Semiconductor & Computer Engineering
(→Architecture) |
(fix link) |
||
| (152 intermediate revisions by 14 users not shown) | |||
| Line 1: | Line 1: | ||
| − | {{intel title|Sandy Bridge|arch}} | + | {{intel title|Sandy Bridge (client)|arch}} |
{{microarchitecture | {{microarchitecture | ||
| − | | atype | + | |atype=CPU |
| − | | name | + | |name=Sandy Bridge (client) |
| − | | designer | + | |designer=Intel |
| − | | manufacturer | + | |manufacturer=Intel |
| − | | introduction | + | |introduction=September 13, 2010 |
| − | | phase-out | + | |phase-out=November, 2012 |
| − | | process | + | |process=32 nm |
| + | |cores=2 | ||
| + | |cores 2=4 | ||
| + | |type=Superscalar | ||
| + | |type 2=Superpipeline | ||
| + | |oooe=Yes | ||
| + | |speculative=Yes | ||
| + | |renaming=Yes | ||
| + | |stages min=14 | ||
| + | |stages max=19 | ||
| + | |decode=4-way | ||
| + | |isa=x86-64 | ||
| + | |predecessor=Westmere | ||
| + | |predecessor link=intel/microarchitectures/westmere | ||
| + | |predecessor 2=NetBurst | ||
| + | |predecessor 2 link=intel/microarchitectures/netburst | ||
| + | |successor=Ivy Bridge | ||
| + | |successor link=intel/microarchitectures/ivy bridge | ||
| + | |contemporary=Sandy Bridge (server) | ||
| + | |contemporary link=intel/microarchitectures/sandy bridge (server) | ||
| + | }} | ||
| + | '''Sandy Bridge''' ('''SNB''') '''Client Configuration''', formerly '''Gesher''', is [[Intel]]'s successor to {{\\|Westmere}}, a [[32 nm process]] [[microarchitecture]] for mainstream workstations, desktops, and mobile devices. Sandy Bridge is the "Tock" phase as part of Intel's {{intel|Tick-Tock}} model which added a significant number of enhancements and features. The microarchitecture was developed by Intel's R&D center in [[wikipedia:Haifa, Israel|Haifa, Israel]]. | ||
| + | |||
| + | For desktop and mobile, Sandy Bridge is branded as 2nd Generation Intel {{intel|Core i3}}, {{intel|Core i5}}, {{intel|Core i7}} processors. For workstations it's branded as first generation {{intel|Xeon E3}}. | ||
| + | |||
| + | == Etymology == | ||
| + | [[File:intel gesher.jpg|left|150px]] | ||
| + | ''Sandy Bridge'' was originally called ''Gesher'' which literally means "bridge" in Hebrew. The name was requested to be changed by upper management after a meeting between the development group and analysts brought up that it might be a bad idea to be associated with a failed Israeli political party that was eventually dissolved. | ||
| + | |||
| + | The name ''Sandy Bridge'' consists of the English translation of "Gesher" with "Sandy" possible referring to the fact that silicon comes from sand. | ||
| − | + | The Logo on the left was Intel's original ("Gesher") logo for the microarchitecture. | |
| − | + | {{clear}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
== Codenames == | == Codenames == | ||
| − | {{ | + | {| class="wikitable" |
| + | |- | ||
| + | ! Core !! Abbrev !! Target | ||
| + | |- | ||
| + | | {{intel|Sandy Bridge M|l=core}} || SNB-M || Mobile processors | ||
| + | |- | ||
| + | | Sandy Bridge || SNB || Desktop performance to value, AiOs, and minis | ||
| + | |- | ||
| + | | {{intel|Sandy Bridge E|l=core}} || SNB-E || Workstations & entry-level servers | ||
| + | |} | ||
| + | |||
| + | == Brands == | ||
| + | |||
| + | {| class="wikitable tc4 tc5 tc6 tc7" style="text-align: center;" | ||
| + | |- | ||
| + | ! rowspan="2" | Logo !! rowspan="2" | Family !! rowspan="2" | General Description !! colspan="7" | Differentiating Features | ||
| + | |- | ||
| + | ! Cores !! {{intel|Hyper-Threading|HT}} !! {{x86|AVX}} !! {{x86|AES}} !! [[IGP]] !! {{intel|Turbo Boost|TBT}} !! [[ECC]] | ||
| + | |- | ||
| + | | rowspan="2" | [[File:intel celeron (2009).png|60px|link=intel/celeron]] || rowspan="2" | {{intel|Celeron}} || style="text-align: left;" rowspan="2" | Entry-level Budget || [[1 cores|1]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|some}} || {{tchk|no}} || {{tchk|some}} | ||
| + | |- | ||
| + | | [[2 cores|2]] || {{tchk|no}} || {{tchk|yes}} || {{tchk|some}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|some}} | ||
| + | |- | ||
| + | | [[File:intel pentium (2009).png|60px|link=intel/pentium_(2009)]] || {{intel|Pentium (2009)|Pentium}} || style="text-align: left;" | Budget || [[2 cores|2]] || {{tchk|some}} || {{tchk|yes}} || {{tchk|some}} || {{tchk|some}} || {{tchk|no}} || {{tchk|some}} | ||
| + | |- | ||
| + | | [[File:intel core i3 logo (2012).svg|60px|link=intel/core_i3]] || {{intel|Core i3}} || style="text-align: left;" | Low-end Performance || [[2 cores|2]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|some}} || {{tchk|some}} || {{tchk|no}} || {{tchk|some}} | ||
| + | |- | ||
| + | | rowspan="2" | [[File:intel core i5 logo (2012).svg|60px|link=intel/core_i5]] || rowspan="2" | {{intel|Core i5}} || style="text-align: left;" rowspan="2" | Mid-range Performance || [[2 cores|2]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | [[4 cores|4]] || {{tchk|no}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|some}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | rowspan="3" | [[File:core i7 logo (2011).png|60px|link=intel/core_i7]] || rowspan="3" | {{intel|Core i7}} || style="text-align: left;" rowspan="3" | High-end Performance || [[2 cores|2]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | [[4 cores|4]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|some}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | [[6 cores|6]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | rowspan="2" | [[File:core i7ee logo (2011).png|60px|link=intel/core i7 ee]] || rowspan="2" | {{intel|Core i7EE}} || style="text-align: left;" rowspan="2" | Enthusiasts/High-end Performance || [[4 cores|4]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |- | ||
| + | | [[6 cores|6]] || {{tchk|yes}} || {{tchk|yes}} || {{tchk|yes}} || {{tchk|no}} || {{tchk|yes}} || {{tchk|no}} | ||
| + | |} | ||
| + | |||
| + | == Process Technology == | ||
| + | [[File:sandy bridge wafer.jpg|right|thumb|300px|Sandy Bridge Wafer]] | ||
| + | {{further|intel/microarchitectures/westmere#Process_Technology|l1=Westmere § Process Technology}} | ||
| + | Sandy Bridge uses the same [[32 nm process]] used for the Westmere microarchitecture for all mainstream consumer parts. | ||
| + | |||
| + | == Compatibility == | ||
| + | {| class="wikitable" | ||
| + | ! Vendor !! OS !! Version !! Notes | ||
| + | |- | ||
| + | | rowspan="3" | [[Microsoft]] || rowspan="3" | Windows || {{tchk|yes|Windows XP}} | ||
| + | |- | ||
| + | | {{tchk|yes|Windows Vista}} | ||
| + | |- | ||
| + | | {{tchk|yes|Windows 7}} | ||
| + | |- | ||
| + | | Linux || Linux || {{tchk|yes|Kernel}} ? || Initial Support | ||
| + | |} | ||
| + | |||
| + | == Compiler support == | ||
| + | {| class="wikitable" | ||
| + | |- | ||
| + | ! Compiler !! Arch-Specific || Arch-Favorable | ||
| + | |- | ||
| + | | [[ICC]] || <code>-march=sandybridge</code> || <code>-mtune=sandybridge</code> | ||
| + | |- | ||
| + | | [[GCC]] || <code>-march=sandybridge</code> || <code>-mtune=sandybridge</code> | ||
| + | |- | ||
| + | | [[LLVM]] || <code>-march=sandybridge</code> || <code>-mtune=sandybridge</code> | ||
| + | |- | ||
| + | | [[Visual Studio]] || <code>/arch:AVX</code> || <code>/tune:sandybridge</code> | ||
| + | |} | ||
| + | |||
| + | === CPUID === | ||
| + | {| class="wikitable tc1 tc2 tc3 tc4" | ||
| + | ! Core !! Extended<br>Family !! Family !! Extended<br>Model !! Model | ||
| + | |- | ||
| + | | rowspan="2" | {{intel|Sandy Bridge M|M|l=core}} || 0 || 0x6 || 0x2 || 0xA | ||
| + | |- | ||
| + | | colspan="4" | Family 6 Model 42 | ||
| + | |} | ||
== Architecture == | == Architecture == | ||
| − | {{ | + | Sandy Bridge features an entirely new architecture with a brand new core design which is both more highly performing and power efficient. The front-end has been entirely redesigned to incorporate a new decoded pipeline using a new µOP cache. The back-end is an entirely new PRF-based renaming architecture with a considerably large parallelism window. Sandy Bridge also provides considerable higher integration versus its {{intel|microarchitectures|predecessors}} resulting a full [[system on a chip]] design. |
=== Key changes from {{\\|Westmere}} === | === Key changes from {{\\|Westmere}} === | ||
| + | [[File:sandy bridge buffer window.png|right|350px]] | ||
| + | * Entirely brand new microarchitecture | ||
| + | * New client ring architecture | ||
