for {{x86|length-changing prefix}} (LCPs) which will incur additional pre-decoding costs. Real code is often less than 4 bytes which usually results in a good rate. |
All of this works along with the branch prediction unit which attempts to guess the flow of instructions. In Skylake, the [[branch predictor]] has also been improved. The branch predictor now has reduced penalty (i.e. lower latency) for wrong direct jump target prediction. Additionally, the predictor in Skylake can inspect further in the byte stream than in previous architectures. The intimate improvements done in the branch predictor were not further disclosed by Intel. | All of this works along with the branch prediction unit which attempts to guess the flow of instructions. In Skylake, the [[branch predictor]] has also been improved. The branch predictor now has reduced penalty (i.e. lower latency) for wrong direct jump target prediction. Additionally, the predictor in Skylake can inspect further in the byte stream than in previous architectures. The intimate improvements done in the branch predictor were not further disclosed by Intel. | ||
| Line 429: | Line 458: | ||
| <pre>cmpjne eax, [mem], loop</pre> | | <pre>cmpjne eax, [mem], loop</pre> | ||
|} | |} | ||
| − | {{see also|Macro-Operation Fusion}} | + | {{see also|macro-operation fusion|l1=Macro-Operation Fusion}} |
| − | The pre-decoded instructions are delivered to the Instruction Queue (IQ). In {{\\|Broadwell}}, the Instruction Queue has been increased to 25 entries duplicated over for each thread (i.e. 50 total entries). It's unclear if that has changed with Skylake. One key optimization the instruction queue does is [[macro-op fusion]]. Skylake can fuse two [[macro-ops]] into a single complex one in a number of cases. In cases where a {{x86|test}} or {{x86|compare}} instruction with a subsequent conditional jump is detected, it will be converted into a single compare-and-branch instruction. Those fused instructions remain fused throughout the entire pipeline and get executed as a single operation by the branch unit thereby saving bandwidth everywhere. Only one such fusion can be performed each cycle. | + | The pre-decoded instructions are delivered to the Instruction Queue (IQ). In {{\\|Broadwell}}, the Instruction Queue has been increased to 25 entries duplicated over for each thread (i.e. 50 total entries). It's unclear if that has changed with Skylake. One key optimization the instruction queue does is [[macro-op fusion]]. Skylake can fuse two [[macro-ops]] into a single complex one in a number of cases. In cases where a {{x86|test}} or {{x86|compare}} instruction with a subsequent conditional jump is detected, it will be converted into a single compare-and-branch instruction. Those fused instructions remain fused throughout the entire pipeline and get executed as a single operation by the branch unit thereby saving bandwidth everywhere. Only one such fusion can be performed during each cycle. |
===== Decoding ===== | ===== Decoding ===== | ||
[[File:skylake decode.svg|right|425px]] | [[File:skylake decode.svg|right|425px]] | ||
| − | Up to | + | Up to four pre-decoded instructions are sent to the decoders each cycle. Like the fetchers, the Decoders alternate between the two thread each cycle. Decoders read in [[macro-operations]] and emit regular, fixed length [[µOPs]]. Skylake represents a big genealogical change from the last couple of microarchitectures. Skylake's pipeline is wider than it predecessors; Skylake adds another [[simple decoder]]. The five decoders are asymmetric; the first one, Decoder 0, is a [[complex decoder]] while the other four are [[simple decoders]]. A simple decoder is capable of translating instructions that emit a single fused-[[µOP]]. By contrast, a [[complex decoder]] can decode anywhere from one to four fused-µOPs. Skylake is now capable of decoding 4 macro-ops per cycle, same as {{\\|Broadwell}}. Overall up to 4 simple instructions can be decoded each cycle with lesser amounts if the complex decoder needs to emit addition µOPs; i.e., for each additional µOP the complex decoder needs to emit, 1 less simple decoder can operate. In other words, for each additional µOP the complex decoder emits, one less decoder is active. |
====== MSROM & Stack Engine ====== | ====== MSROM & Stack Engine ====== | ||
There are more complex instructions that are not trivial to be decoded even by complex decoder. For instructions that transform into more than four µOPs, the instruction detours through the [[microcode sequencer]] (MS) ROM. When that happens, up to 4 µOPs/cycle are emitted until the microcode sequencer is done. During that time, the decoders are disabled. | There are more complex instructions that are not trivial to be decoded even by complex decoder. For instructions that transform into more than four µOPs, the instruction detours through the [[microcode sequencer]] (MS) ROM. When that happens, up to 4 µOPs/cycle are emitted until the microcode sequencer is done. During that time, the decoders are disabled. | ||
| − | [[x86]] has dedicated [[stack machine]] operations. Instructions such as <code>{{x86|PUSH}}</code>, <code>{{x86|POP}}</code>, as well as <code>{{x86|CALL}}</code>, and <code>{{x86|RET}}</code> all operate on the [[stack pointer]] (<code>{{x86|ESP}}</code>). Without any specialized hardware, such operations | + | [[x86]] has dedicated [[stack machine]] operations. Instructions such as <code>{{x86|PUSH}}</code>, <code>{{x86|POP}}</code>, as well as <code>{{x86|CALL}}</code>, and <code>{{x86|RET}}</code> all operate on the [[stack pointer]] (<code>{{x86|ESP}}</code>). Without any specialized hardware, such operations would need to be sent to the back-end for execution using the general purpose ALUs, using up some of the bandwidth and utilizing scheduler and execution units resources. Since {{\\|Pentium M}}, Intel has been making use of a [[Stack Engine]]. The Stack Engine has a set of three dedicated adders it uses to perform and eliminate the stack-updating µOPs (i.e. capable of handling three additions per cycle). Instruction such as <code>{{x86|PUSH}}</code> are translated into a store and a subtraction of 4 from <code>{{x86|ESP}}</code>. The subtraction in this case will be done by the Stack Engine. The Stack Engine sits after the [[instruction decode|decoders]] and monitors the µOPs stream as it passes by. Incoming stack-modifying operations are caught by the Stack Engine. This operation alleviate the burden of the pipeline from stack pointer-modifying µOPs. In other words, it's cheaper and faster to calculate stack pointer targets at the Stack Engine than it is to send those operations down the pipeline to be done by the execution units (i.e., general purpose ALUs). |
===== µOP cache & x86 tax ===== | ===== µOP cache & x86 tax ===== | ||
| + | {{see also|intel/microarchitectures/sandy_bridge_(client)#New_.C2.B5OP_cache_.26_x86_tax|l1=Sandy Bridge § New µOP cache}} | ||
[[File:skylake ucache.svg|right|400px]] | [[File:skylake ucache.svg|right|400px]] | ||
| − | Decoding the variable-length, inconsistent, and complex [[x86]] instructions is a nontrivial task. It's also expensive in terms of performance and power. Therefore, the best way for the pipeline to avoid those things is to simply not decode the instructions. This is the job of the [[µOP cache]] or the Decoded Stream Buffer (DSB). Skylake's µOP cache is organized similarly to previous generations | + | Decoding the variable-length, inconsistent, and complex [[x86]] instructions is a nontrivial task. It's also expensive in terms of performance and power. Therefore, the best way for the pipeline to avoid those things is to simply not decode the instructions. This is the job of the [[µOP cache]] or the Decoded Stream Buffer (DSB). Skylake's µOP cache is organized similarly to all previous generations since its introduction in {{\\|Sandy Bridge}}, however both the bandwidth and the tracking window was increased. The cache is organized into 32 sets of 8 cache lines with each line holding up to 6 µOP for a total of 1,536 µOPs. Since Sandy Bridge, the µOP cache operated on 32-byte fetch windows. In Skylake, the window size has been doubled to 64 bytes. The micro-operation cache is competitively shared between the two threads and can also hold pointers to the microcode. The µOP cache has an average hit rate of 80% or greater. |
| − | A hit in the µOP allows for up to 6 | + | A hit in the µOP allows for up to 6 µOPs (i.e., entire line) per cycle to be sent directly to the Instruction Decode Queue (IDQ), bypassing all the pre-decoding and decoding that would otherwise have to be done. Whereas the legacy decode path works in 16-byte instruction fetch windows, the µOP cache has no such restriction and can deliver 6 µOPs/cycle corresponding to the much bigger 64-byte window. Previously (e.g., {{\\|Broadwell}}), the bandwidth was lower at 4 µOP per cycle. The 1.5x bandwidth increase greatly improves the numbers of µOP that the back-end can take advantage of in the [[out-of-order]] part of the machine. This change attempts to improve instruction rate by alleviating [[bubbles]], however everything is still hard-limited by the [[#Renaming & Allocation|rename and retire]] which puts an absolute ceiling rate of four fused µOPs per cycle. |
===== Allocation Queue ===== | ===== Allocation Queue ===== | ||
| Line 451: | Line 481: | ||
====== µOP-Fusion & LSD ====== | ====== µOP-Fusion & LSD ====== | ||
| − | The IDQ does a number of additional optimizations as it queues instructions. The Loop Stream Detector (LSD) is a mechanism inside the IDQ capable of detecting loops that fit in the IDQ and lock them down. That is, the LSD can stream the same sequence of µOPs directly from the IDQ continuously without any additional [[instruction fetch|fetching]], [[instruction decode|decoding]], or utilizing additional caches or resources. Streaming continues indefinitely until reaching a branch [[mis-prediction]]. | + | The IDQ does a number of additional optimizations as it queues instructions. The Loop Stream Detector (LSD) is a mechanism inside the IDQ capable of detecting loops that fit in the IDQ and lock them down. That is, the LSD can stream the same sequence of µOPs directly from the IDQ continuously without any additional [[instruction fetch|fetching]], [[instruction decode|decoding]], or utilizing additional caches or resources. Streaming continues indefinitely until reaching a branch [[mis-prediction]]. Note that while the LSD is active, the rest of the front-end is effectively disabled. |
The LSD in Skylake can take advantage of the considerably larger IDQ; capable of detecting loops up to 64 µOPs per thread. The LSD is particularly excellent in for many common algorithms that are found in many programs (e.g., tight loops, intensive calc loops, searches, etc..). | The LSD in Skylake can take advantage of the considerably larger IDQ; capable of detecting loops up to 64 µOPs per thread. The LSD is particularly excellent in for many common algorithms that are found in many programs (e.g., tight loops, intensive calc loops, searches, etc..). | ||
| + | |||
| + | * '''NOTE:''' A microcode update appear to have disabled the LSD on client processors. See {{\\|skylake_(server)#Front-end|Skylake (server) § Front-end}}. Also see erratum SKL150. | ||
==== Execution engine ==== | ==== Execution engine ==== | ||
[[File:skylake rob.svg|right|450px]] | [[File:skylake rob.svg|right|450px]] | ||
| − | Skylake's back-end or execution engine deals with the execution of [[out-of-order]] operations. Much of the design is inherited from previous architectures such as {{\\|Haswell}} but has been widened to | + | Skylake's back-end or execution engine deals with the execution of [[out-of-order]] operations. Much of the design is inherited from previous architectures such as {{\\|Haswell}} but has been widened to explore more [[instruction-level parallelism]] opportunities. From the allocation queue instructions are sent to the [[Reorder Buffer]] (ROB) at the rate of up to 6 fused-µOPs each cycle. Skylake's throughput is up by 2 fused-µOPs per cycle from {{\\|Broadwell}} in order to accommodate the wider front-end. |
===== Renaming & Allocation ===== | ===== Renaming & Allocation ===== | ||
| − | Like the front-end, the [[Reorder Buffer]] has been increased to 224 entries, 32 entries more than {{\\|Broadwell}}. It is at this stage that [[architectural registers]] are mapped onto the underlying [[physical registers]]. Other additional bookkeeping tasks are also done at this point such as allocating resources for stores, loads, and determining all possible scheduler ports. Register renaming is also controlled by the [[Register Alias Table]] (RAT) which is used to mark where the data we depend on is coming from (after that value, too, came from an instruction that has previously been renamed). In {{intel|microarchitectures|previous microarchitectures}}, the RAT could handle 4 µOPs each cycle. Intel has not disclosed if that has changed in Skylake but it's possible. If | + | Like the front-end, the [[Reorder Buffer]] has been increased to 224 entries, 32 entries more than {{\\|Broadwell}}. Since each ROB entry holds complete µOPs, in practice 224 entries might be equivalent to as much as 350 µOPs depending on the code being executed (e.g. fused load/stores). It is at this stage that [[architectural registers]] are mapped onto the underlying [[physical registers]]. Other additional bookkeeping tasks are also done at this point such as allocating resources for stores, loads, and determining all possible scheduler ports. Register renaming is also controlled by the [[Register Alias Table]] (RAT) which is used to mark where the data we depend on is coming from (after that value, too, came from an instruction that has previously been renamed). In {{intel|microarchitectures|previous microarchitectures}}, the RAT could handle 4 µOPs each cycle. Intel has not disclosed if that has changed in Skylake but it's possible. If unchanged, Skylake can rename any four registers per cycle. This includes the same register renamed four times in a single cycle. If the rename has not increased in Skylake, some aspects of improvements that were done in the prefetch/decode stages are effectively lost. Note that the ROB still operates on fused µOPs, therefore 4 µOPs can effectively be as high as 8 µOPs. |
It should be noted that there is no special costs involved in splitting up fused µOPs before execution or [[retirement]] and the two fused µOPs only occupy a single entry in the ROB. | It should be noted that there is no special costs involved in splitting up fused µOPs before execution or [[retirement]] and the two fused µOPs only occupy a single entry in the ROB. | ||
| Line 467: | Line 499: | ||
===== Optimizations ===== | ===== Optimizations ===== | ||
| − | Skylake | + | Skylake has a number of optimizations it performs prior to entering the out-of-order and renaming part. Three of those optimizations include [[Move Elimination]] and [[Zeroing Idioms]], and [[Ones Idioms]]. A Move Elimination is capable of eliminating register-to-register moves (including chained moves) prior to bookkeeping at the ROB, allowing those µOPs to save resources and eliminating them entirely. Eliminated moves are zero latency and are entirely removed from the pipeline. This optimization does not always succeed; when it fails, the operands were simply not ready. On average this optimization is almost always successful (upward of 85% in most cases). Move elimination works on all 32- and 64-bit GP integer registers as well as all 128- and 256-bit vector registers. |
{| style="border: 1px solid gray; float: right; margin: 10px; padding: 5px; width: 350px;" | {| style="border: 1px solid gray; float: right; margin: 10px; padding: 5px; width: 350px;" | ||
| [[Zeroing Idiom]] Example: | | [[Zeroing Idiom]] Example: | ||
| Line 473: | Line 505: | ||
| <pre>xor eax, eax</pre> | | <pre>xor eax, eax</pre> | ||
|- | |- | ||
| − | | Not only does this instruction get eliminated at the ROB, but it's actually encoded as just 2 bytes <code>31 C0</code> vs the | + | | Not only does this instruction get eliminated at the ROB, but it's actually encoded as just 2 bytes <code>31 C0</code> vs the 5 bytes for <code>{{x86|mov}} {{x86|eax}}, 0x0</code> which is encoded as <code>b8 00 00 00 00</code>. |
|} | |} | ||
There are some exceptions that Skylake will not optimize, most dealing with [[signedness]]. [[sign extension|sign-extended]] moves cannot be eliminated and neither can zero-extended from 16-bit to 32/64 big registers (note that 8-bit to 32/64 works). Likewise, in the other direction, no moves to 8/16-bit registers can be eliminated. A move of a register to itself is never eliminated. | There are some exceptions that Skylake will not optimize, most dealing with [[signedness]]. [[sign extension|sign-extended]] moves cannot be eliminated and neither can zero-extended from 16-bit to 32/64 big registers (note that 8-bit to 32/64 works). Likewise, in the other direction, no moves to 8/16-bit registers can be eliminated. A move of a register to itself is never eliminated. | ||
| Line 479: | Line 511: | ||
When instructions use registers that are independent of their prior values, another optimization opportunity can be exploited. A second common optimization performed in Skylake around the same time is [[Zeroing Idioms]] elimination. A number common zeroing idioms are recognized and consequently eliminated in much the same way as the move eliminations are performed. Skylake recognizes instructions such as <code>{{x86|XOR}}</code>, <code>{{x86|PXOR}}</code>, and <code>{{x86|XORPS}}</code> as zeroing idioms when the [[source operand|source]] and [[destination operand|destination]] operands are the same. Those optimizations are done at the same rate as renaming during renaming (at 4 µOPs per cycle) and the register is simply set to zero. | When instructions use registers that are independent of their prior values, another optimization opportunity can be exploited. A second common optimization performed in Skylake around the same time is [[Zeroing Idioms]] elimination. A number common zeroing idioms are recognized and consequently eliminated in much the same way as the move eliminations are performed. Skylake recognizes instructions such as <code>{{x86|XOR}}</code>, <code>{{x86|PXOR}}</code>, and <code>{{x86|XORPS}}</code> as zeroing idioms when the [[source operand|source]] and [[destination operand|destination]] operands are the same. Those optimizations are done at the same rate as renaming during renaming (at 4 µOPs per cycle) and the register is simply set to zero. | ||
| − | The [[ones idioms]] is another dependency breaking idiom that can be optimized. In all the various {{x86|PCMPEQ|PCMPEQx}} instructions that perform packed comparison the same register with itself always set all bits to one. On those cases, while the µOP still has to be executed, the instructions may be scheduled as soon as possible because | + | The [[ones idioms]] is another dependency breaking idiom that can be optimized. In all the various {{x86|PCMPEQ|PCMPEQx}} instructions that perform packed comparison the same register with itself always set all bits to one. On those cases, while the µOP still has to be executed, the instructions may be scheduled as soon as possible because the current state of the register need not be known. |
===== Scheduler ===== | ===== Scheduler ===== | ||
[[File:skylake scheduler.svg|right|500px]] | [[File:skylake scheduler.svg|right|500px]] | ||
| − | The scheduler itself was increased by 50%; with up to 97 entries (from 64 in {{\\|Broadwell}}) being competitively shared between the two threads. Skylake continues with a unified design; this is in contrast to designs such as [[AMD]]'s {{amd|Zen|l=arch}} which uses a split design each one holding different types of µOPs. Scheduler includes the two register files for integers and vectors. It's in those [[register files]] that output operand data is | + | The scheduler itself was increased by 50%; with up to 97 entries (from 64 in {{\\|Broadwell}}) being competitively shared between the two threads. Skylake continues with a unified design; this is in contrast to designs such as [[AMD]]'s {{amd|Zen|l=arch}} which uses a split design each one holding different types of µOPs. Scheduler includes the two register files for integers and vectors. It's in those [[register files]] that output operand data is stored. In Skylake, the [[integer]] [[register file]] was also slightly increased from 160 entries to 180. |
| − | At this point µOPs are not longer fused and will be dispatched to the execution units independently. The scheduler holds the µOPs while they wait to be executed. A µOP could be waiting on an operand that has not arrived (e.g., fetched from memory or currently being calculated from another µOPs) or because the execution unit it needs is busy. Once the µOP is ready, | + | At this point µOPs are not longer fused and will be dispatched to the execution units independently. The scheduler holds the µOPs while they wait to be executed. A µOP could be waiting on an operand that has not arrived (e.g., fetched from memory or currently being calculated from another µOPs) or because the execution unit it needs is busy. Once the µOP is ready, it is dispatched through its designated port. The scheduler will send the oldest ready µOP to be executed on each of the eight ports each cycle. |
| − | The scheduler had its ports rearranged to better balance various instructions. For example, divide and [[sqrt]] instructions latency and throughput were improved. The latency and throughput of [[floating point]] ADD, MUL, and FMA were made | + | The scheduler had its ports rearranged to better balance various instructions. For example, divide and [[sqrt]] instructions latency and throughput were improved. The latency and throughput of [[floating point]] ADD, MUL, and FMA were made uniform at 4 cycles with a throughput of 2 µOPs/clock. Likewise the latency of {{x86|AES|AES instructions}} were significantly reduced from 7 cycles down to 4. |
====== Scheduler Ports & Execution Units ====== | ====== Scheduler Ports & Execution Units ====== | ||
| Line 504: | Line 536: | ||
<tr><th rowspan="2">Port 6</th><td>Integer Arithmetic, Logic, Shift</td></tr> | <tr><th rowspan="2">Port 6</th><td>Integer Arithmetic, Logic, Shift</td></tr> | ||
<tr><td>Branch</td></tr> | <tr><td>Branch</td></tr> | ||
| − | <tr><th>Port 2</th><td>Load, | + | <tr><th>Port 2</th><td>Load, AGU</td></tr> |
| − | <tr><th>Port 3</th><td>Load, | + | <tr><th>Port 3</th><td>Load, AGU</td></tr> |
| − | <tr><th>Port 4</th><td>Store, | + | <tr><th>Port 4</th><td>Store, AGU</td></tr> |
| − | <tr><th>Port 7</th><td> | + | <tr><th>Port 7</th><td>AGU</td></tr> |
</table> | </table> | ||
| Line 544: | Line 576: | ||
===== Retirement ===== | ===== Retirement ===== | ||
| − | Once a µOP executes, or in the case of fused µOPs both µOPs have executed, they can be [[retired]]. {{\\|Haswell}} is able to commit up to four fused µOPs each cycle | + | Once a µOP executes, or in the case of fused µOPs both µOPs have executed, they can be [[retired]]. {{\\|Haswell}} is able to commit up to four fused µOPs each cycle per thread. Retirement happens [[in-order]] and releases any used resources such as those used to keep track in the [[reorder buffer]]. Because the allocation queue delivery in Skylake has been increased to 6 µOPs (12 unfused) from previously 4 µOPs (8 unfused) per cycle, the [[SMT]] implementation in Skylake should have some additional efficiency as there's now better chance for higher sustainable retirement rate. |
==== Memory subsystem ==== | ==== Memory subsystem ==== | ||
| − | Skylake has | + | [[File:skylake mem subsystem.svg|right|300px]] |
| + | Skylake's memory subsystem is in charge of the loads and store requests and ordering. Since {{\\|Haswell}}, it's possible to sustain two memory reads (on ports 2 and 3) and one memory write (on port 4) each cycle. Each memory operation can be of any register size up to 256 bits. Skylake memory subsystem has been improved. The store buffer has been increased by 42 entries from {{\\|Broadwell}} to 56 for a total of 128 simultaneous memory operations in-flight or roughly 60% of all µOPs. Special care was taken to reduce the penalty for page-split loads; previously scenarios involving page-split loads were thought to be rarer than they actually are. This was addressed in Skylake with page-split loads are now made equal to other splits loads. Expect page split load penalty down to 5 cycles from 100 cycles in {{\\|Broadwell}}. The average latency to forward a load to store has also been improved and stores that miss in the L1$ generate L2$ requests to the next level cache much earlier in Skylake than before. | ||
| − | The bandwidth from L2 | + | The L2 to L1 bandwidth in Skylake is the same as {{\\|Haswell}} at 64 bytes per cycle in either direction. Note that one operation can be done each cycle; i.e., the L1 can either receive data from the L2 or send data to the Load/Store buffers each cycle, but not both. Latency from L2$ to L3$ has also been decreased from 4 cycles/line to 2 cycles/line. The bandwidth from the level 2 cache to the shared level 3 is 32 bytes per cycle. |
=== eDRAM architectural changes === | === eDRAM architectural changes === | ||
| Line 565: | Line 598: | ||
The new eDRAM changes mean it's no longer architectural - capable of caching any data (including "unreachable memory", display engines, and effectively any memory transfer not bound by software restrictions) and is entirely invisible to software (one exception noted later) in terms of coherency (note that no flushing is thus necessary to maintain coherency), ordering, or other organizational details. For optimal graphics performance, the graphics driver may decide to limit certain memory accesses to only the eDRAM, only the LLC, or in both of them. | The new eDRAM changes mean it's no longer architectural - capable of caching any data (including "unreachable memory", display engines, and effectively any memory transfer not bound by software restrictions) and is entirely invisible to software (one exception noted later) in terms of coherency (note that no flushing is thus necessary to maintain coherency), ordering, or other organizational details. For optimal graphics performance, the graphics driver may decide to limit certain memory accesses to only the eDRAM, only the LLC, or in both of them. | ||
| + | |||
| + | == Configurability == | ||
| + | |||
| + | Skylake features a highly-configurable design, using the same [[macro cells]], Intel can meet the different market segment requirements. | ||
| + | The Skylake family consists out of 5 different actual dies, which can be further segmented by disabling different features, e.g. GT1 graphics are based on GT2 graphics with half the execution units disabled. | ||
| + | |||
| + | <gallery widths=300px heights=150px caption="Physical Layout Breakdown" style="float:right"> | ||
| + | File:2 core lp gt2 skylake.svg|Dual-core die, GT2 GPU, Low Power | ||
| + | File:2 core lp gt3 skylake.svg|Dual-core die, GT3 GPU, Low Power | ||
| + | File:dual core hp gt2 skylake.svg|Dual-core die, GT2 GPU, High Power | ||
| + | File:4 core hp gt2 skylake.svg|Quad-core die, GT2 GPU, High Power | ||
| + | File:4 core hp gt4 skylake.svg|Quad-core die, GT4 GPU, High Power | ||
| + | </gallery> | ||
| + | |||
| + | {{clear}} | ||
| + | |||
| + | == New Technologies == | ||
| + | === Software Guard Extension (SGX) === | ||
| + | {{main|x86/sgx|l1=Intel's Software Guard Extension}} | ||
| + | '''Software Guard Extension''' ('''SGX''') is a new inter-software guard [[x86]] {{x86|extension}} that allows software in user-level mode to create isolated secure environments called "enclaves" for storing data or code. Data and code stored in enclaves are protected from external processes including code executing with higher privileges including the [[operating system]] or a [[hypervisor]] (including all forms of debugging). | ||
| + | |||
| + | === Memory Protection Extension (MPX) === | ||
| + | {{main|x86/mpx|l1=Intel's Memory Protection Extension}} | ||
| + | '''Memory Protection Extension''' ('''MPX''') is a new [[x86]] {{x86|extension}} that offers a hardware-level [[bound checking]] implementation. This extension allows an application to define memory boundaries for allocated memory areas. The processors can then check all proceeding memory accesses against those boundaries to ensure accesses are not [[out of bound]]. A program accessing a boundary-marked buffer out of buffer will generate an exception. | ||
== Power == | == Power == | ||
| Line 573: | Line 630: | ||
Speed Shift effectively eliminates the need for the OS to manages the P-states - though it does have the final say (unless special exceptions occur such as thermal throttling). Intel calls this "autonomous P-state", allowing Speed Shift to kick in in a matter of just ~1 millisecond (whereas the operating system-based p-states control can be as slow as 30 ms). Speed Shift effectively reduces hitting peak frequency in around ~30 ms from over 100 ms (OS-based implementation as before). While Speed Shift is capable of full range shift by default, the operating system can set the minimum QoS, maximum frequency and power/performance hints when desired. The final result should be higher performance and specially higher responsiveness at power constrained form factors. | Speed Shift effectively eliminates the need for the OS to manages the P-states - though it does have the final say (unless special exceptions occur such as thermal throttling). Intel calls this "autonomous P-state", allowing Speed Shift to kick in in a matter of just ~1 millisecond (whereas the operating system-based p-states control can be as slow as 30 ms). Speed Shift effectively reduces hitting peak frequency in around ~30 ms from over 100 ms (OS-based implementation as before). While Speed Shift is capable of full range shift by default, the operating system can set the minimum QoS, maximum frequency and power/performance hints when desired. The final result should be higher performance and specially higher responsiveness at power constrained form factors. | ||
| + | |||
| + | ==== SpeedStep Technology Expansion ==== | ||
| + | {{main|intel/speedstep|l1=SpeedStep Technology}} | ||
| + | Prior to Skylake, SpeedStep had three major domains: [[Cores]], [[Integrated Graphics]], and Coherent Fabric. With Skylake, SpeedStep has been extended to a number of new domains, including the [[System Agent]], Memory, and the [[eDRAM]] I/O. Depending on the bandwidth consumption, SpeedStep can now save energy by reducing frequency on the new domains. | ||
| + | |||
| + | Information from the new domains, including additional thermal skín temperature control information is now supplied to OEMs. | ||