| + | * New last level cache architecture | ||
| + | ** Multi-bank LLC/Agent architecture | ||
| + | ** 4x the bandwidth | ||
| + | * New {{intel|System Agent}} architecture | ||
| + | ** New power management unit | ||
| + | ** New SVID (Serial Voltage ID bus) | ||
| + | ** {{intel|PECI}} entirely re-architected | ||
| + | * Chipset | ||
| + | ** {{intel|Ibex Peak|l=chipset}} → {{intel|Cougar Point}} | ||
| + | ** {{intel|Socket H}} (LGA-1156) → {{intel|Socket H2}} (LGA-1155) | ||
| + | * Core | ||
| + | ** Entirely redesigned | ||
| + | ** Front-end | ||
| + | *** New µOP cache | ||
| + | *** Redesigned branch prediction | ||
| + | **** Higher accuracy | ||
| + | **** BTB is now a single-level design (from two-level) | ||
| + | *** Instruction Queue | ||
| + | **** Increased to 20 entries/thread (from 18 entries, shared) | ||
| + | **** Improved [[macro-op fusion]] (covers almost all jump with most arithmetic now) | ||
| + | ** Back-end | ||
| + | *** Brand new back-end using PRF-based renaming (from a RRF-based) | ||
| + | *** ReOrder Buffer (ROB) | ||
| + | **** New design and entirely different functionality (only used to track in-flight micro-ops) | ||
| + | **** Increased to 168 entries (from 128) | ||
| + | **** New Zeroing Idioms optimizations | ||
| + | **** New Onces Idioms optimizations | ||
| + | *** Scheduler | ||
| + | **** Larger buffer (54-entry, up from 26) | ||
| + | **** Execution Units | ||
| + | ***** Ports rebalanced | ||
| + | ***** 256-bit operations (from 128-bit) | ||
| + | ***** Double FLOP/cycle | ||
| + | ***** AES operations enhanced | ||
| + | ** Memory Subsystem | ||
| + | *** L1I$ change to 8-way (from 4-way) | ||
| + | *** Proper support for 1 GiB pages with 4-entry 1 GiB page DTLB (from 0) | ||
| + | *** Double load throughput; 2 loads/cycle (from 1) | ||
| + | *** AGUs can now do both loads and stores | ||
| + | *** 33% larger load buffer (64 entries from 48) | ||
| + | *** larger store buffer (36 entries from 32) | ||
| + | * Integrated Graphics | ||
| + | ** Integrated graphics is now integrated on the same die (previously was on a second die) | ||
| + | ** Dropped {{intel|QPI}} controller which linked the two dies | ||
| + | ** Improved performance and media capabilities | ||
| + | ** On a 32 nm process, same die as the cores (from 45 nm) | ||
| + | ** Embedded Display Port (eDP) is now on a dedicated port (from sharing pins with PCIe interface) | ||
| + | * Integrated PCIe Controller | ||
| + | * Integrated Memory Controller | ||
| + | ** Integrated on-die is now integrated on the same die (previously was on a second die) | ||
| + | ** Dropped {{intel|QPI}} controller which linked the two dies | ||
| + | * Testability | ||
| + | ** Integrates {{intel|Generic Debug eXternal Connection}} (GDXC) | ||
| + | |||
| + | ====New instructions ==== | ||
| + | Sandy Bridge introduced a number of {{x86|extensions|new instructions}}: | ||
| + | |||
| + | * {{x86|AVX|<code>AVX</code>}} - Advanced Vector Extensions | ||
| + | |||
| + | === Block Diagram === | ||
| + | ==== Entire SoC Overview (dual) ==== | ||
| + | [[File:sandy bridge soc block diagram (dual).svg|800px]] | ||
| + | |||
| + | ==== Entire SoC Overview (quad) ==== | ||
| + | [[File:sandy bridge soc block diagram.svg|900px]] | ||
| + | |||
| + | ==== Individual Core ==== | ||
| + | [[File:sandy bridge block diagram.svg|900px]] | ||
| + | |||
| + | ==== Gen6 ==== | ||
| + | See {{intel|Gen6#Gen6|l=arch}}. | ||
| + | |||
| + | === Memory Hierarchy === | ||
| + | The memory subsystem has been reworked in Sandy Bridge. | ||
| + | |||
| + | * Cache | ||
| + | ** L0 µOP cache: | ||
| + | *** 1,536 µOPs, 8-way set associative | ||
| + | **** 32 sets, 6-µOP line size | ||
| + | **** statically divided between threads, per core, inclusive with L1I$ | ||
| + | ** L1I Cache: | ||
| + | *** 32 [[KiB]], 8-way set associative | ||
| + | **** 64 sets, 64 B line size | ||
| + | **** shared by the two threads, per core | ||
| + | ** L1D Cache: | ||
| + | *** 32 KiB, 8-way set associative | ||
| + | *** 64 sets, 64 B line size | ||
| + | *** shared by the two threads, per core | ||
| + | *** 4 cycles for fastest load-to-use (simple pointer accesses) | ||
| + | **** 5 cycles for complex addresses | ||
| + | *** 32 B/cycle load bandwidth | ||
| + | *** 16 B/cycle store bandwidth | ||
| + | *** Write-back policy | ||
| + | ** L2 Cache: | ||
| + | *** Unified, 256 KiB, 8-way set associative | ||
| + | *** 1024 sets, 64 B line size | ||
| + | *** Non-inclusive | ||
| + | *** 12 cycles for fastest load-to-use | ||
| + | *** 32 B/cycle bandwidth to L1$ | ||
| + | *** Write-back policy | ||
| + | ** L3 Cache/LLC: | ||
| + | *** Up to 2 MiB Per core, shared across all cores | ||
| + | *** Up to 16-way set associative | ||
| + | *** Inclusive | ||
| + | *** 64 B line size | ||
| + | *** Write-back policy | ||
| + | *** Per each core: | ||
| + | **** Read: 32 B/cycle (@ ring [[clock]]) | ||
| + | **** Write: 32 B/cycle (@ ring clock) | ||
| + | *** 26-31 cycles latency | ||
| + | ** System [[DRAM]]: | ||
| + | *** 2 Channels | ||
| + | *** 8 B/cycle/channel (@ memory clock) | ||
| + | *** Up to DDR3-1600 | ||
| + | |||
| + | Sandy Bridge [[TLB]] consists of dedicated L1 TLB for instruction cache (ITLB) and another one for data cache (DTLB). Additionally there is a unified L2 TLB (STLB). | ||
| + | * TLBs: | ||
| + | ** ITLB | ||
| + | *** 4 KiB page translations: | ||
| + | **** 128 entries; 4-way set associative | ||
| + | **** dynamic partitioning | ||
| + | *** 2 MiB / 4 MiB page translations: | ||
| + | **** 8 entries per thread; fully associative | ||
| + | **** Duplicated for each thread | ||
| + | ** DTLB | ||
| + | *** 4 KiB page translations: | ||
| + | **** 64 entries; 4-way set associative | ||
| + | **** fixed partition | ||
| + | *** 2 MiB / 4 MiB page translations: | ||
| + | **** 32 entries; 4-way set associative | ||
| + | **** fixed partition | ||
| + | *** 1G page translations: | ||
| + | **** 4 entries; fully associative | ||
| + | **** fixed partition | ||
| + | ** STLB | ||
| + | *** 4 KiB page translations: | ||
| + | **** 512 entries; 4-way set associative | ||
| + | **** fixed partition | ||
| + | *** ITLB miss and a STLB hit is 7 cycles | ||
| + | |||
| + | ==Overview == | ||
| + | [[File:sandy bridge overview.svg|right|450px]] | ||
| + | Sandy Bridge was an entirely new microarchitecture which combines some of the improvements that were implemented in {{\\|NetBurst}} along with the original {{\\|P6}} design. In addition to the new core design, Sandy Bridge took full advantage of Intel's [[32 nm process]] which enabled the integration all the components of the chip on a single monolithic die, including the [[integrated graphics]] and the [[integrated memory controller]]. Sandy Bridge is the first Intel microarchitecture designed as a true [[system on a chip]] for high-volume client mainstream market. Previously (e.g., {{\\|Nehalem}}) the integrated graphics and the memory interface were fabricated on a separate die which was packaged together and communicated over Intel's {{intel|QuickPath Interconnect}} (QPI). The seperate dies were then packaged together as a [[system on a package]]. | ||
| + | |||
| + | As stated earlier, the individual cores are an entirely new design which improved both performance and power. Sandy Bridge introduced a number of performance features that brought better-than-linear performance/power as well as a number of enhancements that improved performance while saving power. Intel introduced a number of new vector computation ([[SIMD]]) and security instructions which improved [[floating point]] performance and throughput as well as speedup the throughput of various encryption algorithms. Sandy Bridge incorporates either two or four [[physical cores]] with either four or eight [[logical cores]]. | ||
| + | |||
| + | The block diagram on the right is a complete [[quad-core]] Sandy Bridge SoC which integrates the new {{intel|System Agent}} (SA), the four [[physical cores]] along with their companion [[last level cache]] (LLC) slices, and the integrated graphics. Interconnecting everything is a complex high-bandwidth low-latency ring on-die which consists of six agents - one for each core and cache slice, one for the system agent, and one for the graphics. The upper portion of the diagram is the {{intel|System Agent}} (SA) which incorporates the display controller, the memory controller, and the various I/O interfaces. Previously that component was referred to as the [[Memory Controller Hub]] (MCH) when on a separate die. Sandy Bridge incorporates 20 [[PCIe]] 2.0 lanes - x4 are used by the {{intel|DMI}} with the other x16 lanes designed for a dedicated GPU. The memory controller supports up to dual-channel DDR3-1600 (depending on model). | ||
| + | |||
| + | == System Architecture == | ||
| + | [[File:sandy bridge ring scalability.svg|right|200px]] | ||
| + | Sandy Bridge was designed with configurability (i.e. modularity) scalability as the primary system goals. With the full integration of the graphics and memory controller hub on-die Intel needed a new way to efficiently interconnect all the individual components. Modularity was a major design goal for Sandy Bridge. Intel wanted to be able to design the cores and the graphics independently of the rest of the system and be able to detach the graphics and added more cores as desired. | ||
| + | |||
| + | The scalability goal was important for Intel's {{\\|Sandy Bridge (server)|server configuration}} where the graphics are dropped and more cores can be added to the ring without compromising performance. Sandy Bridge comprised of a fairly robust ring implementation with bandwidth that can scale to more cores as necessary. | ||
| + | |||
| + | === Cache Architecture === | ||
| + | As part of the entire system overhaul, the cache architecture has been streamlined and was made more scalable. Sandy Bridge features a high-bandwidth [[last level cache]] which is shared by all the [[physical core|cores]] as well as the [[integrated graphics]] and the [[system agent]]. The LLC is an inclusive multi-bank cache architecture that is tightly associative with the individual cores. Each core is paired with a "slice" of LLC which is 2 [[MiB]] in size (lower amount for lower-end models). This pairing of cores and cache slices scales with the number of cores which provides a significant performance boost while saving power and bandwidth. Partitioning the data also helps simplify coherency as well as reducing localized contentions and hot spots. | ||
| + | |||
| + | Sandy Bridge is Intel's first microarchitecture to integrate the graphics on-die. One of the key enablers for this feature is the new cache architecture. Conceptually, the integrated graphics is treated just like another core. The graphics itself can decide which of its buffers (e.g., display or textures) will sit in the LLC and be coherent. Because it's possible for the graphics to use large amounts of memory, the possibility of [[cache thrashing|thrashing]] had to be addressed. A Special mechanism has been implemented inside the cache in order to prevent thrashing. In order to prevent the graphics from flushing out all the core's data, that mechanism is capable of capping how much of the cache will be dedicated to the cores and how much will be dedicated to the graphics. | ||
| + | |||
| + | The last level cache is an inclusive cache with a 64 byte cache line organized as 16-way set associative. Each LLC slice is accessible to all cores. With up to 2 MiB per slice per core, a four-core model will sport a total of 8 MiB. Lower-end/budget models feature a smaller cache slice. This is done by disabling ways of cache in 4-way increments (for a granularity of 512 KiB). The LLC to use latency in Sandy Bridge has been greatly improved from 35-40+ in {{\\|Nehalem}} to 26-31 cycles (depending on ring hops). | ||
| + | |||
| + | ==== Cache Box ==== | ||
| + | Within each cache slice is cache box. The cache box is the controller and agent serving as the interface between the LLC and the rest of the system (i.e., cores, graphics, and system agent). The cache box implements the ring logic and the address hashing and arbitration. It is also tasked with communicating with the {{intel|System Agent}} on cache misses, non-cacheable accesses (such as in the case of I/O pulls), as well as external I/O [[snoop]] requests. The cache box is fully pipelined and is capable of working on multiple requests at the same time. Agent requests (e.g., ones from the GPU) are handled by the individual cache boxes via the ring. This is much different to how it was previously done in {{\\|Westmere}} where a single unified cache handled everything. The distribution of slices allows Sandy Bridge to have higher associativity bandwidth while reducing traffic. | ||
| + | |||
| + | The entire physical address space is mapped distributively across all the slices using a [[hash function]]. On a [[cache miss|miss]], the core needs to decode the address to figure out which slice ID to request the data from. Physical addresses are hashed at the source in order to prevent hot spots. The cache box is responsible for the maintaining of coherency and ordering between requests. Because the LLC slices are fully inclusive, it can make efficienct use of an on-die snoop filter. Each slice makes use of {{intel|Core Valid Bits}} (CVB) which is used to eliminate unnecessary snoops to the cores. A single bit per cache line is needed to indicate if the line may be in the core. Snoops are therefore only needed if the line is in the LLC and a CVB is asserted on that line. This mechanism helps limits external snoops to the cache box most of the time without resorting to going to the cores. | ||
| + | |||
| + | Note that both the cache slices and the cache boxes reside within the same [[clock domain]] as the cores themselves - sharing the same voltage and frequency and scaling along with the cores when needed. | ||
| + | |||
| + | ===== Logic design techniques ===== | ||
| + | [[File:sandy bridge vcc min improvements.png|right|300px|thumb|The graph which was provided by Intel during [[ISSCC]] demonstrates the [[Vcc]] min reduction after those technique have been applied to the circuits.]] | ||
| + | One of the new challenges that Sandy Bridge presented is a consequence of the shared [[power plane]] that spans the [[physical core|cores]] and the [[L3 cache]]. Using standard design, the minimum voltage required to keep the L3 cache data alive may limit the minimum operating voltage of the cores. This would consequently adversely affect the average power of the system. In previous designs, this issue could be solved by moving the L3 to its own dedicated power plane that operated at a higher voltage. However, this solution would've substantially increased the power dissipation of the L3 cache and since Sandy Bridge incorporated as much as 8 MiB of L3 for the higher-end quad-core models, this impact would have accounted for a big fraction of die's overall power consumption. Intel used several logic design techniques to minimize the minimum voltage of the L3 cache and the [[register file]] to allow it to operate at a lower level than the core logic. | ||
| + | |||
| + | [[File:sandy bridge register file shared strength and post silicon tuning.png|left|300px]] | ||
| + | Shown here is a schematic of one of the techniques that were used in the [[register file]] in order to lower the minimum Vcc Min voltage. Intel noted that fabrication variations can cause write-ability degradation at low voltages - such as in the case where TP comes out stronger than TN. This method addresses the issue caused by a strong TP by weakening the memory cell pull-up device effective strength. Note the three parallel [[transistors]] on the very right side of the schematic (inside the square box) labeled T1, T2, and T3. The effective size of the shared [[PMOS]] is set during [[post-silicon]] production testing by enabling and disabling any combination of the three parallel transistors to achieve the desired result. | ||
| + | |||
| + | === Ring Interconnect === | ||
| + | In the pursuit of modularity, Sandy Bridge incorporates a new and robust high-bandwidth coherent interconnect that links all the separate components together. The ring is a system of interconnects between the [[physical core|cores]], the [[integrated graphics|graphics]], the [[last level cache]], and the {{intel|System Agent}}. The ring allows Intel to scale up and down efficiently depending on the market segmentation which allows for finer balance of performance, power, and cost. The choice to use a ring makes design and validation easier compared to some of the more complex typologies such as [[packet routing]]. It's also easier configurability-wise. The concept design for a ring architectural started with the {{\\|Nehalem}}-EX server architecture which had eight cores and needed greater bandwidth. When design for the Sandy Bridge client architecture started, Intel realized they needed similar behavior and similar bandwidth to feed the new larger cores and the memory-intensive on-die GPU which could use more bandwidth than all four cores combined. | ||