==== Power of System (Psys) ==== | ==== Power of System (Psys) ==== | ||
| Line 585: | Line 648: | ||
** Idle power is reduced further | ** Idle power is reduced further | ||
** C1 state power reduction (improved dynamic capacitance C<sub>dyn</sub>) | ** C1 state power reduction (improved dynamic capacitance C<sub>dyn</sub>) | ||
| + | ** For specific tasks such as streaming, Skylake is capable of powering down certain components of the GPU maintaining power on to the critical components needed for that purpose. | ||
Overall Skylake enjoys better performance/Watt per core for 8x performance/watt over {{\\|Nehalem}}. | Overall Skylake enjoys better performance/Watt per core for 8x performance/watt over {{\\|Nehalem}}. | ||
| + | |||
| + | ==== AVX2 Power Gating ==== | ||
| + | In Skylake, {{x86|AVX2}} has been entirely power-gated. The motive for this change is derived from the fact that applications either make heavy use of AVX2 instructions or don't use it at all. Most programs seldomly use AVX2 for only a small number of instructions. This gave Intel the ability to completely power gate it when the core execute code that does not make use of those instructions. Skylake requires a warm-up time before instructions can execute at full rate (in the order of a couple of 10,000s of cycles depending on frequency). Executing a dummy AVX2 instruction some time prior to heavy AVX2 workloads to prepare the CPU can avoid this. | ||
== Clock domains == | == Clock domains == | ||
Skylake is divided into a number of [[clock domains]], each controlling the clock frequency of their respective unit in the processor. All clock domains are some multiple of the [virtual] bus clock ([[BCLK]]). | Skylake is divided into a number of [[clock domains]], each controlling the clock frequency of their respective unit in the processor. All clock domains are some multiple of the [virtual] bus clock ([[BCLK]]). | ||
| − | * '''BCLK''' - Bus Clock - The system bus interface frequency (once upon a time referred to the actual [[FSB]] speed, it now serves as only a base clock reference for all other clock domains). The | + | * '''BCLK''' - Bus/Base Clock - The system bus interface frequency (once upon a time referred to the actual [[FSB]] speed, it now serves as only a base clock reference for all other clock domains). The base clock is 100 MHz. |
* '''Core Clock''' - The frequency at which the core and the [[L1]]/[[L2]] caches operate at. (Frequency depends on the model and is represented as a multiple of BCLK). | * '''Core Clock''' - The frequency at which the core and the [[L1]]/[[L2]] caches operate at. (Frequency depends on the model and is represented as a multiple of BCLK). | ||
* '''Ring Clock''' - The frequency at which the ring interconnect and [[L3$|LLC]] operate at. Data from/to the individual cores are read/written into the L3 at a rate of 32B/cycle operating at Ring Clock frequency. | * '''Ring Clock''' - The frequency at which the ring interconnect and [[L3$|LLC]] operate at. Data from/to the individual cores are read/written into the L3 at a rate of 32B/cycle operating at Ring Clock frequency. | ||
| Line 599: | Line 666: | ||
[[File:skylake soc clock domain block diagram.svg|850px]] | [[File:skylake soc clock domain block diagram.svg|850px]] | ||
| + | |||
| + | === Overclocking === | ||
| + | {{see also|intel/xmp|l1=Intel's XMP}} | ||
| + | {{oc warning}} | ||
| + | [[File:skylake overclock models chipset.png|right|300px]] | ||
| + | Skylake has improved overclocking capabilities greatly. Overclocking is generally done on [[unlocked]] parts such as the [[Core i7-6700K]], [[Core i5-6600K]], and the mobile [[Core i7-6820HK]] processor. [[Unlocked processors]] should be paired with a [[chipset]] such as the Z170 which offers the most overclocking capabilities such as unlocked BCLK, unlocked core ratio, unlocked memory ratio, unlocked GPU ratio, and voltage controls. | ||
| + | |||
| + | Skylake increased both the overclocking range and ratio granularity, allowing for much more finer overclocking. | ||
| + | |||
| + | <table class="wikitable tr1"> | ||
| + | <tr><th> </th><th>Core i7-3770K</th><th>Core i7-4790K</th><th>Core i7-6700K</th></tr> | ||
| + | <tr><th>Core Ratios Override</th><td>Up to x63</td><td>Up to x80</td><td>Up to x83</td></tr> | ||
| + | <tr><th>Real-time Core Ratio</th><td>✔</td><td>✔</td><td>✔</td></tr> | ||
| + | <tr><th>BCLK Overclocking</th><td>Limited</td><td>100/125/167 MHz</td><td>100+ in 1 MHz increments</td></tr> | ||
| + | <tr><th>MSR Voltage Control</th><td>SVID Extra Voltage</td><td>FIVR SVID Extra Voltage, Voltage Override, Interpolative</td><td>SVID Extra Voltage, Voltage Override, Interpolative</td></tr> | ||
| + | <tr><th>GPU Overclocking</th><td>All Chipsets</td><td>All Chipsets</td><td>All Chipsets</td></tr> | ||
| + | <tr><th>DDR Ratio/Frequency Override and MRC</th><td>Up to 2667 MT/s</td><td>Up to 2667 MT/s</td><td>Up to 4133 MT/s</td></tr> | ||
| + | <tr><th>DDR Granularity Steps</th><td>200/266 MHz</td><td>200/266 MHz</td><td>100/133 MHz</td></tr> | ||
| + | </table> | ||
| + | |||
| + | Note that core ratio has been increased to a [theoretical] x83 multiplier and the coarse-grain ratio was dropped from Skylake allowing a BCLK ratio to have granularity of 1 MHz increments with BCLK frequency of over 200 readily achievable. The FIVR was removed and the voltage control was given back to the motherboard manufacturers; i.e., voltage supplies can be entirely motherboard-controlled. Skylake also bumped the DDR ratio up to 4133 MT/s. | ||
| + | |||
| + | [[File:skylake bclk.png|left|300px]] | ||
| + | In the diagram on the left '''(xC)''' refers to the Core Frequency and is represented as a multiple of BCLK (Core Frequency = BCLK × Core Freq Multiplier up to x83). Likewise '''(xM)''' refers to the memory ratio (up to 4133 MT/s) and '''(xG)''' refers to the Graphics Frequency (pGfx; up to x60). | ||
| + | |||
| + | The BCLK in Skylake has undergone dramatic architectural changes. Considerable effort was dedicated to separating the DMI and PEG (PCIe & Graphics), allowing DMI/PEG to run at their nominal ~100 MHz clock in their own isolated clock domain. This allows BCLK to run at very high speeds (200 MHz+ with upward of 400 MHz+ in LN2). Additionally, while the BCLK is typically supplied by the chipset internal clock generator, it's also possible to supply the clock externally; i.e., motherboard ODMs can potentially take advantage of this and offer their own discrete BCLK control. | ||
| + | |||
| + | [[File:skylake bclk block.png|300px|right]][[File:skylake vrails.png|300px|right]] | ||
| + | Overclocking may involve changing the BCLK frequency. Because a large number of components operate their own [[clock domains]] as a multiple of the BCLK, an increase of 10% to the BCLK frequency will result in an increase of 10% to all other components. On Skylake, the PCIe & DMI sit on their own dedicated reference clock. | ||
| + | |||
| + | The primary voltage rails on Skylake are the V<sub>CORE</sub> = V<sub>RING</sub> which can operate up to 1.52 V (SVID) + V<sub>boost</sub>. V<sub>DDQ</sub> is the typical 1.2 V nominal voltage for [[DDR4]]. V<sub>GT</sub> refers to the graphics processor which can also operate up to 1.52 V (SVID) + V<sub>boost</sub>. Lastly the V<sub>SA</sub> refers to the system agent which has its own voltage control as well. Note that the ring voltage now runs at core voltage; Intel found no harm in overclocking and coupling them together. Additional rails are provided to the manufacturers which they can also expose for overclocking. | ||
| + | |||
| + | {{clear}} | ||
| + | |||
| + | === Voltage Control Modes === | ||
| + | <div style="float: left; margin-right: 20px;">[[File:skylake pcu.png|300px]]</div> | ||
| + | As with all of Intel's latest microarchitectures, Skylake incorporates a Power Control Unit (PCU) which is a dedicated microcontroller on-die in the [[System Agent]]. The PCU runs dedicated embedded firmware and makes dynamic power management decisions based on various global inputs such as temperature, current, power, and workload types. | ||
| + | |||
| + | The system can operate in a number of Voltage Control Modes. The mode chosen dictates how the PCU determines what voltage to use: | ||
| + | |||
| + | <div style="padding-left: 5px; display: table"> | ||
| + | * '''Fused V/f''' - This is the default mode where the PCU will adjust the voltage based on frequency with a voltage cap at the max turbo frequency. | ||
| + | * '''Interpolation (adaptive) V/f''' - In this mode a higher custom voltage point (e.g., 1.5 V) can be set. The PCU will then continue to increase voltage with frequency in a granular way up to the custom point. Likewise, if the frequency drops (e.g. when the system is idle) the voltage is reduced. This mode helps prolong the life of the chip by reducing the voltage when not needed. | ||
| + | * '''Offset V/f''' - An offset mode allows the entire voltage curve to be shifted up by a certain amount. This mode can also be combined with any other mode to increase its entire curve by a certain millivoltage. | ||
| + | * '''Override V/f''' - Override is an extreme overclocking mode whereby the system runs at a fixed voltage the entire time. | ||
| + | </div> | ||
| + | |||
| + | {{clear}} | ||
| + | |||
| + | == New Integration == | ||
| + | ===Image Processing Unit (IPU) === | ||
| + | Skylake integrates a new Image Processing Unit (IPU) on-die. The IPU is an entire imaging subsystem turnkey solution (i.e., [[ISP]] + hardware manipulation functionality), requiring only the external sensor camera. This feature is only available on the [[dual-core]] mobile models. The motivations behind this integration is primarily form factor the integrated IPU allows for higher user-end experience, and further power optimization. | ||
| + | [[File:skylake ipu.png|right|550px]] | ||
| + | The IPU hardware supports: | ||
| + | |||
| + | * Support for up to 4 cameras | ||
| + | ** 13 [[megapixel|MP]] zero [[shutter lag]] 1080p60/2160p30 video capture and imaging and a large array of standardized image processing capabilities. | ||
| + | * Face detection and recognition (smile/blink/group setting) | ||
| + | * Full resolution still capture during video captures | ||
| + | * Multi-stream video captures (up to 2 concurrent streams) | ||
| + | * Panorama | ||
| + | * Burst Captures | ||
| + | * [[HDR]] ultra low-light captures | ||
| + | |||
| + | == Graphics == | ||
| + | {{main|intel/microarchitectures/gen9|l1=Gen9}} | ||
| + | Support for three displays via [[HDMI]] 1.4<ref group=graphics>Note that while there is no native HDMI 2.0 support, Intel did provide somewhat of an awkward solution using an [[LSPCON]] ([[Level Shifter]]/[[Protocol Converter]]) to drive DP to HDMI 1.4 signal + convert HDMI 1.4 to HDMI 2.0. One such solution is the MegaChips MCDP2800.</ref>, [[DisplayPort]] (DP) 1.2, an [[Embedded DisplayPort]] (eDP) 1.4 interfaces. | ||
| + | |||
| + | {| class="wikitable tc2 tc3" | ||
| + | |- | ||
| + | ! colspan="5" | Gen9 [[IGP]] Models !! colspan="9" | Standards | ||
| + | |- | ||
| + | ! rowspan="2" | Name !! rowspan="2" | Execution Units !! rowspan="2" | Tier !! rowspan="2" | Series !! rowspan="2" | eDRAM !! colspan="2" | [[Vulkan]] !! colspan="3" | [[Direct3D]] !! colspan="2" | [[OpenGL]] !! colspan="2" | [[OpenCL]] | ||
| + | |- | ||
| + | | Windows || Linux || Windows || Linux || [[High Level Shading Language|HLSL]] || Windows || Linux || Windows || Linux | ||
| + | |- | ||
| + | | {{intel|HD Graphics 510}} || 12 || GT1 || {{intel|Skylake U|U|l=core}}, {{intel|Skylake S|S|l=core}} || - || rowspan="10" colspan="2" style="text-align: center;" | '''1.0''' || rowspan="10" style="text-align: center;" | '''12''' || rowspan="10" style="text-align: center;" | '''N/A''' || rowspan="10" style="text-align: center;" | '''5.1''' || rowspan="10" style="text-align: center;" | '''4.5''' || rowspan="10" style="text-align: center;" | '''4.5''' || rowspan="10" style="text-align: center;" colspan="2" | '''2.0''' | ||
| + | |- | ||
| + | | {{intel|HD Graphics 515}} || 24 || GT2 || {{intel|Skylake Y|Y|l=core}} || - | ||
| + | |- | ||
| + | | {{intel|HD Graphics 520}} || 24 || GT2 || {{intel|Skylake U|U|l=core}} || - | ||
| + | |- | ||
| + | | {{intel|HD Graphics 530}} || 24 || GT2 || {{intel|Skylake H|H|l=core}}, {{intel|Skylake S|S|l=core}} || - | ||
| + | |- | ||
| + | | {{intel|HD Graphics P530}} || 24 || GT2 || {{intel|Skylake H|H|l=core}} || - | ||
| + | |- | ||
| + | | {{intel|Iris Graphics 540}} || 48 || GT3e || {{intel|Skylake U|U|l=core}} || 64 MiB | ||
| + | |- | ||
| + | | {{intel|Iris Graphics 550}} || 48 || GT3e || {{intel|Skylake U|U|l=core}} || 64 MiB | ||
| + | |- | ||
| + | | {{intel|Iris Pro Graphics P555}} || 48 || GT3e || {{intel|Skylake H|H|l=core}} || 128 MiB | ||
| + | |- | ||
| + | | {{intel|Iris Pro Graphics 580}} || 72 || GT4e || {{intel|Skylake H|H|l=core}} || 128 MiB | ||
| + | |- | ||
| + | | {{intel|Iris Pro Graphics P580}} || 72 || GT4e || {{intel|Skylake H|H|l=core}} || 128 MiB | ||
| + | |} | ||
| + | |||
| + | <references group=graphics /> | ||
| + | ==== Hardware Accelerated Video ==== | ||
| + | {{skylake hardware accelerated video table}} | ||
| + | |||
| + | == Sockets/Platform == | ||
| + | {{intel|Skylake Y|l=core}} and {{intel|Skylake U|U|l=core}} are single-chip solutions. {{intel|Skylake Y|Y|l=core}} chips utilize a 2-die [[multi-chip package]] (MCP) whereas the {{intel|Skylake U|l=core}}'s are either 2 or 3-die MCP configuration. The 3 die chip configuration are for the Iris [[IGP]]s which incorporate an on-package cache (OPC) in addition to the hub. Communication from the CPU to the hub on those chips are done via a lightweight On-Package Interconnect (OPI) interface. {{intel|Skylake S|l=core}} and {{intel|Skylake H|H|l=core}} are a two-chip solution linked together via Intel's standard [[DMI 3.0]] bus interface which utilizes 4 of the CPU's 20 [[PCIe]] 3.0 lanes (having a transfer rate of 8 GT/s per lane). Only {{intel|Skylake S|l=core}} (used on mainstream desktop processors) are not soldered onto the [[motherboard]] and can be interchanged/replaced. | ||
| + | {| class="wikitable" style="text-align: center;" | ||
| + | |- | ||
| + | ! !! Core !! Socket !! Permanent !! Platform !! Chipset !! Bus | ||
| + | |- | ||
| + | | [[File:skylake y (back).png|100px|link=intel/cores/skylake_y]] || {{intel|Skylake Y|l=core}} || {{intel|BGA-1515}} || Yes || 1-chip || rowspan="2" | N/A || rowspan="2" | OPI | ||
| + | |- | ||
| + | | [[File:skylake u (back; standard).png|100px|link=intel/cores/skylake_u]] || {{intel|Skylake U|l=core}} || {{intel|BGA-1356}} || Yes || 1-chip | ||
| + | |- | ||
| + | | [[File:skylake h (back).png|100px|link=intel/cores/skylake_h]] || {{intel|Skylake H|l=core}} || {{intel|BGA-1440}} || Yes || 2-chip || rowspan="2" | {{intel|Sunrise Point}} || rowspan="3" | [[DMI 3.0]] | ||
| + | |- | ||
| + | | rowspan="2" | [[File:skylake s (back).png|100px|link=intel/cores/skylake_s]] || {{intel|Skylake S|l=core}} || {{intel|LGA-1151}} || No || 2-chip | ||
| + | |- | ||
| + | | {{intel|Skylake DT|l=core}} || {{intel|LGA-1151}} || No || 2-chip || Xeon {{intel|Sunrise Point}} | ||
| + | |} | ||
| + | |||
| + | === Packages === | ||
| + | {| class="wikitable" | ||
| + | |- | ||
| + | ! Core !! Die Type !! Package !! Dimensions | ||
| + | |- | ||
| + | | {{intel|Skylake H|l=core}} || 4+2 || rowspan="2" | {{intel|FCBGA-1440}} || rowspan="2" | 42 mm x 28 mm x 1.46 mm | ||
| + | |- | ||
| + | | {{intel|Skylake H|l=core}} || 2+2 | ||
| + | |- | ||
| + | | {{intel|Skylake S|l=core}} || 4+2 || rowspan="2" | {{intel|FCLGA-1151}} || rowspan="2" | 37.5 mm x 37.5 mm x 4.4 mm | ||
| + | |- | ||
| + | | {{intel|Skylake S|l=core}} || 2+2 | ||
| + | |} | ||
== Die == | == Die == | ||
| − | = | + | {{see also|intel/microarchitectures/skylake_(server)#Die|l1=Server Skylake's Die}} |
Skylake desktop and mobile come and [[2 cores|2]] and [[4 cores|4]] cores. Each variant has its own die. One of the most noticeable changes on die is the amount of die space allocated to the [[GPU]]. The major components of the die is: | Skylake desktop and mobile come and [[2 cores|2]] and [[4 cores|4]] cores. Each variant has its own die. One of the most noticeable changes on die is the amount of die space allocated to the [[GPU]]. The major components of the die is: | ||
| Line 609: | Line 807: | ||
* Memory Controller | * Memory Controller | ||
| − | + | === System Agent === | |
The System Agent (SA) contains the Image Processing Unit (IPU), the Display Engine (DE), the I/O bus and various other shared functionality. Note that the mainstream desktop (i.e., [[quad-core]] die) does not have an IPU (The memory controller actually occupies a portion of where it would otherwise be). | The System Agent (SA) contains the Image Processing Unit (IPU), the Display Engine (DE), the I/O bus and various other shared functionality. Note that the mainstream desktop (i.e., [[quad-core]] die) does not have an IPU (The memory controller actually occupies a portion of where it would otherwise be). | ||
| Line 626: | Line 824: | ||
{{clear}} | {{clear}} | ||
| − | + | === Core === | |
Skylake Client models come in either 2x core or 4x core setup. | Skylake Client models come in either 2x core or 4x core setup. | ||
| Line 636: | Line 834: | ||
: [[File:skylake core die (annotated).png|450px]] | : [[File:skylake core die (annotated).png|450px]] | ||
| − | + | === Core Group === | |
| − | Client models come in groups of 2 or 4 cores. (die sizes includes the dark silicon space where the L3 ends). | + | Client models come in groups of 2 or 4 cores. (die sizes includes the [[dark silicon]] space where the L3 ends). |
* 2-cores group: | * 2-cores group: | ||
| − | * ~8.91 mm x ~2.845 mm | + | * ~25.347 mm² die area |
| − | + | ** ~8.91 mm x ~2.845 mm | |
: [[File:skylake 2x core complex die.png|500px]] | : [[File:skylake 2x core complex die.png|500px]] | ||
| Line 647: | Line 845: | ||
* 4-core group | * 4-core group | ||
| − | * ~8.844 mm x 5.694 mm | + | * ~50.354 mm² die area |
| − | + | ** ~8.844 mm x 5.694 mm | |
: [[File:skylake 4x core complex die.png|500px]] | : [[File:skylake 4x core complex die.png|500px]] | ||
| − | + | === Integrated Graphics === | |
| − | |||
The [[integrated graphics]] takes up the largest portion of the die. The normal [[dual-core]] and [[quad-core]] dies come with 24 EU {{\\|Gen9.5}} GPU (with 12 units disabled on the low end models). | The [[integrated graphics]] takes up the largest portion of the die. The normal [[dual-core]] and [[quad-core]] dies come with 24 EU {{\\|Gen9.5}} GPU (with 12 units disabled on the low end models). | ||
| Line 662: | Line 859: | ||
{{clear}} | {{clear}} | ||
| − | + | === Dual-core === | |
Die shot of the [[dual-core]] {{\\|Gen9|GT2}} Skylake processors. Those are found in mobile models, and entry-level/budget processors: | Die shot of the [[dual-core]] {{\\|Gen9|GT2}} Skylake processors. Those are found in mobile models, and entry-level/budget processors: | ||
| Line 668: | Line 865: | ||
* 11 metal layers | * 11 metal layers | ||
* ~1,750,000,000 transistors | * ~1,750,000,000 transistors | ||
| − | * ~9. | + | * ~9.19 mm x ~11.08 mm |
| − | * ~ | + | * ~101.83 mm² die size |
* 2 CPU cores + 24 GPU EUs | * 2 CPU cores + 24 GPU EUs | ||
| Line 677: | Line 874: | ||
: [[File:skylake (dual core) (annotated).png|650px]] | : [[File:skylake (dual core) (annotated).png|650px]] | ||
| − | + | === Quad-core === | |
| − | Die shot of the [[quad-core]] {{\\|Gen9|GT2}} | + | Die shot of the [[quad-core]] {{\\|Gen9|GT2}} Skylake processors. Those are found in almost all mainstream desktop processors. |
* [[14 nm process]] | * [[14 nm process]] | ||
* 11 metal layers | * 11 metal layers | ||
| − | * ~122 mm² die size | + | * ~9.19 mm x ~13.31 mm |
| + | * ~122.3 mm² die size | ||
* 4 CPU cores + 24 GPU EUs | * 4 CPU cores + 24 GPU EUs | ||
| − | : [[File:skylake (quad-core).png|650px]] | + | : [[File:skylake (quad-core).png|class=wikichip_ogimage|650px]] |
: [[File:skylake (quad-core) (annotated).png|650px]] | : [[File:skylake (quad-core) (annotated).png|650px]] | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
== All Skylake Chips == | == All Skylake Chips == | ||
| Line 1,298: | Line 894: | ||
created and tagged accordingly. | created and tagged accordingly. | ||
| − | Missing a chip? please dump its name here: | + | Missing a chip? please dump its name here: https://en.wikichip.org/wiki/WikiChip:wanted_chips |
--> | --> | ||
| − | <table class=" | + | {{comp table start}} |
| − | <tr | + | <table class="comptable sortable tc6 tc7 tc20 tc21 tc22 tc23 tc24 tc25"> |
| − | + | <tr class="comptable-header"><th> </th><th colspan="24">List of Skylake Processors</th></tr> | |
| − | <tr><th> | + | <tr class="comptable-header"><th> </th><th colspan="9">Main processor</th><th colspan="4">{{intel|Turbo Boost}}</th><th>Mem</th><th colspan="3">IGP</th><th colspan="7">Major Feature Diff</th></tr> |
| − | {{#ask: [[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Skylake]] | + | {{comp table header 1|cols=Launched, Price, Family, Core Name, Cores, Threads, %L2$, %L3$, TDP, %Frequency, 1 Core, 2 Cores, 3 Cores, 4 Cores, Max Mem, GPU, %Frequency, Turbo, Turbo, SMT, AVX2, TXT, TSX, vPro}} |
| + | <tr class="comptable-header comptable-header-sep"><th> </th><th colspan="25">[[Uniprocessors]]</th></tr> | ||
| + | {{#ask: [[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Skylake]] [[max cpu count::1]] | ||
|?full page name | |?full page name | ||
|?model number | |?model number | ||
| − | |? | + | |?first launched |
| − | |? | + | |?release price |
| + | |?microprocessor family | ||
|?core name | |?core name | ||
| − | |? | + | |?core count |
| − | |? | + | |?thread count |
| + | |?l2$ size | ||
| + | |?l3$ size | ||
|?tdp | |?tdp | ||
|?base frequency#GHz | |?base frequency#GHz | ||
| − | |?max memory# | + | |?turbo frequency (1 core)#GHz |
| + | |?turbo frequency (2 cores)#GHz | ||
| + | |?turbo frequency (3 cores)#GHz | ||
| + | |?turbo frequency (4 cores)#GHz | ||
| + | |?max memory#GiB | ||
|?integrated gpu | |?integrated gpu | ||
|?integrated gpu base frequency | |?integrated gpu base frequency | ||
|?integrated gpu max frequency | |?integrated gpu max frequency | ||
| + | |?has intel turbo boost technology 2_0 | ||
| + | |?has simultaneous multithreading | ||
| + | |?has advanced vector extensions 2 | ||
| + | |?has intel trusted execution technology | ||
| + | |?has transactional synchronization extensions | ||
| + | |?has intel vpro technology | ||
|format=template | |format=template | ||
| − | |template=proc table | + | |template=proc table 3 |
|searchlabel= | |searchlabel= | ||
| − | |userparam= | + | |sort=microprocessor family, model number |
| + | |order=asc,asc | ||
| + | |userparam=26:21 | ||
|mainlabel=- | |mainlabel=- | ||
| + | |limit=200 | ||
}} | }} | ||
| − | + | {{comp table count|ask=[[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Skylake]] [[max cpu count::1]]}} | |
</table> | </table> | ||
| + | {{comp table end}} | ||
== References == | == References == | ||
| Line 1,332: | Line 947: | ||
* Efraim Rotem, Senior Principal Engineer, Lead Client Power Architect, 2015 IDF in San Francisco, Session ARCS001 ("Intel® Architecture, Code Name Skylake Deep Dive: A New Architecture to Manage Power Performance and Energy Efficiency"), August 18, 2015 | * Efraim Rotem, Senior Principal Engineer, Lead Client Power Architect, 2015 IDF in San Francisco, Session ARCS001 ("Intel® Architecture, Code Name Skylake Deep Dive: A New Architecture to Manage Power Performance and Energy Efficiency"), August 18, 2015 | ||
* David Blythe, Intel Fellow and Chief Graphics Software Architect, 2015 IDF in San Francisco, Session SPCS003 ("Technology Insight: Next Generation Intel® Processor Graphics Architecture, Code Name Skylake"), August 18, 2015 | * David Blythe, Intel Fellow and Chief Graphics Software Architect, 2015 IDF in San Francisco, Session SPCS003 ("Technology Insight: Next Generation Intel® Processor Graphics Architecture, Code Name Skylake"), August 18, 2015 | ||
| + | * Dan Ragland, Overclocking System Architect, 2015 IDF, in San Francisco, Session RPCS001 ("Overclocking 6th Generation Intel® Core™ Processors!"), August 18, 2015 | ||
* Jack Doweck, Intel, Hot Chips 28, 2016 | * Jack Doweck, Intel, Hot Chips 28, 2016 | ||
* Fayneh, Eyal, et al. "4.1 14nm 6th-generation Core processor SoC with low power consumption and improved performance." Solid-State Circuits Conference (ISSCC), 2016 IEEE International. IEEE, 2016. | * Fayneh, Eyal, et al. "4.1 14nm 6th-generation Core processor SoC with low power consumption and improved performance." Solid-State Circuits Conference (ISSCC), 2016 IEEE International. IEEE, 2016. | ||
| Line 1,341: | Line 957: | ||
* [[:File:6th Gen Intel® Core™ vPro™ Processor Family Product Brief.pdf|6th Gen Intel® Core™ vPro™ Processor Family Product Brief]] | * [[:File:6th Gen Intel® Core™ vPro™ Processor Family Product Brief.pdf|6th Gen Intel® Core™ vPro™ Processor Family Product Brief]] | ||
* [[:File:6th Generation Intel® Core™ Desktop Processors i7-6700K and i5-6600K Product Brief.pdf|6th Generation Intel® Core™ Desktop Processors i7-6700K and i5-6600K Product Brief]] | * [[:File:6th Generation Intel® Core™ Desktop Processors i7-6700K and i5-6600K Product Brief.pdf|6th Generation Intel® Core™ Desktop Processors i7-6700K and i5-6600K Product Brief]] | ||
| + | |||
| + | |||
| + | * [[:File:Overclocking 6th Generation Intel® Core™ Processors.pdf|Overclocking 6th Generation Intel® Core™ Processors]] | ||
| + | * [[:File:Technology Insight Intel’s Next Generation Microarchitecture Code Name Skylake.pdf|Technology Insight Intel’s Next Generation Microarchitecture Code Name Skylake]] | ||
| + | * [[:File:Intel Architecture, Code Name Skylake Deep Dive- A New Architecture to Manage Power Performance and Energy Efficiency.pdf|Intel Architecture, Code Name Skylake Deep Dive- A New Architecture to Manage Power Performance and Energy Efficiency]] | ||
== See also == | == See also == | ||
* AMD {{amd|Zen}} | * AMD {{amd|Zen}} | ||
Latest revision as of 01:42, 16 November 2024
| Edit Values | |
| Skylake (client) µarch | |
| General Info | |
| Arch Type | CPU |
| Designer | Intel |
| Manufacturer | Intel |
| Introduction | August 5, 2015 |
| Process | 14 nm |
| Core Configs | 2, 4 |
| Pipeline | |
| Type | Superscalar, Superpipeline |
| OoOE | Yes |
| Speculative | Yes |
| Reg Renaming | Yes |
| Stages | 14-19 |
| Instructions | |
| ISA | x86-64 |
| Cache | |
| L1I Cache | 32 KiB/core 8-way set associative |
| L1D Cache | 32 KiB/core 8-way set associative |
| L2 Cache | 256 KiB/core 4-way set associative |
| L3 Cache | 2 MiB/core Up to 16-way set associative |
| Side Cache | 128 MiB/package on Iris Pro GPUs only |
| Cores | |
| Core Names | Skylake Y, Skylake U, Skylake H, Skylake S, Skylake DT |
| Succession | |
| Contemporary | |
| Skylake (server) | |
Skylake (SKL) Client Configuration is Intel's successor to Broadwell, a 14 nm process microarchitecture for mainstream workstations, desktops, and mobile devices. Skylake succeeded the short-lived Broadwell which experienced severe delays. Skylake is the "Architecture" phase as part of Intel's PAO model. The microarchitecture was developed by Intel's R&D center in Haifa, Israel.
For desktop and mobile, Skylake is branded as 6th Generation Intel Core i3, Core i5, Core i7 processors. For workstations it's branded as Xeon E3 v5.
Contents
- 1 Codenames
- 2 Brands
- 3 Release Dates
- 4 Process Technology
- 5 Compatibility
- 6 Compiler support
- 7 Architecture
- 8 Overview
- 9 Core
- 10 Configurability
- 11 New Technologies
- 12 Power
- 13 Clock domains
- 14 New Integration
- 15 Graphics
- 16 Sockets/Platform
- 17 Die
- 18 All Skylake Chips
- 19 References
- 20 Documents
- 21 See also
Codenames[edit]
- See also: Server Skylake's Codenames
| Core | Abbrev | Platform | Target |
|---|---|---|---|
| Skylake Y | SKL-Y | 2-in-1s detachable, tablets, and computer sticks | |
| Skylake U | SKL-U | Light notebooks, portable All-in-Ones (AiOs), Minis, and conference room | |
| Skylake H | SKL-H | Ultimate mobile performance, mobile workstations | |
| Skylake S | SKL-S | Desktop performance to value, AiOs, and minis | |
| Skylake DT | SKL-DT | Greenlow | Workstations & entry-level servers |
Brands[edit]
- See also: Server Skylake's Brands
Intel released Skylake under 6 main brand families for mainstream workstations, desktops, and mobile.
| Logo | Family | General Description | Differentiating Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Cores | HT | AVX | AVX2 | TBT | ECC | ||||
 |
Celeron | Entry-level Budget | dual | ✘ | ✘ | ✘ | ✘ | ✘ | |
| Entry-level Budget (Embedded) | ✘ | ✘ | ✘ | ✘ | ✔ | ||||
 |
Pentium | Budget (Mobile) | dual | ✔ | ✘ | ✘ | ✘ | ✘ | |
| Budget (Desktop) | ✘ | ✘ | ✘ | ✘ | ✔ | ||||
| |
Core i3 | Low-end Performance | dual | ✔ | ✔ | ✔ | ✘ | ✘ | |
| Low-end Performance (Desktop/Embedded) |
✔ | ✔ | ✔ | ✘ | ✔ | ||||
| |
Core i5 | Mid-range Performance | dual | ✔ | ✔ | ✔ | ✔ | ✘ | |
| quad | ✘ | ✔ | ✔ | ✔ | ✘ | ||||
| |
Core i7 | High-end Performance | dual | ✔ | ✔ | ✔ | ✔ | ✘ | |
| quad | ✔ | ✔ | ✔ | ✔ | ✘ | ||||
| |
Xeon E3 | Workstation/dense servers | quad | ✔/✘ | ✔ | ✔ | ✔ | ✔ | |
Release Dates[edit]
Skylake was first demonstrated at the 2014 Intel Developer Forum in San Francisco on September 9 with the goals of launching in the second half of 2015.
Process Technology[edit]
- Main article: Broadwell § Process Technology
Skylake uses the same 14 nm process used for the Broadwell microarchitecture for all mainstream consumer parts (Core, Celeron, et al).
Compatibility[edit]
| Vendor | OS | Version | Notes |
|---|---|---|---|
| Microsoft | Windows | Windows Vista | No Support |
| Windows 7 | Support ends July 2018 | ||
| Windows 8.1 | |||
| Windows 10 | Support | ||
| Linux | Linux | Kernel 3.19 | Initial Support (MPX support) |
| Chromium | Chromium | Support | |
| Wind River | VxWorks | VxWorks 5.5? | Support |
Compiler support[edit]
| Compiler | Arch-Specific | Arch-Favorable |
|---|---|---|
| ICC | -march=skylake |
-mtune=skylake
|
| GCC | -march=skylake |
-mtune=skylake
|
| LLVM | -march=skylake |
-mtune=skylake
|
| Visual Studio | /arch:AVX2 |
/tune:skylake
|
CPUID[edit]
| Core | Extended Family |
Family | Extended Model |
Model |
|---|---|---|---|---|
| Y/U | 0 | 0x6 | 0x4 | 0xE |
| Family 6 Model 78 | ||||
| DT/H/S | 0 | 0x6 | 0x5 | 0xE |
| Family 6 Model 94 | ||||
Architecture[edit]
Overall Skylake builds upon Intel's previous microarchitecture, Broadwell, but includes a wider and more beefed up front end, more optimized execution engine, and numerous other enhancements. Intel designed Skylake to encompass a wide range of devices and applications with a large emphasis on mobile with models ranging from as low as 4.5 W to as high as 100 W.
Key changes from Broadwell[edit]