| + | |||
| + | Internally, the ring is composed of four physical independent rings which handle the communication and enforce coherency. | ||
| + | |||
| + | * 32-byte Data ring | ||
| + | * Request ring | ||
| + | * Acknowledge ring | ||
| + | * Snoop ring | ||
| + | |||
| + | [[File:sandy bridge ring flow.svg|right|275px]] | ||
| + | The four rings consists of a considerable amount of wiring and routing. Because the routing runs in the upper metal layers over the LLC, the rings have no real impact on die area. As with the LLC slices, the ring is fully pipelined and operates within the core's [[clock domain]] as it scales with the frequency of the core. The bandwidth of the ring also scales in bandwidth with each additional core/$slice pair that is added onto the ring, however with more cores the ring becomes more congested and adding latency as the average hop count increases. Intel expected the ring to support a fairly large amount of cores before facing real performance issues. | ||
| + | |||
| + | It's important to note that the term ring refers to its structure and not necessarily how the data flows. The ring is not a round-robin and requests may travel up or down as needed. The use of address hashing allows the source agent to know exactly where the destination is. In order reduce latency, the ring is designed such as that all accesses on the ring always picks the shortest path. Because of this aspect of the ring and the fact that some requests can take longer than others to complete, the ring might have requests being handled out of order. It is the responsibility of the source agents to handle the ordering requirements. The ring [[cache coherency]] protocol is largely an enhancement based on Intel's {{intel|QuickPath Interconnect|QPI}} protocols with [[MESI]]-based source snooping protocol. On each cycle, the agents receive an indication whether there is an available slot on the ring for communication in the next cycle. When asserted, the agent can sent any type of communication (e.g. data or snoop) on the ring the following cycle. | ||
| + | |||
| + | The data ring is 32 bytes meaning each slice can pass half a cache line to the ring each cycle. This means that a [[dual-core]] operating at 4 GHz on both cores will have a total bandwidth of 256 GB/s with each connection having a bandwidth of 128 GB/s. | ||
| + | |||
| + | === System Agent === | ||
| + | {{main|intel/system agent|l1=Intel's System Agent}} | ||
| + | The System Agent (SA) is a centralized peripheral device integration unit. It contains what was previously the traditional [[Memory Controller Hub]] (MCH) which includes all the I/O such as the [[PCIe]], {{intel|DMI}}, and others. Additionally the SA incorporates the [[memory controller]] and the display engine which works in tandem with the integrated graphics. The major enabler for the new System Agent is in fact the [[32 nm process]] which allowed for considerably higher integration, over a dozen [[clock domain]]s and [[PHY]]s. | ||
| + | |||
| + | The System Agent interfaces with the rest of the system via the ring in a similar manner to the cache boxes in the LLC slices. It is also in charge of handling I/O to cache coherency. The System Agent enables [[direct memory access]] (DMA), which allows devices to snoop the cache hierarchy. Address conflicts resulting from multiple concurrent requests associated with the same cache line are also handled by the System Agent. | ||
| + | |||
| + | [[File:sandy bridge power overview.svg|275px|left]] | ||
| + | It should be pointed out the with Sandy Bridge, only a single [[reference clock]] is fed into the System Agent. From there are, signals are [[clock multiplier|multiplied]] and distribute the clocks across the entire system using set of [[PLL]]s locked onto the reference signal. | ||
| + | |||
| + | ==== <span style="float: right;">Power</span> ==== | ||
| + | With Sandy Bridge, Intel introduced a large number of power features to save powers depending on the workload, temperature, and what I/O is being utilized. The new power features are handled at the System Agent. Sandy Bridge introduced a fully-fledged Power Control Unit (PCU). The root concept for this unit started with {{\\|Nehalem}} which embedded a discrete microcontroller on-die which handled all the power management related tasks in firmware. The new PCU extends on this functionality with numerous state machines and firmware algorithms. The use of firmware, which Intel Fellow Opher Kahn described at IDF 2010, contains 1000s of lines of code to handle very complex power management tasks. Intel uses firmware to be able to fine-tune chips post-silicon as well as fix problems to extract the best performance. | ||
| + | |||
| + | Sandy Bridge has three separate voltage domains: System Agent, Cores, and Graphics. Both the Cores and Graphics are variable voltage domains. Both of those domains are able to scale up and down with voltage and frequency based on controls from the Power Control Unit. The cores and graphics scale up and down depending on the workloads in order to deliver instantaneous performance boost through higher frequency whenever possible. The System Agent sits on a third power plane which is low voltage (especially on mobile devices) in order to consume as little power as necessary. | ||
| + | |||
| + | == Core == | ||
| + | Sandy Bridge can be considered the first brand new microarchitecture since the introduction of {{\\|NetBurst}} and {{\\|P6}} prior. Sandy Bridge went back to the drawing board and incorporated many of beneficial elements from {{\\|P6}} as well as {{\\|NetBurst}}. While NetBurst ended up being a seriously flawed architecture, its design was driven by a number of key innovations which were re-implemented and enhanced in Sandy Bridge. This is different from earlier architectures (i.e., {{\\|Core}} through {{\\|Nehalem}}) which were almost exclusively enhancements of {{\\|P6}} with nothing inherited from P4. Every aspect of the core was improved over its predecessors with very functional block being improved. | ||
| + | |||
| + | [[File:intel uarch evolution p5 to sandy.svg|1300px]] | ||
| + | |||
| + | === Pipeline === | ||
| + | The Sandy Bridge core focuses on extracting performance and reducing power in a great number of ways. Intel placed heavy emphasis in the cores on performance enhancing features that can provide more-than-linear performance-to-power ratio as well as features that provide more performance while reducing power. The various enhancements can be found in both the front-end and the back-end of the core. | ||
| + | |||
| + | ==== Broad Overview ==== | ||
{{empty section}} | {{empty section}} | ||
| + | |||
| + | ==== Front-end ==== | ||
| + | The front-end is tasked with the challenge of fetching the complex [[x86]] instructions from memory, decoding them, and delivering them to the execution units. In other words, the front end needs to be able to consistently deliver enough [[µOPs]] from the [[instruction code stream]] to keep the back-end busy. When the back-end is not being fully utilized, the core is not reaching its full performance. A weak or under-performing front-end will directly affect the back-end, resulting in a poorly performing core. In the case of Sandy Bridge base, this challenge is further complicated by various redirections such as branches and the complex nature of the [[x86]] instructions themselves. | ||
| + | |||
| + | The entire front-end was redesigned from the ground up in Sandy Bridge. The four major changes in the front-end of Sandy Bridge is the entirely new [[µOP cache]], the overhauled branch predictor and further decoupling of the front-end, and the improved macro-op fusion capabilities. All those features not only improve performance but they also reduce power draw at the same time. | ||
| + | |||
| + | ===== Fetch & pre-decoding ===== | ||