- 8x performance/watt over Nehalem (Up from 3.5x in Haswell)
- Mainstream chipset
- Lynx Point → Sunrise Point
- Bus/Interface to Chipset
- DMI 3.0 (from 2.0)
- Skylake S and Skylake H cores, connected by 4-lane DMI 3.0
- Skylake Y and Skylake U cores have chipset in the same package (simplified OPIO)
- Increase in transfer rate from 5.0 GT/s to 8.0 GT/s (~3.93GB/s up from 2GB/s) per lane
- Limits motherboard trace design to 7 inches max from the CPU to chipset (down from 8)
- DMI 3.0 (from 2.0)
- PCIe & DMI upgraded to Gen3
- More I/O (configurable as PCIe/SATA/USB3)
- Lower-power I/O (eMMC, UFS, SDXC)
- CSI-2 for the integrated IPU (mobile SKUs)
- Intel Sensor Solution Hub integration
- Larger Line Fill Buffer?
- System Agent
- New Image Processing Unit (IPU)
- Incorporates an image signal processor (ISP)
- Mobile client models only
- Can now have its own variable voltage and frequency
- New Image Processing Unit (IPU)
- Core
- Front End
- Allocation Queue (IDQ)
- Wider Allocation path (5-way, up from 4-way in broadwell)
- Larger delivery (6 µOPs, up from 4)
- 2.28x larger buffer (64/thread, up from 56)
- Partitioned for each active threads (from unified)
- Improved branch prediction unit
- reduced penalty for wrong direct jump target
- No specifics were disclosed
- µOP Cache
- instruction window is now 64 Bytes (from 32)
- 1.5x bandwidth (6 µOPs/cycle, up from 4)
- Allocation Queue (IDQ)
- Execution Engine
- Larger re-order buffer (224 entries, up from 192)
- Larger scheduler (97 entries, up from 64)
- Larger Integer Register File (180 entries, up from 168)
- Larger Retire (4 µOPs/cycle/thread, up from 4 µOPs/cycle/core)?
- Memory Subsystem
- Larger store buffer (56 entries, up from 42)
- L2$ was changed from 8-way to 4-way set associative
- Page split load penalty reduced 20-fold
- Larger Write-back buffer
- Front End
- Memory
- Support for faster DDR-2400 memory
- L3$ re-gained 512 KiB/core (See §eDRAM architectural changes for the reason)
- A new coherent cache fabric implementation
- doubles the throughput of the last level cache (LLC, L3$ in this case) miss handling
- 50% improvement in bandwidth/watt
- new eDRAM cache architecture for higher bandwidth
- TLBs
- ITLB
- 4 KiB page translations was changed from 4-way to 8-way associative
- STLB
- 4 KiB + 2 MiB page translations was changed from 6-way to 12-way associative
- ITLB
- Electrical
- The fully integrated voltage regulator (FIVR) is moved back to the motherboard
- Originally intended to be a cost-cutting measure by moving the FIVR on-die as well as making it more efficient, the move resulted in unintentionally making the FIVR the limiting factor when it came to overclocking.
- DMI/PEG are now on a discrete clock domain with BCLK sitting on its own domain with full-range granularity (1 MHz intervals)
- The fully integrated voltage regulator (FIVR) is moved back to the motherboard
- Testability
- New support for Direct Connect Interface (DCI), a new debugging transport protocol designed to allow debugging of closed cases (e.g. laptops, embedded) by accessing things such as JTAG through any USB 3 port.
- Gen 9 GPUs
- Improved underlying implementation of the memory QoS for higher resolution displays and the integrated image signal processor (ISP)
- Allow for higher concurrent bandwidth
- Skylake retires VGA support, multi-monitor support for up to 3 displays via HDMI 1.4, DP 1.2, and eDP 1.3 interfaces.
- Direct X 12, OpenCL 2.0, OpenGL 4.4
- Up to 24 EUs GT2 (same as Haswell); 48 EUs for GT3, and up to 72 EUs on Iris Pro Graphics
- 384 GFLOPS @ 1 GHz (GT2)
- Improved underlying implementation of the memory QoS for higher resolution displays and the integrated image signal processor (ISP)
CPU changes[edit]
- Like Haswell, most general purpose ALU operations execute at up to 4 ops/cycle for 8, 32 and 64-bit registers. (16-bit throughput varies per op, can be 4, 3.5 or 2 op/cycle).
- ADC and SBB are single uop (like Broadwell), down from 2 in Haswell. Throughput of 1 op/cycle, or 2/c if not bottlenecked by one long dependency, same as Haswell.
- Vector moves have throughput of 4 op/cycle (improved move elimination for nothing-but-move microbenchmarks)
- vPCMPGTx on the same register is recognized as a zeroing idiom (4 ops/cycle, no execution unit) like vpXORxx and vPSUBx zeroing.
- Vector ALU ops are often "standardized" to latency of 4. for example, vADDPS and vMULPS used to have L of 3 and 5 in HSW, or both 3 in BDW, now both are 4.
- Fused multiply-add ops have latency of 4 and throughput of 0.5 op/cycle, improved from 5 cycle latency.
- Throughput of vADDps, vSUBps, vCMPps, vMAXps, their scalar and double analogs is increased to 2 op/cycle. Lower latency SIMD FP-add unit on port 1 removed in favour of running all FP math on the FMA units.
- Throughput of vPSLxx and vPSRxx with immediate (i.e. fixed vector shifts) is increased to 2 op/cycle, along with VPSxxVx variable shifts.
- Throughput of vANDps, vANDNps, vORps, vXORps, their scalar and double analogs, vPADDx, vPSUBx is increased to 3 op/cycle.
- vDIVPD, vSQRTPD have approximately twice as good throughput: from 8 to 4 and from 28 to 12 cycles/op.
- Throughput of some MMX ALU ops (such as PAND mm1, mm2) is decreased to 2 or 1 op/cycle (users are expected to use wider SSE/AVX registers instead).
New instructions[edit]
- See also: Server Skylake's New instructions
Skylake introduced a number of new instructions:
-
SGX1- Software Guard Extensions, Version 1 -
MPX-Memory Protection Extensions -
XSAVEC- Save processor extended states with compaction to memory -
XSAVES- Save processor supervisor-mode extended states to memory. -
CLFLUSHOPT- Flush & Invalidates memory operand and its associated cache line (All L1/L2/L3 etc..)
Block Diagram[edit]
Entire SoC Overview (dual)[edit]
.svg)
Entire SoC Overview (quad)[edit]