| + | Blocks of memory arrive at the core from either the cache slice or further down [[#Ring_Interconnect|the ring]] from one of the other cache slice. On occasion, far less desirably, from main memory. On their first pass, instructions should have already been prefetched from the [[L2 cache]] and into the [[L1 cache]]. The L1 is a 32 [[KiB]], 64B line, 8-way set associative cache. The [[instruction cache]] is identical in size to that of {{\\|Nehalem}}'s but its associativity was increased to 8-way. Sandy Bridge fetching is done on a 16-byte fetch window. A window size that has not changed in a number of generations. Up to 16 bytes of code can be fetched each cycle. Note that the fetcher is shared evenly between two threads, so that each thread gets every other cycle. At this point they are still [[macro-ops]] (i.e. variable-length [[x86]] architectural instruction). Instructions are brought into the pre-decode buffer for initial preparation. | ||
| + | |||
| + | [[File:sandy bridge fetch.svg|left|300px]] | ||
| + | |||
| + | [[x86]] instructions are complex, variable length, have inconsistent encoding, and may contain multiple operations. At the pre-decode buffer the instructions boundaries get detected and marked. This is a fairly difficult task because each instruction can vary from a single byte all the way up to fifteen. Moreover, determining the length requires inspecting a couple of bytes of the instruction. In addition boundary marking, prefixes are also decoded and checked for various properties such as branches. As with previous microarchitectures, the pre-decoder has a [[throughput]] of 6 [[macro-ops]] per cycle or until all 16 bytes are consumed, whichever happens first. Note that the predecoder will not load a new 16-byte block until the previous block has been fully exhausted. For example, suppose a new chunk was loaded, resulting in 7 instructions. In the first cycle, 6 instructions will be processed and a whole second cycle will be wasted for that last instruction. This will produce the much lower throughput of 3.5 instructions per cycle which is considerably less than optimal. Likewise, if the 16-byte block resulted in just 4 instructions with 1 byte of the 5th instruction received, the first 4 instructions will be processed in the first cycle and a second cycle will be required for the last instruction. This will produce an average throughput of 2.5 instructions per cycle. Note that there is a special case for {{x86|length-changing prefix}} (LCPs) which will incur additional pre-decoding costs. Real code is often less than 4 bytes which usually results in a good rate. | ||
| + | |||
| + | ====== Branch Predictor ====== | ||
| + | The fetch works along with the [[branch prediction unit]] (BPU) which attempts to guess the flow of instructions. All branches utilize the BPU for their predictions, including [[return statements|returns]], indirect calls and jumps, direct calls and jumps, and conditional branches. As with almost every iteration of Intel's microarchitecture, the [[branch predictor]] has also been improved. An improvement to the branch predictor has the unique consequence of directly improving both performance and power efficiency. Due to the deep pipeline, a flush is a rather expensive event which ends up discarding over 150 instructions that are in-flight. One of the big changes that was done in {{\\|Nehalem}} and was carried over into Sandy Bridge is the further decoupling of the BPU between the front-end and the back-end. Prior to Nehalem, the entire pipeline had to be fully flushed before the front-end could resume operations. This was redone in Nehalem and the front-end can start decoding right away as soon as the correct path become known - all while the back-end is still flushing the badly speculated µOPs. This results in a reduced penalty (i.e. lower latency) for wrong target prediction. In addition, a large portion of the branch predictor in Sandy Bridge was actually entirely redesigned. The branch predictor incorporates the same mechanisms found in Nehalem: Indirect Target Array (ITA), the branch target buffer (BTB), Loop Detector (LD), and the renamed return stack buffer (RSB). | ||
| + | |||
| + | For near returns, Sandy Bridge has the same 16-entry return stack buffer. The BTB in Sandy Bridge is a single level structure that holds twice as many entries as {{\\|Nehalem}}'s L1/2 BTBs. This change should result increase the prediction coverage. It's interesting to note that prior to {{\\|Nehalem}}, Intel previously used a single-level design in {{\\|Core}}. This is done through compactness. Since most branches do not need nearly as many bits per branch, for larger displacements, a separate table is used. Sandy Bridge appears to have a BTB table with 4096 targets, same as {{\\|NetBurst}}, which is organized as 1024 sets of 4 ways. | ||
| + | |||
| + | The global branch history table was not increased with Sandy Bridge, but was enhanced by removing certain branches from history that did not improve predictions. Additionally the unit features retains longer history for data dependent behaviors and has more effective history storage. | ||
| + | |||
| + | ====== Instruction Queue & MOP-Fusion ====== | ||
| + | {| style="border: 1px solid gray; float: right; margin: 10px; padding: 5px" | ||
| + | | [[MOP-Fusion]] Example: | ||
| + | |- | ||
| + | | | ||
| + | <pre>cmp eax, [mem] | ||
| + | jne loop</pre> | ||
| + | | '''→''' | ||
| + | | <pre>cmpjne eax, [mem], loop</pre> | ||
| + | |} | ||
| + | {{see also|Macro-Operation Fusion}} | ||
| + | The pre-decoded instructions are delivered to the Instruction Queue (IQ). In {{\\|Nehalem}}, the Instruction Queue has been increased to 18 entries which were shared by both threads. Sandy Bridge increased that number to 20 but duplicated over for each thread (i.e. 40 total entries). | ||
| + | |||
| + | One key optimization the instruction queue does is [[macro-op fusion]]. Sandy Bridge can fuse two [[macro-ops]] into a single complex one in a number of cases. In cases where a {{x86|test}} or {{x86|compare}} instruction with a subsequent conditional jump is detected, it will be converted into a single compare-and-branch instruction. With Sandy Bridge, Intel expanded the macro-op fusion capabilities further. Macro-fusion can now work with just about jump instruction such as <code>{{x86|ADD}}</code> and <code>{{x86|SUB}}</code>. This means that more new cases are now fusable. Perhaps the most important case is in most typical loops which have a counter followed by an exist condition. Those should now be fused. Those fused instructions remain fused throughout the entire pipeline and get executed as a single operation by the branch unit thereby saving bandwidth everywhere. Only one such fusion can be performed each cycle. | ||
| + | |||
| + | ===== Decoding ===== | ||
| + | [[File:sandy bridge decode.svg|right|350px]] | ||
| + | Up to four instructions (or five in cases where one of the instructions was macro-fused) pre-decoded instructions are sent to the decoders each cycle. Like the fetchers, the decoders alternate between the two threads each cycle. Decoders read in [[macro-operations]] and emit regular, fixed length [[µOPs]]. The decoders organization in Sandy Bridge has been kept more or less the same as {{\\|Nehalem}}. As with its predecessor, Sandy Bridge features four decodes. The decoders are asymmetric; the first one, Decoder 0, is a [[complex decoder]] while the other three are [[simple decoders]]. A simple decoder is capable of translating instructions that emit a single fused-[[µOP]]. By contrast, a [[complex decoder]] can decode anywhere from one to four fused-µOPs. Overall up to 4 simple instructions can be decoded each cycle with lesser amounts if the complex decoder needs to emit additional µOPs; i.e., for each additional µOP the complex decoder needs to emit, 1 less simple decoder can operate. In other words, for each additional µOP the complex decoder emits, one less decoder is active. | ||
| + | |||
| + | Sandy Bridge brought about the first 256-bit [[SIMD]] set of instructions called {{x86|AVX}}. This extension expanded the sixteen pre-existing 128-bit {{x86|XMM}} registers to 256-bit {{x86|YMM}} registers for floating point vector operations (note that {{\\|Haswell}} expanded this further to [[Integer]] operations as well). Most of the new AVX instructions have been designed as simple instructions that can be decoded by the simple decoders. | ||
| + | |||
| + | ====== MSROM & Stack Engine ====== | ||