Individual Core[edit]

Gen9[edit]
See Gen9#Gen9.
Memory Hierarchy[edit]
Other than a few organizational changes (e.g. L2$ went from 8-way to 4-way set associative), the overall memory structure is identical to Broadwell/Haswell.
- Cache
- L0 µOP cache:
- 1,536 µOPs, 8-way set associative
- 32 sets, 6-µOP line size
- statically divided between threads, per core, inclusive with L1I
- 1,536 µOPs, 8-way set associative
- L1I Cache:
- 32 KiB, 8-way set associative
- 64 sets, 64 B line size
- shared by the two threads, per core
- 32 KiB, 8-way set associative
- L1D Cache:
- 32 KiB, 8-way set associative
- 64 sets, 64 B line size
- shared by the two threads, per core
- 4 cycles for fastest load-to-use (simple pointer accesses)
- 5 cycles for complex addresses
- 64 B/cycle load bandwidth
- 32 B/cycle store bandwidth
- Write-back policy
- L2 Cache:
- Unified, 256 KiB, 4-way set associative
- 1024 sets, 64 B line size
- Non-inclusive
- 12 cycles for fastest load-to-use
- 64 B/cycle bandwidth to L1$
- Write-back policy
- L3 Cache/LLC:
- Up to 2 MiB Per core, shared across all cores
- Up to 16-way set associative
- Inclusive
- 64 B line size
- Write-back policy
- Per each core:
- Read: 32 B/cycle (@ ring clock)
- Write: 32 B/cycle (@ ring clock)
- 42 cycles for fastest load-to-use
- Side Cache:
- System DRAM:
- 2 Channels
- 8 B/cycle/channel (@ memory clock)
- 42 cycles + 51 ns latency
- L0 µOP cache:
Skylake TLB consists of dedicated L1 TLB for instruction cache (ITLB) and another one for data cache (DTLB). Additionally there is a unified L2 TLB (STLB).
- TLBs:
- ITLB
- 4 KiB page translations:
- 128 entries; 8-way set associative
- dynamic partitioning
- 2 MiB / 4 MiB page translations:
- 8 entries per thread; fully associative
- Duplicated for each thread
- 4 KiB page translations:
- DTLB
- 4 KiB page translations:
- 64 entries; 4-way set associative
- fixed partition
- 2 MiB / 4 MiB page translations:
- 32 entries; 4-way set associative
- fixed partition
- 1G page translations:
- 4 entries; 4-way set associative
- fixed partition
- 4 KiB page translations:
- STLB
- 4 KiB + 2 MiB page translations:
- 1536 entries; 12-way set associative
- fixed partition
- 1 GiB page translations:
- 16 entries; 4-way set associative
- fixed partition
- 4 KiB + 2 MiB page translations:
- ITLB
- Note: STLB is incorrectly reported as "6-way" by CPUID leaf 2 (EAX=02H). Skylake erratum SKL148 recommends software to simply ignore that value.
Overview[edit]
Skylake inherits much of the Core design philosophy which was enhanced significantly over the past number of architectures. Skylake, like its predecessor Broadwell, is also a dual-threaded and complex out-of-order pipeline. Skylake which builds on Broadwell incorporates large number of enhancements that has improved performance and efficiency in order to cover a large spectrum of devices from ultra-low power to high-performance computing. Additionally, a large number of improvements were done to the integrated graphics and multimedia capabilities as well as a new set of security technologies were introduced.
Design goals & new goals[edit]