| + | There are more complex instructions that are not trivial to be decoded even by complex decoder. For instructions that transform into more than four µOPs, the instruction detours through the [[microcode sequencer]] (MS) ROM. When that happens, up to 4 µOPs/cycle are emitted until the microcode sequencer is done. During that time, the decoders are disabled. | ||
| + | |||
| + | [[x86]] has dedicated [[stack machine]] operations. Instructions such as <code>{{x86|PUSH}}</code>, <code>{{x86|POP}}</code>, as well as <code>{{x86|CALL}}</code>, and <code>{{x86|RET}}</code> all operate on the [[stack pointer]] (<code>{{x86|ESP}}</code>). Without any specialized hardware, such operations would need to be sent to the back-end for execution using the general purpose ALUs, using up some of the bandwidth and utilizing scheduler and execution units resources. Since {{\\|Pentium M}}, Intel has been making use of a [[Stack Engine]]. The Stack Engine has a set of three dedicated adders it uses to perform and eliminate the stack-updating µOPs (i.e. capable of handling three additions per cycle). Instruction such as <code>{{x86|PUSH}}</code> are translated into a store and a subtraction of 4 from <code>{{x86|ESP}}</code>. The subtraction in this case will be done by the Stack Engine. The Stack Engine sits after the [[instruction decode|decoders]] and monitors the µOPs stream as it passes by. Incoming stack-modifying operations are caught by the Stack Engine. This operation alleviates the burden of the pipeline from stack pointer-modifying µOPs. In other words, it's cheaper and faster to calculate stack pointer targets at the Stack Engine than it is to send those operations down the pipeline to be done by the execution units (i.e., general purpose ALUs). | ||
| + | |||
| + | ===== New µOP cache & x86 tax ===== | ||
| + | [[File:sandy bridge ucache.svg|right|400px]] | ||
| + | Decoding the variable-length, inconsistent, and complex [[x86]] instructions is a nontrivial task. It's also expensive in terms of performance and power. Therefore, the best way for the pipeline to avoid those things is to simply not decode the instructions. This is exactly what Intel has done with Sandy Bridge and what's perhaps the single biggest feature that has been added to the core. With Sandy Bridge Intel introduced a new [[µOP cache]] unit or perhaps more appropriately called the Decoded Stream Buffer (DSB). The micro-op cache is unique in that it not only does substantially improve performance but it does so while significantly reducing power. | ||
| + | |||
| + | On the surface, the µOP cache can be conceptualized as a second instruction cache unit that is subset of the [[level one instruction cache]]. What's unique about it is that it stores actual decoded instructions (i.e., µOPs). While it shares many of the goals of {{\\|NetBurst}}'s [[trace cache]], the two implementations are entirely different, this is especially true as it pertains to how it augments the rest of the front-end. The idea behind both mechanisms is to increase the front-end bandwidth by reducing reliance on the decoders. | ||
| + | |||
| + | The micro-op cache is organized into 32 sets of 8 cache lines with each line holding up to 6 µOP for a total of 1,536 µOPs. The cache is competitively shared between the two threads and can also hold pointers to the [[microcode sequencer]] [[ROM]]. It's also virtually addressed and is a strict subset of the L1 instruction cache (that is, the L1 is inclusive of the µOP cache). Each line includes additional meta info for the number of contained µOP and their length. | ||
| + | |||
| + | At any given time, the core operates on a contiguous chunks of 32 bytes of the [[instruction stream]]. Likewise, the µOP cache operates on full 32 B windows as well. This is by design so that the µOP cache could store and evict entire windows based on a [[LRU]] policy. Intel refers to the traditional pipeline path as the "legacy decode pipeline". On initial iteration, all instructions go through the legacy decode pipeline. Once the entire stream window is decoded and makes its to the allocation queue, a copy of the window is inserted into the µOP cache. This occurs simultaneously with all other operations; i.e., no additional cycles or stages are added for this functionality. On all subsequent iterations, the cached pre-decoded stream is sent directly to the allocation queue - bypassing fetching, predecoding, and decoding of actual x86 instructions, saving power and increasing throughput. This is also a much shorter pipeline, so latency is reduced as well. | ||
| + | |||
| + | Note that a single stream window of 32 bytes can only span 3 ways with 6 µOPs per line; this means that a maximum of 18 µOPs per window can be cached by the µOP cache. This consequently means a 32 byte window that generates more than 18 µOPs will not be allocated in the µOP cache and will have to go through the legacy decode pipeline instead. However, such scenarios are fairly rare and most workloads do benefit from this feature. | ||
| + | |||
| + | The µOP cache has an average hit rate of around 80%. During the instruction fetch, the branch predictor will probe the µOPs cache tags. A hit in the cache allows for up to 4 µOPs (possibly fused macro-ops) per cycle to be sent directly to the Instruction Decode Queue (IDQ), bypassing all the pre-decoding and decoding that would otherwise have to be done. During those cycles, the rest of the front-end is entirely clock-gated which is how the substantial power saving is gained. Whereas the legacy decode path works in 16-byte instruction fetch windows, the µOP cache has no such restriction and can deliver 4 µOPs/cycle corresponding to the much bigger 32-byte window. Since a single window can be made of up to 18 µOPs, up to 5 whole cycles may be required to read out the entire decoded stream. Nonetheless, the µOPs cache can deliver consistently higher bandwidth than the legacy pipeline which is limited to the 16-byte fetch window and can be a serious [[bottleneck]] if the average instruction length is more than four bytes per window. | ||
| + | |||
| + | It's interesting to note that the µOPs cache only operates on full windows, that is, a full 32B window that has all the µOPs cached. Any partial hits are required to go through the legacy decode pipeline as if nothing was cached. The choice to not handle partial cache hits is rooted in this features efficiency. On partial window hits the core will end up emitting some µOPs from the micro-op cache as well as having the legacy decode pipeline decoding the remaining missed µOPs. Effectively multiple components will end up emitting µOPs. Not only would such mechanism increase complexity, but it's also unclear how much, if any, benefits would be gained by that. | ||
| + | |||
| + | As noted earlier, the µOPs cache has its root in the original {{\\|NetBurst}} trace cache, particularly as far as goals are concerned. But that's where the similarities end. The micro-op cache in Sandy Bridge can be seen as a light-weight, efficient µOPs delivery mechanism that can surpass the legacy pipeline whenever possible. This is different to the trace cache that attempted to effectively replace the entire front-end and use vastly inferior and slow fetch/decode for workloads that the trace cache could not handle. It's worth noting that the trace cache was costly and complicated (having dedicated components such as a trace BTB unit) and had various side-effects such as needing to flush on context switches. Deficiencies the µOP cache doesn't have. The trace cache resulted in a lot of duplication as well, for example {{\\|NetBurst}}'s 12k uops trace cache had a hit rate comparable to an 8 KiB-16 KiB L1I$ whereas this 1.5K µOPs cache cache is comparable to a 6 KiB instruction cache. This implies a significant storage efficiency of four-fold or greater. | ||
| + | |||
| + | ===== Allocation Queue ===== | ||
| + | The emitted µOPs from the decoders are sent directly to the Allocation Queue (AQ) or Instruction Decode Queue (IDQ). The Allocation Queue acts as the interface between the front-end ([[in-order]]) and the back-end ([[out-of-order]]). The Allocation Queue in Sandy Bridge has not changed from {{\\|Nehalem}} which is still 28-entries per thread. The purpose of the queue is to help absorb [[bubbles]] which may be introduced in the front-end, ensuring that a steady stream of 4 µOPs are delivered each cycle. | ||
| + | |||
| + | ====== µOP-Fusion & LSD ====== | ||