Skylake tries to address 4 major design goals: Scalability, Performance, Power, and Media & Graphics. Skylake started out as a "traditional client product" when initial design goals and development started back in 2010. At that time, Skylake was expected to cover products ranging from thin-and-lights all the way up to desktops. This translated to roughly 3x TDP scale and 2x form factor between the smallest and biggest models. With the introduction of Ultralight, Skylake design goals were extended to a new class of smaller form factors (down to 15 W). Skylake design goals were later further extended to more mobility segments and even smaller form factors. The final end result is a microarchitecture that now spans 20-fold TDP scale (from 3.5 W all the way to 80 W+) and up to 4-fold form factor between the lowest power model and the highest performance model. Intel claims that Skylake also succeeded in reducing power by 40-60% during important workloads such as video, graphics, and idle power which especially affect models where battery life is absolutely critical.
It's interesting to note that Skylake's end result managed to overlap and to some degree exceed Intel's own ultra-low power (ULP) series of microarchitectures (i.e. Silvermont and Goldmont).
Product Development Vectors:
- Form factor reduction - Emphasis was placed on reduction of form factor which includes both actual die size and package size.
- Platform minimization - Effort was spent on reducing the overall platform size include reduction of system board size, components, and power.
- Better life scenario power reduction - (mobile segment) The reduction of power during critical workloads such as video playback, video conferencing, and various other multimedia applications where the CPU itself is mostly idle.
- IA performance - Improvements to both power and performance of the CPU core
- IGP performance - Improvement to both power and performance of the GPU
- New Security technology - Better protection against hardware and software attacks
SoC design[edit]
.png)
The Skylake system on a chip consists of a five major components: CPU core, LLC, Ring interconnect, System agent, and the integrated graphics. The image shown on the right, presented by Intel at the Intel Developer Forum in 2015, represents a hypothetical model incorporating all available features Skylake has to offer (i.e. superset of features). Skylake features an improved core (see § Pipeline) with higher performance per watt and higher performance per clock. The number of cores depends on the model, but mainstream mobile models are typically dual-core while mainstream desktop models are typically quad-core with dual-core desktop models still offered for value models (e.g. Celeron). Accompanying the cores is the LCC (last level cache or L3$ as seen from the CPU perspective). On mainstream parts the LLC consists of 2 MiB for each core with lower amounts for value models. Connecting the cores together is the ring interconnect. The ring extends to the GPU and the system agent as well. Intel further optimized the ring in Skylake for low-power and higher bandwidth.
Accompanying the cores is the Gen9 integrated graphics unit which comes in a number of different tiers ranging from just 12 execution units (used in the ultra-low power models) all the way the GT4 (Gen9 § Pipeline) with 72 execution units boasting a peak performance of up to 2,534.4 GFLOPS (HF) / 1,267.2 GFLOPS (SP) on the highest-end workstation model. The two highest-tier models are also accompanied by dedicated eDRAM ranging from 64 to 128 MiB in capacity. The eDRAM is packaged along with the SoC in the same package.
On the other side is the System Agent (SA) which houses the various functionality that's not directly related to the cores or graphics. Skylake features an upgraded integrated memory controller (IMC) with most mainstream models supporting faster memory and dual-channel DDR4. The SA in Skylake also includes the Display Controller which now supports higher resolution displays with up to three displays for all mainstream models.
The SA also incorporates up to 20 lanes of PCIe with lesser amounts depending on the model. Of the 20 lanes, x16 PCIe lanes are offered for an external dedicated graphics hookup with the other four lanes reserved for communication with the southbridge chipset over Intel's new proprietary DMI 3.0 bus. The upgrade from DMI 2.0 (used in previous architectures) to 3.0 increased the bandwidth by 60% (8.0 GT/s from 5). For some models where form factor is exceptionally critical, such as those used for ultralight device, the chipset is packaged along with the SoC utilizing an on-package-interconnect (OPI) instead.
The last component of the System Agent and an entirely new addition in Skylake is the Image Processing Unit (IPU) which incorporates an image signal processor (ISP) on-die. The IPU is only available on mobile models and was added in order to improve and streamline (i.e. form factor and consistent set of features and quality) the implementation and performance of tablets and 2-in-1s. Previously this would require the assistance of an external component and the implementations varied by designer.
Core[edit]
Overview[edit]
Skylake shares most of the development vectors with its predecessor while introducing a one of new constraint. The overall goals were:
- Performance improvements - the traditional way of milking more performance by increasing the instructions per cycle as well as clock frequency.
- Power efficiency - reduction of power for all functional blocks
- Security enhancements - new security features are implemented in hardware in the core
- Configurability
Configurability[edit]

Intel has been experiencing a growing divergence in functionality over the last number of iterations of their microarchitecture between their mainstream consumer products and their high-end HPC/server models. Traditionally, Intel has been using the same exact core design for everything from their lowest end value models (e.g. Celeron) all the way up to the highest-performance enterprise models (e.g. Xeon E7). While the two have fundamentally different chip architectures, they use the same exact CPU core architecture as the building block.
This design philosophy has changed with Skylake. In order to better accommodate the different functionalities of each segment without sacrificing features or making unnecessary compromises Intel went with a configurable core. The Skylake core is a single development project, making up a master superset core. The project result in two derivatives: one for servers and one for clients (the topic of this article). All mainstream models (from Celeron/Pentium all the way up to Core i7/Xeon E3) use the client core configuration. Server models (e.g. Xeon Gold/Xeon Platinum) will be using the new server configuration.
The server core is considerably larger than the client one, featuring Advanced Vector Extensions 512 (AVX-512). Skylake servers support what was formerly called AVX3.2 (AVX512F + AVX512CD + AVX512BW + AVX512DQ + AVX512VL). Additionally, those processors Memory Protection Keys for Userspace (PKU), PCOMMIT, and CLWB.
Pipeline[edit]
The Skylake core focuses on extracting performance and reducing power through a number of key ways. Intel builds Skylake on previous microarchitectures, descendants of Sandy Bridge. For the core to increase the overall performance, Intel focused on extracting additional parallelism.
Broad Overview[edit]
At a 5,000 foot view, Skylake represents the logical evolution from Haswell and Broadwell. Therefore, despite some significant differences from the previous microarchitecture, the overall designs is fundamentally the same and can be seen as enhancements over Broadwell rather than a complete change.

The pipeline can be broken down into three areas: the front-end, back-end or execution engine, and the memory subsystem. The goal of the front-end is to feed the back-end with a sufficient stream of operations which it gets by decoding instructions coming from memory. The front-end has two major pathways: the µOPs cache path and the legacy path. The legacy path is the traditional path whereby variable-length x86 instructions are fetched from the level 1 instruction cache, queued, and consequently get decoded into simpler, fixed-length µOPs. The alternative and much more desired path is the µOPs cache path whereby a cache containing already decoded µOPs receives a hit allowing the µOPs to be sent directly to the decode queue.
Regardless of which path an instruction ends up taking it will eventually arrive at the decode queue. The IDQ represents the end of the front-end and the in-order part of the machine and the start of the execution engine which operates out-of-order.
In the back-end, the micro-operations visit the reorder buffer. It's there where register allocation, renaming, and retiring takes place. At this stage a number of other optimizations are also done. From the reorder buffer, µOPs are sent to the unified scheduler. The scheduler has a number of exit ports, each wired to a set of different execution units. Some units can perform basic ALU operations, others can do multiplication and division, with some units capable of more complex operations such as various vector operations. The scheduler is effectively in charge of queuing the µOPs on the appropriate port so they can be executed by the appropriate unit.
Some µOPs deal with memory access (e.g. load & store). Those will be sent on dedicated scheduler ports that can perform those memory operations. Store operations go to the store buffer which is also capable of performing forwarding when needed. Likewise, Load operations come from the load buffer. Skylake features a dedicated 32 KiB level 1 data cache and a dedicated 32 KiB level 1 instruction cache. It also features a core-private 256 KiB L2 cache that is shared by both of the L1 caches.
Each core enjoys a slice of a third level of cache that is shared by all the core. For Skylake, there are either two cores or four cores connected together on a single chip.
Front-end[edit]
The front-end is tasked with the challenge of fetching the complex x86 instructions from memory, decoding them, and delivering them to the execution units. In other words, the front end needs to be able to consistently deliver enough µOPs from the instruction code stream to keep the back-end busy. When the back-end is not being fully utilized, the core is not reaching its full performance. A poorly or under-performing front-end will translate directly to a poorly performing core. This challenge is further complicated by various redirection such as branches and the complex nature of the x86 instructions themselves.
Fetch & pre-decoding[edit]
On their first pass, instructions should have already been prefetched from the L2 cache and into the L1 cache. The L1 is a 32 KiB, 8-way set associative cache, identical in size and organization to previous generations. Skylake fetching is done on a 16-byte fetch window. A window size that has not changed in a number of generations. Up to 16 bytes of code can be fetched each cycle. Note that fetcher is shared evenly between the two threads so that each thread gets every other cycle. At this point they are still macro-ops (i.e. variable-length x86 architectural instruction). Instructions are brought into the pre-decode buffer for initial preparation.

x86 instructions are complex, variable length, have inconsistent encoding, and may contain multiple operations. At the pre-decode buffer, the instructions boundaries get detected and marked. This is a fairly difficult task because each instruction can vary from a single byte all the way up to fifteen. Moreover, determining the length requires inspecting a couple of bytes of the instruction. In addition to boundary marking, prefixes are also decoded and checked for various properties such as branches. As with previous microarchitectures, the pre-decoder has a throughput of 6 macro-ops per cycle or until all 16 bytes are consumed, whichever happens first. Note that the predecoder will not load a new 16-byte block until the previous block has been fully exhausted. For example, suppose a new chunk was loaded, resulting in 7 instructions. In the first cycle, 6 instructions will be processed and a whole second cycle will be wasted for that last instruction. This will produce the much lower throughput of 3.5 instructions per cycle which is considerably less than optimal. Likewise, if the 16-byte block resulted in just 4 instructions with 1 byte of the 5th instruction received, the first 4 instructions will be processed in the first cycle and a second cycle will be required for the last instruction. This will produce an average throughput of 2.5 instructions per cycle. Note that there is a special case for length-changing prefix (LCPs) which will incur additional pre-decoding costs. Real code is often less than 4 bytes which usually results in a good rate.
All of this works along with the branch prediction unit which attempts to guess the flow of instructions. In Skylake, the branch predictor has also been improved. The branch predictor now has reduced penalty (i.e. lower latency) for wrong direct jump target prediction. Additionally, the predictor in Skylake can inspect further in the byte stream than in previous architectures. The intimate improvements done in the branch predictor were not further disclosed by Intel.
Instruction Queue & MOP-Fusion[edit]
| MOP-Fusion Example: | ||
cmp eax, [mem] jne loop |
→ | cmpjne eax, [mem], loop |
- See also: Macro-Operation Fusion
The pre-decoded instructions are delivered to the Instruction Queue (IQ). In Broadwell, the Instruction Queue has been increased to 25 entries duplicated over for each thread (i.e. 50 total entries). It's unclear if that has changed with Skylake. One key optimization the instruction queue does is macro-op fusion. Skylake can fuse two macro-ops into a single complex one in a number of cases. In cases where a test or compare instruction with a subsequent conditional jump is detected, it will be converted into a single compare-and-branch instruction. Those fused instructions remain fused throughout the entire pipeline and get executed as a single operation by the branch unit thereby saving bandwidth everywhere. Only one such fusion can be performed during each cycle.
Decoding[edit]

Up to four pre-decoded instructions are sent to the decoders each cycle. Like the fetchers, the Decoders alternate between the two thread each cycle. Decoders read in macro-operations and emit regular, fixed length µOPs. Skylake represents a big genealogical change from the last couple of microarchitectures. Skylake's pipeline is wider than it predecessors; Skylake adds another simple decoder. The five decoders are asymmetric; the first one, Decoder 0, is a complex decoder while the other four are simple decoders. A simple decoder is capable of translating instructions that emit a single fused-µOP. By contrast, a complex decoder can decode anywhere from one to four fused-µOPs. Skylake is now capable of decoding 4 macro-ops per cycle, same as Broadwell. Overall up to 4 simple instructions can be decoded each cycle with lesser amounts if the complex decoder needs to emit addition µOPs; i.e., for each additional µOP the complex decoder needs to emit, 1 less simple decoder can operate. In other words, for each additional µOP the complex decoder emits, one less decoder is active.
MSROM & Stack Engine[edit]
There are more complex instructions that are not trivial to be decoded even by complex decoder. For instructions that transform into more than four µOPs, the instruction detours through the microcode sequencer (MS) ROM. When that happens, up to 4 µOPs/cycle are emitted until the microcode sequencer is done. During that time, the decoders are disabled.
x86 has dedicated stack machine operations. Instructions such as PUSH, POP, as well as CALL, and RET all operate on the stack pointer (ESP). Without any specialized hardware, such operations would need to be sent to the back-end for execution using the general purpose ALUs, using up some of the bandwidth and utilizing scheduler and execution units resources. Since Pentium M, Intel has been making use of a Stack Engine. The Stack Engine has a set of three dedicated adders it uses to perform and eliminate the stack-updating µOPs (i.e. capable of handling three additions per cycle). Instruction such as PUSH are translated into a store and a subtraction of 4 from ESP. The subtraction in this case will be done by the Stack Engine. The Stack Engine sits after the decoders and monitors the µOPs stream as it passes by. Incoming stack-modifying operations are caught by the Stack Engine. This operation alleviate the burden of the pipeline from stack pointer-modifying µOPs. In other words, it's cheaper and faster to calculate stack pointer targets at the Stack Engine than it is to send those operations down the pipeline to be done by the execution units (i.e., general purpose ALUs).
µOP cache & x86 tax[edit]
- See also: Sandy Bridge § New µOP cache