| + | The IDQ does a number of additional optimizations as it queues instructions. The Loop Stream Detector (LSD) is a mechanism inside the IDQ capable of detecting loops that fit in the IDQ and lock them down. That is, the LSD can stream the same sequence of µOPs directly from the IDQ continuously without any additional [[instruction fetch|fetching]], [[instruction decode|decoding]], or utilizing additional caches or resources. Streaming continues indefinitely until reaching a branch [[mis-prediction]]. The LSD is particularly excellent in for many common algorithms that are found in many programs (e.g., tight loops, intensive calc loops, searches, etc..). The LSD is a very primitive but efficient power saving mechanism because while the LSD is active, the rest of the front-end is effectively disabled - including both the decoders and the micro-op cache. | ||
| + | |||
| + | For loops to take advantage of the LSD they need to be smaller than 28 µOPs. However since this is largely a small power saving feature, in most cases the µOPs can take advantage of the new µOPs cache instead and see no measurable performance difference. | ||
| + | |||
| + | ==== Execution engine ==== | ||
| + | [[File:sandy bridge rob.svg|right|450px]] | ||
| + | The back-end or execution engine of Sandy Bridge deals with the execution of [[out-of-order]] operations. Sandy Bridge back-end is a clear a happy merger of both {{\\|NetBurst}} and {{\\|P6}}. As with {{\\|P6}} (through {{\\|Westmere}}), Sandy Bridge treats the three classes of µOPs ([[floating point]], [[integer]], and [[vector]]) separately. The implementation itself, however, is quite different. Sandy Bridge borrows the tracking and renaming architecture of {{\\|NetBurst}} which is far more efficient. | ||
| + | |||
| + | Sandy Bridge uses the tracking technique found in {{\\|NetBurst}} which uses a rename which is based on [[physical register file]] (PRF). All earlier predecessors, {{\\|P6}} through {{\\|Westmere}}, utilized a [[Retirement Register File]] (RRF) along with a [[Re-Order Buffer]] (ROB) which was used to track the micro-ops and data that are in flight. ROB results are then written into the RRF on retirement. Sandy Bridge returned to a PRF, meaning all of the data is now stored in the PRF with a separate component dedicated for the various meta data such as status information. It's worth pointing out that since Sandy Bridge introduced {{x86|AVX}} which extends register to 256-bit, moving to a PRF-based renaming architecture would have more than likely been a hard requirement as the amount of added complexity would've negatively impacted the entire design. Unlike a RRF, retirement is considerably simpler, requiring a simple mapping change between the architectural registers and the PRF, eliminating any actual data transfers - something that would've undoubtedly worsen with the new 256-bit {{x86|AVX}} extension. An additional component, the Register Alias Tables (RAT), is used to maintain the mapping of logical registers to physical registers. This includes both architectural state and most recent speculated state. In Sandy Bridge, ReOrder Buffer (ROB) still exists but is a much simpler component that tracks the in-flight µOPs and their status. | ||
| + | |||
| + | In addition to the back-end architectural changes, Intel has also increased most of the buffers significantly, allowing for far more µOPs in-flight than before. | ||
| + | |||
| + | ===== Renaming & Allocation ===== | ||
| + | On each cycle, up to 4 µOPs can be delivered here from the front-end from one of the two threads. As stated earlier, the Re-Order Buffer is now a light-weight component that tracks the in-flight µOPs. The ROB in Sandy Bridge is 168 entries, allowing for up to 40 additional µOPs in-flight over {{\\|Nehalem}}. At this point of the pipeline the µOPs are still handled sequentially (i.e., in order) with each µOP occupying the next entry in the ROB. This entry is used to track the correct execution order and statuses. In order for the ROB to rename an integer µOP, there needs to be an available Integer PRF entry. Likewise, for FP and SIMD µOPs there needs to be an available FP PRF entry. Following renaming, all bets are off and the µOPs are free to execute as soon as their dependencies are resolved. | ||
| + | |||
| + | It is at this stage that [[architectural registers]] are mapped onto the underlying [[physical registers]]. Other additional bookkeeping tasks are also done at this point such as allocating resources for stores, loads, and determining all possible scheduler ports. Register renaming is also controlled by the [[Register Alias Table]] (RAT) which is used to mark where the data we depend on is coming from (after that value, too, came from an instruction that has previously been renamed). Sandy Bridge's move to a PRF-based renaming has a fairly substantial impact on power too. With {{x86|AVX|the new}} {{x86|extensions|instruction set extension}} which allows for 256-bit operations, a retirement would've meant large amount of 256-bit values have to be needlessly moved to the Retirement Register File each time. This is entirely eliminated in Sandy Bridge. The decoupling of the PRFs from the RAT/ROB likely means some added latency is at play here, but the overall benefits are more than worth it. | ||
| + | |||
| + | There is no special costs involved in splitting up fused µOPs before execution or [[retirement]] and the two fused µOPs only occupy a single entry in the ROB, however the rename registers has more than doubled over {{\\|Nehalem}} in order to accommodate those fused operations. The RAT is capable of handling 4 µOPs each cycle. Note that the ROB still operates on fused µOPs, therefore 4 µOPs can effectively be as high as 8 µOPs. | ||
| + | |||
| + | Since Sandy Bridge performs [[speculative execution]], it can speculate incorrectly. When this happens, the architectural state is invalidated and as such needs to be rolled back to the last known valid state. Sandy Bridge has a 48-entry [[Branch Order Buffer]] (BOB) that keeps tracks of those states for this very purpose. | ||
| + | |||
| + | ===== Optimizations ===== | ||
| + | {| style="border: 1px solid gray; float: right; margin: 10px; padding: 5px; width: 350px;" | ||
| + | | [[Zeroing Idiom]] Example: | ||
| + | |- | ||
| + | | <pre>xor eax, eax</pre> | ||
| + | |- | ||
| + | | Not only does this instruction get eliminated at the ROB, but it's actually encoded as just 2 bytes <code>31 C0</code> vs the 5 bytes for <code>{{x86|mov}} {{x86|eax}}, 0x0</code> which is encoded as <code>b8 00 00 00 00</code>. | ||
| + | |} | ||
| + | Sandy Bridge introduced a number of new optimizations it performs prior to entering the out-of-order and renaming part. Two of those optimizations are [[Zeroing Idioms]], and [[Ones Idioms]]. The first common optimization performed in Sandy Bridge is [[Zeroing Idioms]] elimination or a dependency breaking idiom. A number of common zeroing idioms are recognized and consequently eliminated. This is done prior to bookkeeping at the ROB, allowing those µOPs to save resources and eliminating them entirely and breaking any dependency. Eliminated zeroing idioms are zero latency and are entirely removed from the pipeline (i.e., retired). | ||
| + | |||
| + | Sandy Bridge recognizes instructions such as <code>{{x86|XOR}}</code>, <code>{{x86|PXOR}}</code>, and <code>{{x86|XORPS}}</code> as zeroing idioms when the [[source operand|source]] and [[destination operand|destination]] operands are the same. Those optimizations are done at the same rate as renaming during renaming (at 4 µOPs per cycle) and the architectural register is simply set to zero (no actual physical register is used). | ||
| + | |||
| + | The [[ones idioms]] is another dependency breaking idiom that can be optimized. In all the various {{x86|PCMPEQ|PCMPEQx}} instructions that perform packed comparison the same register with itself always set all bits to one. On those cases, while the µOP still has to be executed, the instructions may be scheduled as soon as possible because the current state of the register needs not to be known. | ||
| + | |||
| + | ===== Scheduler ===== | ||
| + | [[File:sandy bridge scheduler.svg|right|500px]] | ||