Decoding the variable-length, inconsistent, and complex x86 instructions is a nontrivial task. It's also expensive in terms of performance and power. Therefore, the best way for the pipeline to avoid those things is to simply not decode the instructions. This is the job of the µOP cache or the Decoded Stream Buffer (DSB). Skylake's µOP cache is organized similarly to all previous generations since its introduction in Sandy Bridge, however both the bandwidth and the tracking window was increased. The cache is organized into 32 sets of 8 cache lines with each line holding up to 6 µOP for a total of 1,536 µOPs. Since Sandy Bridge, the µOP cache operated on 32-byte fetch windows. In Skylake, the window size has been doubled to 64 bytes. The micro-operation cache is competitively shared between the two threads and can also hold pointers to the microcode. The µOP cache has an average hit rate of 80% or greater.
A hit in the µOP allows for up to 6 µOPs (i.e., entire line) per cycle to be sent directly to the Instruction Decode Queue (IDQ), bypassing all the pre-decoding and decoding that would otherwise have to be done. Whereas the legacy decode path works in 16-byte instruction fetch windows, the µOP cache has no such restriction and can deliver 6 µOPs/cycle corresponding to the much bigger 64-byte window. Previously (e.g., Broadwell), the bandwidth was lower at 4 µOP per cycle. The 1.5x bandwidth increase greatly improves the numbers of µOP that the back-end can take advantage of in the out-of-order part of the machine. This change attempts to improve instruction rate by alleviating bubbles, however everything is still hard-limited by the rename and retire which puts an absolute ceiling rate of four fused µOPs per cycle.
Allocation Queue[edit]
The emitted µOPs from the decoders are sent directly to the Allocation Queue (AQ) or Instruction Decode Queue (IDQ). The Allocation Queue acts as the interface between the front-end (in-order) and the back-end (out-of-order). Skylake's Allocation Queue has more than doubled from Broadwell from 28-entries per thread to 64-entries per thread. Unlike in Haswell, the IDQ is no longer competitively shared; it's partitioned between two active threads. The queue's purpose is effectively help absorb bubbles which may be introduced in the front-end, ensuring that a steady stream of 6 µOPs are delivered each cycle.
µOP-Fusion & LSD[edit]
The IDQ does a number of additional optimizations as it queues instructions. The Loop Stream Detector (LSD) is a mechanism inside the IDQ capable of detecting loops that fit in the IDQ and lock them down. That is, the LSD can stream the same sequence of µOPs directly from the IDQ continuously without any additional fetching, decoding, or utilizing additional caches or resources. Streaming continues indefinitely until reaching a branch mis-prediction. Note that while the LSD is active, the rest of the front-end is effectively disabled.
The LSD in Skylake can take advantage of the considerably larger IDQ; capable of detecting loops up to 64 µOPs per thread. The LSD is particularly excellent in for many common algorithms that are found in many programs (e.g., tight loops, intensive calc loops, searches, etc..).
- NOTE: A microcode update appear to have disabled the LSD on client processors. See Skylake (server) § Front-end. Also see erratum SKL150.
Execution engine[edit]

Skylake's back-end or execution engine deals with the execution of out-of-order operations. Much of the design is inherited from previous architectures such as Haswell but has been widened to explore more instruction-level parallelism opportunities. From the allocation queue instructions are sent to the Reorder Buffer (ROB) at the rate of up to 6 fused-µOPs each cycle. Skylake's throughput is up by 2 fused-µOPs per cycle from Broadwell in order to accommodate the wider front-end.
Renaming & Allocation[edit]
Like the front-end, the Reorder Buffer has been increased to 224 entries, 32 entries more than Broadwell. Since each ROB entry holds complete µOPs, in practice 224 entries might be equivalent to as much as 350 µOPs depending on the code being executed (e.g. fused load/stores). It is at this stage that architectural registers are mapped onto the underlying physical registers. Other additional bookkeeping tasks are also done at this point such as allocating resources for stores, loads, and determining all possible scheduler ports. Register renaming is also controlled by the Register Alias Table (RAT) which is used to mark where the data we depend on is coming from (after that value, too, came from an instruction that has previously been renamed). In previous microarchitectures, the RAT could handle 4 µOPs each cycle. Intel has not disclosed if that has changed in Skylake but it's possible. If unchanged, Skylake can rename any four registers per cycle. This includes the same register renamed four times in a single cycle. If the rename has not increased in Skylake, some aspects of improvements that were done in the prefetch/decode stages are effectively lost. Note that the ROB still operates on fused µOPs, therefore 4 µOPs can effectively be as high as 8 µOPs.
It should be noted that there is no special costs involved in splitting up fused µOPs before execution or retirement and the two fused µOPs only occupy a single entry in the ROB.
Since Skylake performs speculative execution, it can speculate incorrectly. When this happens, the architectural state is invalidated and as such needs to be rolled back to the last known valid state. Skylake has a 48-entry Branch Order Buffer (BOB) that keeps tracks of those states for this very purpose.
Optimizations[edit]
Skylake has a number of optimizations it performs prior to entering the out-of-order and renaming part. Three of those optimizations include Move Elimination and Zeroing Idioms, and Ones Idioms. A Move Elimination is capable of eliminating register-to-register moves (including chained moves) prior to bookkeeping at the ROB, allowing those µOPs to save resources and eliminating them entirely. Eliminated moves are zero latency and are entirely removed from the pipeline. This optimization does not always succeed; when it fails, the operands were simply not ready. On average this optimization is almost always successful (upward of 85% in most cases). Move elimination works on all 32- and 64-bit GP integer registers as well as all 128- and 256-bit vector registers.
| Zeroing Idiom Example: |
xor eax, eax |
Not only does this instruction get eliminated at the ROB, but it's actually encoded as just 2 bytes 31 C0 vs the 5 bytes for mov eax, 0x0 which is encoded as b8 00 00 00 00.
|
There are some exceptions that Skylake will not optimize, most dealing with signedness. sign-extended moves cannot be eliminated and neither can zero-extended from 16-bit to 32/64 big registers (note that 8-bit to 32/64 works). Likewise, in the other direction, no moves to 8/16-bit registers can be eliminated. A move of a register to itself is never eliminated.
When instructions use registers that are independent of their prior values, another optimization opportunity can be exploited. A second common optimization performed in Skylake around the same time is Zeroing Idioms elimination. A number common zeroing idioms are recognized and consequently eliminated in much the same way as the move eliminations are performed. Skylake recognizes instructions such as XOR, PXOR, and XORPS as zeroing idioms when the source and destination operands are the same. Those optimizations are done at the same rate as renaming during renaming (at 4 µOPs per cycle) and the register is simply set to zero.
The ones idioms is another dependency breaking idiom that can be optimized. In all the various PCMPEQx instructions that perform packed comparison the same register with itself always set all bits to one. On those cases, while the µOP still has to be executed, the instructions may be scheduled as soon as possible because the current state of the register need not be known.
Scheduler[edit]

The scheduler itself was increased by 50%; with up to 97 entries (from 64 in Broadwell) being competitively shared between the two threads. Skylake continues with a unified design; this is in contrast to designs such as AMD's Zen which uses a split design each one holding different types of µOPs. Scheduler includes the two register files for integers and vectors. It's in those register files that output operand data is stored. In Skylake, the integer register file was also slightly increased from 160 entries to 180.
At this point µOPs are not longer fused and will be dispatched to the execution units independently. The scheduler holds the µOPs while they wait to be executed. A µOP could be waiting on an operand that has not arrived (e.g., fetched from memory or currently being calculated from another µOPs) or because the execution unit it needs is busy. Once the µOP is ready, it is dispatched through its designated port. The scheduler will send the oldest ready µOP to be executed on each of the eight ports each cycle.
The scheduler had its ports rearranged to better balance various instructions. For example, divide and sqrt instructions latency and throughput were improved. The latency and throughput of floating point ADD, MUL, and FMA were made uniform at 4 cycles with a throughput of 2 µOPs/clock. Likewise the latency of AES instructions were significantly reduced from 7 cycles down to 4.
Scheduler Ports & Execution Units[edit]
| Scheduler Ports Designation | |
|---|---|
| Port 0 | Integer/Vector Arithmetic, Multiplication, Logic, Shift, and String ops |
| FP Add, Multiply, FMA | |
| Integer/FP Division and Square Root | |
| AES Encryption | |
| Branch2 | |
| Port 1 | Integer/Vector Arithmetic, Multiplication, Logic, Shift, and Bit Scanning |
| FP Add, Multiply, FMA | |
| Port 5 | Integer/Vector Arithmetic, Logic |
| Vector Permute | |
| x87 FP Add, Composite Int, CLMUL | |
| Port 6 | Integer Arithmetic, Logic, Shift |
| Branch | |
| Port 2 | Load, AGU |
| Port 3 | Load, AGU |
| Port 4 | Store, AGU |
| Port 7 | AGU |
| Execution Units | ||
|---|---|---|
| Execution Unit | # of Units | Instructions |
| ALU | 4 | add, and, cmp, or, test, xor, movzx, movsx, mov, (v)movdqu, (v)movdqa, (v)movap*, (v)movup* |
| DIV | 1 | divp*, divs*, vdiv*, sqrt*, vsqrt*, rcp*, vrcp*, rsqrt*, idiv |
| Shift | 2 | sal, shl, rol, adc, sarx, adcx, adox, etc... |
| Shuffle | 1 | (v)shufp*, vperm*, (v)pack*, (v)unpck*, (v)punpck*, (v)pshuf*, (v)pslldq, (v)alignr, (v)pmovzx*, vbroadcast*, (v)pslldq, (v)psrldq, (v)pblendw |
| Slow Int | 1 | mul, imul, bsr, rcl, shld, mulx, pdep, etc... |
| Bit Manipulation | 2 | andn, bextr, blsi, blsmsk, bzhi, etc |
| FP Mov | 1 | (v)movsd/ss, (v)movd gpr |
| SIMD Misc | 1 | STTNI, (v)pclmulqdq, (v)psadw, vector shift count in xmm |
| Vec ALU | 3 | (v)pand, (v)por, (v)pxor, (v)movq, (v)movq, (v)movap*, (v)movup*, (v)andp*, (v)orp*, (v)paddb/w/d/q, (v)blendv*, (v)blendp*, (v)pblendd |
| Vec Shift | 2 | (v)psllv*, (v)psrlv*, vector shift count in imm8 |
| Vec Add | 2 | (v)addp*, (v)cmpp*, (v)max*, (v)min*, (v)padds*, (v)paddus*, (v)psign, (v)pabs, (v)pavgb, (v)pcmpeq*, (v)pmax, (v)cvtps2dq, (v)cvtdq2ps, (v)cvtsd2si, (v)cvtss2si |
| Vec Mul | 2 | (v)mul*, (v)pmul*, (v)pmadd* |
| This table was taken verbatim from the Intel manual. Execution unit mapping to MMX instructions are not included. | ||
Retirement[edit]
Once a µOP executes, or in the case of fused µOPs both µOPs have executed, they can be retired. Haswell is able to commit up to four fused µOPs each cycle per thread. Retirement happens in-order and releases any used resources such as those used to keep track in the reorder buffer. Because the allocation queue delivery in Skylake has been increased to 6 µOPs (12 unfused) from previously 4 µOPs (8 unfused) per cycle, the SMT implementation in Skylake should have some additional efficiency as there's now better chance for higher sustainable retirement rate.
Memory subsystem[edit]

Skylake's memory subsystem is in charge of the loads and store requests and ordering. Since Haswell, it's possible to sustain two memory reads (on ports 2 and 3) and one memory write (on port 4) each cycle. Each memory operation can be of any register size up to 256 bits. Skylake memory subsystem has been improved. The store buffer has been increased by 42 entries from Broadwell to 56 for a total of 128 simultaneous memory operations in-flight or roughly 60% of all µOPs. Special care was taken to reduce the penalty for page-split loads; previously scenarios involving page-split loads were thought to be rarer than they actually are. This was addressed in Skylake with page-split loads are now made equal to other splits loads. Expect page split load penalty down to 5 cycles from 100 cycles in Broadwell. The average latency to forward a load to store has also been improved and stores that miss in the L1$ generate L2$ requests to the next level cache much earlier in Skylake than before.
The L2 to L1 bandwidth in Skylake is the same as Haswell at 64 bytes per cycle in either direction. Note that one operation can be done each cycle; i.e., the L1 can either receive data from the L2 or send data to the Load/Store buffers each cycle, but not both. Latency from L2$ to L3$ has also been decreased from 4 cycles/line to 2 cycles/line. The bandwidth from the level 2 cache to the shared level 3 is 32 bytes per cycle.
eDRAM architectural changes[edit]
Intel ships a number of products with Embedded DRAM incorporated on package in order to increase performance of the integrated graphics and to a lesser degree the code through additional bandwidth and caching. There has been a number of significant architectural changes in how the eDRAM works in Skylake.
In Broadwell, the eDRAM was statically attached to the LLC (last level cache, L3$ from the perspective of the CPU Cores and L4$ from the perspective of the IGP), effectively stealing half a Mebibyte per core in the process, but behaving as an architectural true level 4 cache. This was fundamentally changed in Skylake. In Skylake, Intel removed the eDRAM from the LLC to its own array, re-freeing the 512 KiB (hence the 1.5 MiB/core in Broadwell and 2 MiB back in Skylake), but also removing the undesired dependency between the capacity of the eDRAM and the number of cores. Skylake's cache is effectively no longer a true level 4 cache but rather a memory side cache. This has a number of benefits such as that each and every memory access that goes through the memory controller gets looked up in the eDRAM. On a satisfied hit, the value is obtained from there. On a miss, a value gets allocated and stored in the eDRAM (subject to a number of restrictions, for example no I/O devices requests get cached on the eDRAM).
| Skylake vs Broadwell eDRAM Architecture | |
|---|---|
| Broadwell | Skylake |
 |

|
The new eDRAM changes mean it's no longer architectural - capable of caching any data (including "unreachable memory", display engines, and effectively any memory transfer not bound by software restrictions) and is entirely invisible to software (one exception noted later) in terms of coherency (note that no flushing is thus necessary to maintain coherency), ordering, or other organizational details. For optimal graphics performance, the graphics driver may decide to limit certain memory accesses to only the eDRAM, only the LLC, or in both of them.
Configurability[edit]
Skylake features a highly-configurable design, using the same macro cells, Intel can meet the different market segment requirements. The Skylake family consists out of 5 different actual dies, which can be further segmented by disabling different features, e.g. GT1 graphics are based on GT2 graphics with half the execution units disabled.
- Physical Layout Breakdown
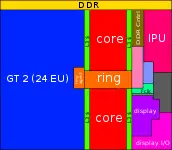
Dual-core die, GT2 GPU, Low Power
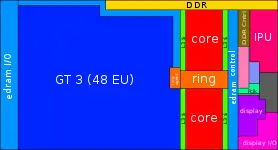
Dual-core die, GT3 GPU, Low Power
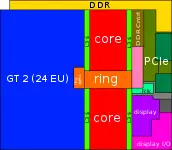
Dual-core die, GT2 GPU, High Power
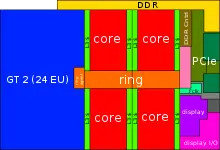
Quad-core die, GT2 GPU, High Power
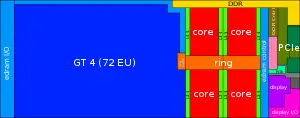
Quad-core die, GT4 GPU, High Power





New Technologies[edit]
Software Guard Extension (SGX)[edit]
- Main article: Intel's Software Guard Extension
Software Guard Extension (SGX) is a new inter-software guard x86 extension that allows software in user-level mode to create isolated secure environments called "enclaves" for storing data or code. Data and code stored in enclaves are protected from external processes including code executing with higher privileges including the operating system or a hypervisor (including all forms of debugging).
Memory Protection Extension (MPX)[edit]
- Main article: Intel's Memory Protection Extension
Memory Protection Extension (MPX) is a new x86 extension that offers a hardware-level bound checking implementation. This extension allows an application to define memory boundaries for allocated memory areas. The processors can then check all proceeding memory accesses against those boundaries to ensure accesses are not out of bound. A program accessing a boundary-marked buffer out of buffer will generate an exception.
Power[edit]
"Speed Shift" (new power management)[edit]
Ever since the introduction of the modern power management unit on a microprocessor, it was effectively the role of the operating system to determine the desired operating frequency and voltage (i.e. a p-state) for the current workload. When the CPU utilization peaked, it was the role of the operating system to bump up the frequency to help cope with it. The issue has always been the limitation of the operating system. One such major limitation is the granularity of the operating system response time - usually in the 10s of milliseconds (anything lower than that would likely be too intensive and would not yield better result). A second major issue is that the operating system doesn't have an instantaneous observation of the microarchitectural behavior of the workload.
Intel introduced Speed Shift with Skylake, a new methodology for quickly alternating core frequencies in response to power loads. Intel introduced a new unit called Package Control Unit (PCU) which is effectively a full fledged microcontroller (containing power management logic and firmware) that collects and tracks many internal SoC statistics as well as external power telemetry (e.g. Psys and iMon). PCU is also capable of interfacing with the OS, BIOS, and DPTF. Speed Shift improves the performance of frequency shifting by off-loading the control from the operating system to the PCU.
Speed Shift effectively eliminates the need for the OS to manages the P-states - though it does have the final say (unless special exceptions occur such as thermal throttling). Intel calls this "autonomous P-state", allowing Speed Shift to kick in in a matter of just ~1 millisecond (whereas the operating system-based p-states control can be as slow as 30 ms). Speed Shift effectively reduces hitting peak frequency in around ~30 ms from over 100 ms (OS-based implementation as before). While Speed Shift is capable of full range shift by default, the operating system can set the minimum QoS, maximum frequency and power/performance hints when desired. The final result should be higher performance and specially higher responsiveness at power constrained form factors.
SpeedStep Technology Expansion[edit]
- Main article: SpeedStep Technology
Prior to Skylake, SpeedStep had three major domains: Cores, Integrated Graphics, and Coherent Fabric. With Skylake, SpeedStep has been extended to a number of new domains, including the System Agent, Memory, and the eDRAM I/O. Depending on the bandwidth consumption, SpeedStep can now save energy by reducing frequency on the new domains.
Information from the new domains, including additional thermal skín temperature control information is now supplied to OEMs.
Power of System (Psys)[edit]
Psys (Power of System) is a way for the PCU to monitor the performance and the total platform power provided to the chip. The chip uses a number of autonomous algorithms (one for "Low Range" and one for "High Range"). The Low Range algorithm frequency is lowered to conserve energy. Algorithm is capable of overriding the low P state - a state calculated ever millisecond based on the active workload and system characteristics. The High Range algorithm deals with elevating frequency for the benefit of increase performance (at the cost of increase energy/inefficiency). The exact ratio of ΔPower/ΔPerformance ≤ αPreference can be finely controlled via the OS and user preferences.
Other Power Optimization[edit]
Skylake includes a number of additional power optimization changes:
- AVX2 is now power gated - prior to Skylake, AVX2 was not power gated which meant it was susceptible to leakage. Starting with Skylake, those instruction are full power gated and turn off when not used.
- Many older/legacy underused resources have been downscaled.
- Various scenario-based power optimizations were done, including:
- Idle power is reduced further
- C1 state power reduction (improved dynamic capacitance Cdyn)
- For specific tasks such as streaming, Skylake is capable of powering down certain components of the GPU maintaining power on to the critical components needed for that purpose.
Overall Skylake enjoys better performance/Watt per core for 8x performance/watt over Nehalem.
AVX2 Power Gating[edit]
In Skylake, AVX2 has been entirely power-gated. The motive for this change is derived from the fact that applications either make heavy use of AVX2 instructions or don't use it at all. Most programs seldomly use AVX2 for only a small number of instructions. This gave Intel the ability to completely power gate it when the core execute code that does not make use of those instructions. Skylake requires a warm-up time before instructions can execute at full rate (in the order of a couple of 10,000s of cycles depending on frequency). Executing a dummy AVX2 instruction some time prior to heavy AVX2 workloads to prepare the CPU can avoid this.
Clock domains[edit]
Skylake is divided into a number of clock domains, each controlling the clock frequency of their respective unit in the processor. All clock domains are some multiple of the [virtual] bus clock (BCLK).
- BCLK - Bus/Base Clock - The system bus interface frequency (once upon a time referred to the actual FSB speed, it now serves as only a base clock reference for all other clock domains). The base clock is 100 MHz.
- Core Clock - The frequency at which the core and the L1/L2 caches operate at. (Frequency depends on the model and is represented as a multiple of BCLK).
- Ring Clock - The frequency at which the ring interconnect and LLC operate at. Data from/to the individual cores are read/written into the L3 at a rate of 32B/cycle operating at Ring Clock frequency.
- IGP Clock - The frequency at which the integrated graphics (Gen9 GPU) operates at. Data from/to the GPU are read/written into the LLC at a rate of 64B/cycle operating at this frequency as well.
- eDRAM Clock - The frequency at which the embedded DRAM operates at (only available for certain models). Data is read/written from/to the LLC at a rate of 32B/cycle operating at this frequency as well.
- MemClk - Memory Clock - The frequency at which the system DRAM operates at. DRAM data is transfered at a rate of 8B/cycle operating at MemClk frequency.

Overclocking[edit]
- See also: Intel's XMP

Skylake has improved overclocking capabilities greatly. Overclocking is generally done on unlocked parts such as the Core i7-6700K, Core i5-6600K, and the mobile Core i7-6820HK processor. Unlocked processors should be paired with a chipset such as the Z170 which offers the most overclocking capabilities such as unlocked BCLK, unlocked core ratio, unlocked memory ratio, unlocked GPU ratio, and voltage controls.
Skylake increased both the overclocking range and ratio granularity, allowing for much more finer overclocking.
| Core i7-3770K | Core i7-4790K | Core i7-6700K | |
|---|---|---|---|
| Core Ratios Override | Up to x63 | Up to x80 | Up to x83 |
| Real-time Core Ratio | ✔ | ✔ | ✔ |
| BCLK Overclocking | Limited | 100/125/167 MHz | 100+ in 1 MHz increments |
| MSR Voltage Control | SVID Extra Voltage | FIVR SVID Extra Voltage, Voltage Override, Interpolative | SVID Extra Voltage, Voltage Override, Interpolative |
| GPU Overclocking | All Chipsets | All Chipsets | All Chipsets |
| DDR Ratio/Frequency Override and MRC | Up to 2667 MT/s | Up to 2667 MT/s | Up to 4133 MT/s |
| DDR Granularity Steps | 200/266 MHz | 200/266 MHz | 100/133 MHz |
Note that core ratio has been increased to a [theoretical] x83 multiplier and the coarse-grain ratio was dropped from Skylake allowing a BCLK ratio to have granularity of 1 MHz increments with BCLK frequency of over 200 readily achievable. The FIVR was removed and the voltage control was given back to the motherboard manufacturers; i.e., voltage supplies can be entirely motherboard-controlled. Skylake also bumped the DDR ratio up to 4133 MT/s.

In the diagram on the left (xC) refers to the Core Frequency and is represented as a multiple of BCLK (Core Frequency = BCLK × Core Freq Multiplier up to x83). Likewise (xM) refers to the memory ratio (up to 4133 MT/s) and (xG) refers to the Graphics Frequency (pGfx; up to x60).
The BCLK in Skylake has undergone dramatic architectural changes. Considerable effort was dedicated to separating the DMI and PEG (PCIe & Graphics), allowing DMI/PEG to run at their nominal ~100 MHz clock in their own isolated clock domain. This allows BCLK to run at very high speeds (200 MHz+ with upward of 400 MHz+ in LN2). Additionally, while the BCLK is typically supplied by the chipset internal clock generator, it's also possible to supply the clock externally; i.e., motherboard ODMs can potentially take advantage of this and offer their own discrete BCLK control.


Overclocking may involve changing the BCLK frequency. Because a large number of components operate their own clock domains as a multiple of the BCLK, an increase of 10% to the BCLK frequency will result in an increase of 10% to all other components. On Skylake, the PCIe & DMI sit on their own dedicated reference clock.
The primary voltage rails on Skylake are the VCORE = VRING which can operate up to 1.52 V (SVID) + Vboost. VDDQ is the typical 1.2 V nominal voltage for DDR4. VGT refers to the graphics processor which can also operate up to 1.52 V (SVID) + Vboost. Lastly the VSA refers to the system agent which has its own voltage control as well. Note that the ring voltage now runs at core voltage; Intel found no harm in overclocking and coupling them together. Additional rails are provided to the manufacturers which they can also expose for overclocking.
Voltage Control Modes[edit]

As with all of Intel's latest microarchitectures, Skylake incorporates a Power Control Unit (PCU) which is a dedicated microcontroller on-die in the System Agent. The PCU runs dedicated embedded firmware and makes dynamic power management decisions based on various global inputs such as temperature, current, power, and workload types.
The system can operate in a number of Voltage Control Modes. The mode chosen dictates how the PCU determines what voltage to use:
- Fused V/f - This is the default mode where the PCU will adjust the voltage based on frequency with a voltage cap at the max turbo frequency.
- Interpolation (adaptive) V/f - In this mode a higher custom voltage point (e.g., 1.5 V) can be set. The PCU will then continue to increase voltage with frequency in a granular way up to the custom point. Likewise, if the frequency drops (e.g. when the system is idle) the voltage is reduced. This mode helps prolong the life of the chip by reducing the voltage when not needed.
- Offset V/f - An offset mode allows the entire voltage curve to be shifted up by a certain amount. This mode can also be combined with any other mode to increase its entire curve by a certain millivoltage.
- Override V/f - Override is an extreme overclocking mode whereby the system runs at a fixed voltage the entire time.
New Integration[edit]
Image Processing Unit (IPU)[edit]
Skylake integrates a new Image Processing Unit (IPU) on-die. The IPU is an entire imaging subsystem turnkey solution (i.e., ISP + hardware manipulation functionality), requiring only the external sensor camera. This feature is only available on the dual-core mobile models. The motivations behind this integration is primarily form factor the integrated IPU allows for higher user-end experience, and further power optimization.

The IPU hardware supports:
- Support for up to 4 cameras
- 13 MP zero shutter lag 1080p60/2160p30 video capture and imaging and a large array of standardized image processing capabilities.
- Face detection and recognition (smile/blink/group setting)
- Full resolution still capture during video captures
- Multi-stream video captures (up to 2 concurrent streams)
- Panorama
- Burst Captures
- HDR ultra low-light captures
Graphics[edit]
- Main article: Gen9
Support for three displays via HDMI 1.4[graphics 1], DisplayPort (DP) 1.2, an Embedded DisplayPort (eDP) 1.4 interfaces.
| Gen9 IGP Models | Standards | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Execution Units | Tier | Series | eDRAM | Vulkan | Direct3D | OpenGL | OpenCL | |||||
| Windows | Linux | Windows | Linux | HLSL | Windows | Linux | Windows | Linux | |||||
| HD Graphics 510 | 12 | GT1 | U, S | - | 1.0 | 12 | N/A | 5.1 | 4.5 | 4.5 | 2.0 | ||
| HD Graphics 515 | 24 | GT2 | Y | - | |||||||||
| HD Graphics 520 | 24 | GT2 | U | - | |||||||||
| HD Graphics 530 | 24 | GT2 | H, S | - | |||||||||
| HD Graphics P530 | 24 | GT2 | H | - | |||||||||
| Iris Graphics 540 | 48 | GT3e | U | 64 MiB | |||||||||
| Iris Graphics 550 | 48 | GT3e | U | 64 MiB | |||||||||
| Iris Pro Graphics P555 | 48 | GT3e | H | 128 MiB | |||||||||
| Iris Pro Graphics 580 | 72 | GT4e | H | 128 MiB | |||||||||
| Iris Pro Graphics P580 | 72 | GT4e | H | 128 MiB | |||||||||
- ↑ Note that while there is no native HDMI 2.0 support, Intel did provide somewhat of an awkward solution using an LSPCON (Level Shifter/Protocol Converter) to drive DP to HDMI 1.4 signal + convert HDMI 1.4 to HDMI 2.0. One such solution is the MegaChips MCDP2800.
Hardware Accelerated Video[edit]
| [Edit] Skylake (Gen9) Hardware Accelerated Video Capabilities | |||||||
|---|---|---|---|---|---|---|---|
| Codec | Encode | Decode | |||||
| Profiles | Levels | Max Resolution | Profiles | Levels | Max Resolution | ||
| MPEG-2 (H.262) | Main | High | 1080p (FHD) | Main | Main, High | 1080p (FHD) | |
| MPEG-4 AVC (H.264) | High, Main | 5.1 | 2160p (4K) | Main, High, SHP, MHP | 5.1 | 2160p (4K) | |
| JPEG/MJPEG | Baseline | - | 16k x 16k | Baseline | Unified | 16k x 16k | |
| HEVC (H.265) | Main | 5.1 | 2160p (4K) | Main, Main 10 | 5.1 | 2160p (4K) | |
| VC-1 | ✘ | Advanced, Main, Simple | 3, High | 3840x3840 | |||
| VP8 | Unified | Unified | - | 0 | Unified | 1080p | |
| VP9 | ✘ | 0 | Unified | 2160p (4K) | |||
Sockets/Platform[edit]
Skylake Y and U are single-chip solutions. Y chips utilize a 2-die multi-chip package (MCP) whereas the Skylake U's are either 2 or 3-die MCP configuration. The 3 die chip configuration are for the Iris IGPs which incorporate an on-package cache (OPC) in addition to the hub. Communication from the CPU to the hub on those chips are done via a lightweight On-Package Interconnect (OPI) interface. Skylake S and H are a two-chip solution linked together via Intel's standard DMI 3.0 bus interface which utilizes 4 of the CPU's 20 PCIe 3.0 lanes (having a transfer rate of 8 GT/s per lane). Only Skylake S (used on mainstream desktop processors) are not soldered onto the motherboard and can be interchanged/replaced.
| Core | Socket | Permanent | Platform | Chipset | Bus | |
|---|---|---|---|---|---|---|
 |
Skylake Y | BGA-1515 | Yes | 1-chip | N/A | OPI |
 |
Skylake U | BGA-1356 | Yes | 1-chip | ||
 |
Skylake H | BGA-1440 | Yes | 2-chip | Sunrise Point | DMI 3.0 |
 |
Skylake S | LGA-1151 | No | 2-chip | ||
| Skylake DT | LGA-1151 | No | 2-chip | Xeon Sunrise Point |
Packages[edit]
| Core | Die Type | Package | Dimensions |
|---|---|---|---|
| Skylake H | 4+2 | FCBGA-1440 | 42 mm x 28 mm x 1.46 mm |
| Skylake H | 2+2 | ||
| Skylake S | 4+2 | FCLGA-1151 | 37.5 mm x 37.5 mm x 4.4 mm |
| Skylake S | 2+2 |
Die[edit]
- See also: Server Skylake's Die
Skylake desktop and mobile come and 2 and 4 cores. Each variant has its own die. One of the most noticeable changes on die is the amount of die space allocated to the GPU. The major components of the die is:
- System Agent
- CPU Core
- Ring bus interconnect
- Memory Controller
System Agent[edit]
The System Agent (SA) contains the Image Processing Unit (IPU), the Display Engine (DE), the I/O bus and various other shared functionality. Note that the mainstream desktop (i.e., quad-core die) does not have an IPU (The memory controller actually occupies a portion of where it would otherwise be).
Dual-Core Die

.png)
Quad-Core Die

.png)
Core[edit]
Skylake Client models come in either 2x core or 4x core setup.
- ~3.95 mm x ~2.21 mm
- ~8.73 mm²

.png)
Core Group[edit]
Client models come in groups of 2 or 4 cores. (die sizes includes the dark silicon space where the L3 ends).
- 2-cores group:
- ~25.347 mm² die area
- ~8.91 mm x ~2.845 mm

- 4-core group
- ~50.354 mm² die area
- ~8.844 mm x 5.694 mm

Integrated Graphics[edit]
The integrated graphics takes up the largest portion of the die. The normal dual-core and quad-core dies come with 24 EU Gen9.5 GPU (with 12 units disabled on the low end models).

.png)
Dual-core[edit]
Die shot of the dual-core GT2 Skylake processors. Those are found in mobile models, and entry-level/budget processors:
- 14 nm process
- 11 metal layers
- ~1,750,000,000 transistors
- ~9.19 mm x ~11.08 mm
- ~101.83 mm² die size
- 2 CPU cores + 24 GPU EUs
.png)
_(annotated).png)
Quad-core[edit]
Die shot of the quad-core GT2 Skylake processors. Those are found in almost all mainstream desktop processors.
- 14 nm process
- 11 metal layers
- ~9.19 mm x ~13.31 mm
- ~122.3 mm² die size
- 4 CPU cores + 24 GPU EUs
.png)
_(annotated).png)
All Skylake Chips[edit]
| List of Skylake Processors | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Main processor | Turbo Boost | Mem | IGP | Major Feature Diff | |||||||||||||||||||||
| Model | Launched | Price | Family | Core Name | Cores | Threads | L2$ | L3$ | TDP | Frequency | 1 Core | 2 Cores | 3 Cores | 4 Cores | Max Mem | GPU | Frequency | Turbo | Turbo | SMT | AVX2 | TXT | TSX | vPro | |
| Uniprocessors | |||||||||||||||||||||||||
| 3855U | 27 December 2015 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Skylake U | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 510 | 300 MHz 0.3 GHz 300,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | |||||
| 3955U | 27 December 2015 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Skylake U | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 510 | 300 MHz 0.3 GHz 300,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | |||||
| G3900 | 19 October 2015 | $ 42.00 € 37.80 £ 34.02 ¥ 4,339.86 | Celeron | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G3900E | 2 January 2016 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Skylake H | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | |||||
| G3900T | 19 October 2015 | Celeron | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ||||||
| G3900TE | 19 October 2015 | $ 42.00 € 37.80 £ 34.02 ¥ 4,339.86 | Celeron | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G3902E | 2 January 2016 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Skylake H | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | |||||
| G3920 | 19 October 2015 | $ 52.00 € 46.80 £ 42.12 ¥ 5,373.16 | Celeron | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6006U | 10 November 2016 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core i3 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6098P | 27 December 2015 | $ 117.00 € 105.30 £ 94.77 ¥ 12,089.61 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 54 W 54,000 mW 0.0724 hp 0.054 kW | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6100 | 27 September 2015 | $ 117.00 € 105.30 £ 94.77 ¥ 12,089.61 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 3.7 GHz 3,700 MHz 3,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6100E | 12 October 2015 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Skylake H | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✔ | ✘ | |||||
| i3-6100H | 27 September 2015 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Skylake H | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6100T | 27 September 2015 | $ 117.00 € 105.30 £ 94.77 ¥ 12,089.61 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6100TE | 12 October 2015 | $ 117.00 € 105.30 £ 94.77 ¥ 12,089.61 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6100U | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core i3 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6102E | 12 October 2015 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Skylake H | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✔ | ✘ | |||||
| i3-6120T | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||||||
| i3-6157U | June 2016 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i3 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 28 W 28,000 mW 0.0375 hp 0.028 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 550 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6167U | 27 September 2015 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i3 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 28 W 28,000 mW 0.0375 hp 0.028 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 550 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6300 | 27 September 2015 | $ 147.00 € 132.30 £ 119.07 ¥ 15,189.51 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 3.8 GHz 3,800 MHz 3,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6300T | 27 September 2015 | $ 147.00 € 132.30 £ 119.07 ¥ 15,189.51 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6320 | 27 September 2015 | $ 157.00 € 141.30 £ 127.17 ¥ 16,222.81 | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i3-6320T | Core i3 | Skylake S | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||||||
| i5-6198DU | 27 December 2015 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 510 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||||
| i5-6200U | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| i5-6260U | 27 September 2015 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 540 | 300 MHz 0.3 GHz 300,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| i5-6267U | 27 September 2015 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 28 W 28,000 mW 0.0375 hp 0.028 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 550 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| i5-6287U | 27 September 2015 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 28 W 28,000 mW 0.0375 hp 0.028 kW | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 550 | 300 MHz 0.3 GHz 300,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| i5-6300HQ | 27 September 2015 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✘ | ✔ | ✘ | ✔ | ✘ | |
| i5-6300U | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| i5-6350HQ | 2 January 2016 | $ 306.00 € 275.40 £ 247.86 ¥ 31,618.98 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✔ | ✘ | ✔ | ✘ | ✘ | ✘ | ||||
| i5-6360U | 27 September 2015 | $ 304.00 € 273.60 £ 246.24 ¥ 31,412.32 | Core i5 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 540 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| i5-6400 | 27 September 2015 | $ 187.00 € 168.30 £ 151.47 ¥ 19,322.71 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✘ | ✔ | ✘ | ✘ | ✘ | |
| i5-6400T | 27 September 2015 | $ 182.00 € 163.80 £ 147.42 ¥ 18,806.06 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.5 GHz 2,500 MHz 2,500,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✘ | ✔ | ✘ | ✘ | ✘ | |
| i5-6402P | 27 December 2015 | $ 187.00 € 168.30 £ 151.47 ¥ 19,322.71 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✘ | ✔ | ✘ | ✘ | ✘ | ||||
| i5-6440EQ | 12 October 2015 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6440HQ | 27 October 2015 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6442EQ | 12 October 2015 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.5 GHz 2,500 MHz 2,500,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6500 | 27 September 2015 | $ 202.00 € 181.80 £ 163.62 ¥ 20,872.66 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6500T | 27 September 2015 | $ 192.00 € 172.80 £ 155.52 ¥ 19,839.36 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6500TE | 19 October 2015 | $ 192.00 € 172.80 £ 155.52 ¥ 19,839.36 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6585R | 22 April 2016 | $ 255.00 € 229.50 £ 206.55 ¥ 26,349.15 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✘ | ||||
| i5-6600 | 27 September 2015 | $ 224.00 € 201.60 £ 181.44 ¥ 23,145.92 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6600K | 27 September 2015 | $ 243.00 € 218.70 £ 196.83 ¥ 25,109.19 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 91 W 91,000 mW 0.122 hp 0.091 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✘ | ✔ | ✘ | ✔ | ✘ | |
| i5-6600T | 27 September 2015 | $ 213.00 € 191.70 £ 172.53 ¥ 22,009.29 | Core i5 | Skylake S | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| i5-6685R | 22 April 2016 | $ 288.00 € 259.20 £ 233.28 ¥ 29,759.04 | Core i5 | Skylake H | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✘ | ||||
| i7-6498DU | 27 September 2015 | $ 393.00 € 353.70 £ 318.33 ¥ 40,608.69 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 510 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-6500U | 27 September 2015 | $ 393.00 € 353.70 £ 318.33 ¥ 40,608.69 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| i7-6560U | 27 September 2015 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 540 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-6567U | 27 September 2015 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 28 W 28,000 mW 0.0375 hp 0.028 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 550 | 300 MHz 0.3 GHz 300,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-6600U | 27 September 2015 | $ 393.00 € 353.70 £ 318.33 ¥ 40,608.69 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 520 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| i7-6650U | 27 September 2015 | $ 415.00 € 373.50 £ 336.15 ¥ 42,881.95 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 540 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| i7-6660U | 20 March 2016 | $ 415.00 € 373.50 £ 336.15 ¥ 42,881.95 | Core i7 | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | Iris Graphics 540 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| i7-6700 | 27 September 2015 | $ 312.00 € 280.80 £ 252.72 ¥ 32,238.96 | Core i7 | Skylake S | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.4 GHz 3,400 MHz 3,400,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | |
| i7-6700HQ | 27 September 2015 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |
| i7-6700K | 27 September 2015 | $ 350.00 € 315.00 £ 283.50 ¥ 36,165.50 | Core i7 | Skylake S | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 91 W 91,000 mW 0.122 hp 0.091 kW | 4 GHz 4,000 MHz 4,000,000 kHz | 4.2 GHz 4,200 MHz 4,200,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | |
| i7-6700T | 27 September 2015 | $ 303.00 € 272.70 £ 245.43 ¥ 31,308.99 | Core i7 | Skylake S | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6700TE | 19 October 2015 | $ 303.00 € 272.70 £ 245.43 ¥ 31,308.99 | Core i7 | Skylake S | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6770HQ | 2 January 2016 | $ 434.00 € 390.60 £ 351.54 ¥ 44,845.22 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-6785R | 22 April 2016 | $ 370.00 € 333.00 £ 299.70 ¥ 38,232.10 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ||||
| i7-6820EQ | 12 October 2015 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6820HK | 27 September 2015 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | |
| i7-6820HQ | 27 October 2015 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6822EQ | 12 October 2015 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.55 GHz 2,550 MHz 2,550,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6870HQ | 2 January 2016 | $ 434.00 € 390.60 £ 351.54 ¥ 44,845.22 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-6920HQ | 27 October 2015 | $ 568.00 € 511.20 £ 460.08 ¥ 58,691.44 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| i7-6970HQ | 2 January 2016 | $ 623.00 € 560.70 £ 504.63 ¥ 64,374.59 | Core i7 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics 580 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-7500U | 30 August 2016 | $ 393.00 € 353.70 £ 318.33 ¥ 40,608.69 | Core i7 | Kaby Lake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 620 | 300 MHz 0.3 GHz 300,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||||
| i7-8565U | 28 August 2018 | $ 409.00 € 368.10 £ 331.29 ¥ 42,261.97 | Core i7 | Whiskey Lake U | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 4.6 GHz 4,600 MHz 4,600,000 kHz | 4.5 GHz 4,500 MHz 4,500,000 kHz | 4.1 GHz 4,100 MHz 4,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | UHD Graphics 620 | 300 MHz 0.3 GHz 300,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ||
| m3-6Y30 | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core m3 | Skylake Y | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 4.5 W 4,500 mW 0.00603 hp 0.0045 kW | 0.9 GHz 900 MHz 900,000 kHz | 2.2 GHz 2,200 MHz 2,200,000 kHz | 2 GHz 2,000 MHz 2,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 515 | 300 MHz 0.3 GHz 300,000 KHz | 850 MHz 0.85 GHz 850,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| m5-6Y54 | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core m5 | Skylake Y | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 4.5 W 4,500 mW 0.00603 hp 0.0045 kW | 1.1 GHz 1,100 MHz 1,100,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 515 | 300 MHz 0.3 GHz 300,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | |||
| m5-6Y57 | 27 September 2015 | $ 281.00 € 252.90 £ 227.61 ¥ 29,035.73 | Core m5 | Skylake Y | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 4.5 W 4,500 mW 0.00603 hp 0.0045 kW | 1.1 GHz 1,100 MHz 1,100,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 515 | 300 MHz 0.3 GHz 300,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| m7-6Y75 | 27 September 2015 | $ 393.00 € 353.70 £ 318.33 ¥ 40,608.69 | Core m7 | Skylake Y | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 4.5 W 4,500 mW 0.00603 hp 0.0045 kW | 1.2 GHz 1,200 MHz 1,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 515 | 300 MHz 0.3 GHz 300,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| 4405U | 3 November 2015 | $ 161.00 € 144.90 £ 130.41 ¥ 16,636.13 | Pentium | Skylake U | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 15 W 15,000 mW 0.0201 hp 0.015 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 510 | 300 MHz 0.3 GHz 300,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | |||||
| 4405Y | 3 November 2015 | $ 161.00 € 144.90 £ 130.41 ¥ 16,636.13 | Pentium | Skylake Y | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 6 W 6,000 mW 0.00805 hp 0.006 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 515 | 300 MHz 0.3 GHz 300,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | |||||
| G4400 | 27 September 2015 | $ 64.00 € 57.60 £ 51.84 ¥ 6,613.12 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 54 W 54,000 mW 0.0724 hp 0.054 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G4400T | 27 September 2015 | $ 64.00 € 57.60 £ 51.84 ¥ 6,613.12 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G4400TE | 9 December 2015 | $ 64.00 € 57.60 £ 51.84 ¥ 6,613.12 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 510 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G4500 | 27 September 2015 | $ 82.00 € 73.80 £ 66.42 ¥ 8,473.06 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G4500T | 27 September 2015 | $ 75.00 € 67.50 £ 60.75 ¥ 7,749.75 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 3 GHz 3,000 MHz 3,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| G4520 | 27 September 2015 | $ 93.00 € 83.70 £ 75.33 ¥ 9,609.69 | Pentium | Skylake S | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 51 W 51,000 mW 0.0684 hp 0.051 kW | 3.6 GHz 3,600 MHz 3,600,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics 530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | |||||
| E3-1220 v5 | 19 October 2015 | $ 203.00 € 182.70 £ 164.43 ¥ 20,975.99 | Xeon E3 | Skylake DT | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3 GHz 3,000 MHz 3,000,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1225 v5 | 19 October 2015 | $ 224.00 € 201.60 £ 181.44 ¥ 23,145.92 | Xeon E3 | Skylake DT | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 400 MHz 0.4 GHz 400,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | |
| E3-1235L v5 | 19 October 2015 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Xeon E3 | Skylake DT | 4 | 4 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 400 MHz 0.4 GHz 400,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1240 v5 | 19 October 2015 | $ 282.00 € 253.80 £ 228.42 ¥ 29,139.06 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1240L v5 | 19 October 2015 | $ 278.00 € 250.20 £ 225.18 ¥ 28,725.74 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1245 v5 | 19 October 2015 | $ 294.00 € 264.60 £ 238.14 ¥ 30,379.02 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 400 MHz 0.4 GHz 400,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1260L v5 | 19 October 2015 | $ 294.00 € 264.60 £ 238.14 ¥ 30,379.02 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1268L v5 | 19 October 2015 | $ 377.00 € 339.30 £ 305.37 ¥ 38,955.41 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1270 v5 | 19 October 2015 | $ 339.00 € 305.10 £ 274.59 ¥ 35,028.87 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.6 GHz 3,600 MHz 3,600,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1275 v5 | 19 October 2015 | $ 350.00 € 315.00 £ 283.50 ¥ 36,165.50 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.6 GHz 3,600 MHz 3,600,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 400 MHz 0.4 GHz 400,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1280 v5 | 19 October 2015 | $ 612.00 € 550.80 £ 495.72 ¥ 63,237.96 | Xeon E3 | Skylake DT | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 80 W 80,000 mW 0.107 hp 0.08 kW | 3.7 GHz 3,700 MHz 3,700,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||
| E3-1505L v5 | 12 October 2015 | $ 433.00 € 389.70 £ 350.73 ¥ 44,741.89 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.55 GHz 2,550 MHz 2,550,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1505M v5 | 12 October 2015 | $ 434.00 € 390.60 £ 351.54 ¥ 44,845.22 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✘ | ✔ | ✔ | |
| E3-1515M v5 | 2 January 2016 | $ 489.00 € 440.10 £ 396.09 ¥ 50,528.37 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1535M V5 | 12 October 2015 | $ 623.00 € 560.70 £ 504.63 ¥ 64,374.59 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | HD Graphics P530 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1545M v5 | 2 January 2016 | $ 679.00 € 611.10 £ 549.99 ¥ 70,161.07 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1558L v5 | 31 May 2016 | $ 396.00 € 356.40 £ 320.76 ¥ 40,918.68 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P555 | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1565L v5 | 31 May 2016 | $ 417.00 € 375.30 £ 337.77 ¥ 43,088.61 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1575M v5 | 2 January 2016 | $ 1,207.00 € 1,086.30 £ 977.67 ¥ 124,719.31 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 3 GHz 3,000 MHz 3,000,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1578L v5 | 31 May 2016 | $ 449.00 € 404.10 £ 363.69 ¥ 46,395.17 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| E3-1585 v5 | 31 May 2016 | $ 556.00 € 500.40 £ 450.36 ¥ 57,451.48 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 65 W 65,000 mW 0.0872 hp 0.065 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| E3-1585L v5 | 31 May 2016 | $ 445.00 € 400.50 £ 360.45 ¥ 45,981.85 | Xeon E3 | Skylake H | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 3 GHz 3,000 MHz 3,000,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | Iris Pro Graphics P580 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||
| Count: 104 | |||||||||||||||||||||||||
References[edit]
- 2014 Intel Developer Forum in San Francisco, September 9, 2014
- Julius Mandelblat, Senior Principal Engineer, Lead Architect, 2015 IDF in San Francisco, Session SPCS001 ("Technology Insight: Intel’s Next Generation Microarchitecture Code Name Skylake"), August 18, 2015
- Efraim Rotem, Senior Principal Engineer, Lead Client Power Architect, 2015 IDF in San Francisco, Session ARCS001 ("Intel® Architecture, Code Name Skylake Deep Dive: A New Architecture to Manage Power Performance and Energy Efficiency"), August 18, 2015
- David Blythe, Intel Fellow and Chief Graphics Software Architect, 2015 IDF in San Francisco, Session SPCS003 ("Technology Insight: Next Generation Intel® Processor Graphics Architecture, Code Name Skylake"), August 18, 2015
- Dan Ragland, Overclocking System Architect, 2015 IDF, in San Francisco, Session RPCS001 ("Overclocking 6th Generation Intel® Core™ Processors!"), August 18, 2015
- Jack Doweck, Intel, Hot Chips 28, 2016
- Fayneh, Eyal, et al. "4.1 14nm 6th-generation Core processor SoC with low power consumption and improved performance." Solid-State Circuits Conference (ISSCC), 2016 IEEE International. IEEE, 2016.
Documents[edit]
- 6th Gen Intel® Core™ Mobile Processor Family: Platform Brief
- 6th Gen Intel® Core™ processor family and Intel® Xeon® processors Factsheet
- 6th Gen Intel® Core™ Processors: Y-series, U-series, and H-series Product Brief
- 6th Gen Intel® Core™ vPro™ Processor Family Product Brief
- 6th Generation Intel® Core™ Desktop Processors i7-6700K and i5-6600K Product Brief
- Overclocking 6th Generation Intel® Core™ Processors
- Technology Insight Intel’s Next Generation Microarchitecture Code Name Skylake
- Intel Architecture, Code Name Skylake Deep Dive- A New Architecture to Manage Power Performance and Energy Efficiency
See also[edit]
- AMD Zen
| codename | Skylake (client) + |
| core count | 2 + and 4 + |
| designer | Intel + |
| first launched | August 5, 2015 + |
| full page name | intel/microarchitectures/skylake (client) + |
| instance of | microarchitecture + |
| instruction set architecture | x86-64 + |
| manufacturer | Intel + |
| microarchitecture type | CPU + |
| name | Skylake (client) + |
| pipeline stages (max) | 19 + |
| pipeline stages (min) | 14 + |
| process | 14 nm (0.014 μm, 1.4e-5 mm) + |