| + | Following bookkeeping at the ROB, µOPs are sent to the scheduler. Everything here can be done out-of-order whenever dependencies are cleared up and the µOP can be executed. Sandy Bridge features a very large unified scheduler that is dynamically shared between the two threads. The scheduler is exactly one and half times bigger than the reservation station found in {{\\|Nehalem}} (a total of 54 entries). The various internal reordering buffers have been significantly increased as well. The use of a unified scheduler has the advantage of dipping into a more flexible mix of µOPs, resulting in a more efficient and higher throughput design. | ||
| + | |||
| + | Sandy Bridge has two distinct [[physical register files]] (PRF). 64-bit data values are stored in the 160-entry Integer PRF, while [[Floating Point]] and vector data values are stored in the Vector PRF which has been extended to 256 bits in order to accommodate the new {{x86|AVX}} {{x86|YMM}} registers. The Vector PRF is 144-entry deep which is slightly smaller than the Integer one. It's worth pointing out that prior to Sandy Bridge, code that relied on constant register reading was bottlenecked by a limitation in the register file which was limited to three reads. This restriction has been eliminated in Sandy Bridge. | ||
| + | |||
| + | At this point, µOPs are not longer fused and will be dispatched to the execution units independently. The scheduler holds the µOPs while they wait to be executed. A µOP could be waiting on an operand that has not arrived (e.g., fetched from memory or currently being calculated from another µOPs) or because the execution unit it needs is busy. Once the µOP is ready, they are dispatched through their designated port. | ||
| + | |||
| + | The scheduler will send the oldest ready µOP to be executed on each of the six ports each cycle. Sandy Bridge, like {{\\|Nehalem}} has six ports. Port 0, 1, and 5 are used for executing computational operations. Each port has 3 stacks of execution units corresponding to the three classes of data types: Integer, SIMD Integer, and Floating Point. The Integer stack handles 64-bit general-purpose integer operations. The SIMD Integer and the Floating Point stacks are both 128-bit wide. | ||
| + | |||
| + | Each cluster operates within its own domain. Domains help refuse power for less frequently used domains and to simplify the routing networks. Data flowing within its domain (e.g., integer->integer or FP->FP) are effectively free and can be done each cycle. Data flowing between two separate domains (e.g., integer->FP or FP->integer) will incur an additional one or two cycles for the data to be forwarded to the appropriate domain. | ||
| + | |||
| + | Sandy Bridge ports 2, 3, and 4, are used for executing memory related operations such as loads and stores. Those ports all operate within the Integer stack due to integer latency sensitivity. | ||
| + | |||
| + | ====== New 256-bit extension ====== | ||
| + | Sandy Bridge introduced the {{x86|AVX}} extension, a new 256-bit [[x86]] floating point [[SIMD]] {{x86|extension}}. The new instructions are implemented using an improved {{x86|VEX|Vector EXtension}} (VEX) prefix byte sequence. Those instructions are in turn decoded into single µOPs most of the time. | ||
| + | |||
| + | In order to have a noticeable effect on performance, Intel opted to not to repeat their initial SSE implementation choices. Instead, Intel doubled the width of all the associated executed units. This includes a full hardware 256-bit floating point multiply, add, and shuffle - all having a single-cycle latency. | ||
| + | |||
| + | As mentioned earlier, both the Integer SIMD and the FP stacks are 128-bit wide. Widening the entire pipeline is a fairly complex undertaking. The challenge with introducing a new 256-bit extension is being able to double the output of one of the stacks while remaining invisible to the others. Intel solved this problem by cleverly dual-purposing the two existing 128-bit stacks during AVX operations to move full 256-bit values. For example a 256-bit floating point add operation would use the Integer SIMD domain for the lower 128-bit half and the FP domain for the upper 128-bit half to form the entire 256-bit value. The re-using of existing datapaths results in a fairly substantial die area and power saving. | ||
| + | |||
| + | Overall, Sandy Bridge achieves double the [[FLOP]] of {{\\|Nehalem}}, capable of performing 256-bit multiply + 256-bit add each cycle. That is, Sandy Bridge can sustain 16 single-precision FLOP/cycle or 8 double-precision FLOP/cycle. | ||
| + | |||
| + | ====== Scheduler Ports & Execution Units ====== | ||
| + | Overall, Sandy Bridge is further enhanced with rebalanced ports. For example, the various string operations have been moved to port 0. A second has been augmented with LEA execution capabilities. Ports 0 and 1 gained additional capabilities such as integer blends. The various security enhancements that were added in {{\\|Westmere}} have also been improved. | ||
| + | |||
| + | ===== Retirement ===== | ||
| + | Once a µOP executes, or in the case of fused µOPs both µOPs have executed, they can be [[retired]]. Sandy Bridge is able to commit up to four fused (which can be up to 6 unfused) µOPs each cycle. Retirement happens [[in-order]] and releases any used resources such as those used to keep track in the [[reorder buffer]]. | ||
| + | |||
| + | ==== Memory subsystem ==== | ||
| + | [[File:sandy bridge mem subsystem.svg|right|300px]] | ||
| + | The memory subsystem in Sandy Bridge has been vastly improved. | ||
| + | |||
| + | One of the most sought-after improvements was increasing the load bandwidth. Loads are one of the most important µOPs in the core. With inadequate load bandwidth, computational code (specifically the new {{x86|AVX}}) will effectively starve. Back in {{\\|Nehalem}}, there were three ports for memory with two ports for address generation units. In particular, Port 2 was dedicated for data loads and Port 3 was dedicated for stores. Intel treats where you want to store the data and what you want to store as two distinct operations. Port 3 was used for the address calculation whereas Port 4 was used for the actual data. In Sandy Bridge, Intel made both ports symmetric; that is, both Port 2 and Port 3 are AGUs that may be used for load and stores, effectively doubling the load bandwidth. This allows for 2 loads and 1 store (48 bytes) each cycle which is much better suited for many computational operations over 1:1/cycle. | ||
| + | |||
| + | Following an address generation, the address is translated from virtual one to physical at the L1D$. Like {{\\|Nehalem}}, the L1D cache is still 32 KiB and 8-way set associative. It is physically tagged, virtuallly index, and uses 64 B lines along with a write-back policy. The load-to-use latency is 4 cycles for integers and a few more cycles for SIMD/FP as they need to cross domains. {{\\|Westmere}} added support for 1 GiB "Huge Pages", but those pages lacked dedicated DTLB entries forcing them to be fragmented across 2 MiB entries. This was addressed in Sandy Bridge with four entries for 1 GiB page. | ||
| + | |||
| + | In addition to making the two AGUs more flexible, many of the buffers were enlarged. The load buffer is now 33% larger, allowing for up to 64 load µOPs in-flight. Likewise, the store buffer has been slightly increased from 32 entries to 36. Both buffers are partitioned between the two threads. Altogether, Sandy Bridge can have 100 simultaneous memory operations in-flight. That's almost 60% of the entire capacity of the ROB used for memory operations. | ||
| + | |||
| + | As with the L1D, the L2 is organized the same as {{\\|Nehalem}}. It's 256 KiB, 8-way set associative, and is non-inclusive of the L1; that is, L1 may or may not be found in the L2. The L2 to L1 bandwidth is 16 bytes/cycle in either direction. The L1 can either receive data from the L2 or send data to the Load/Store buffers each cycle, but not both. The L2 uses a write-back policy and has a 12-cycle load-to-use latency, which is slightly worse than the 10 cycles in {{\\|Nehalem}}. From the CBox (i.e., LLC slice) to the ring, the bandwidth is 32 B/cycle, however Intel has not detailed how L3 to L2 works exactly, making modeling such behavior rather difficult. | ||
| + | |||
| + | == Configurability == | ||
| + | Configurability was a major design goal for Sandy Bridge and is something that Intel spent considerable effort on. With a highly-configurable design, using the same [[macro cells]], Intel can meet the different market segment requirements. Sandy Bridge configurabiltiy was presented during the [[2011]] [[International Solid-State Circuits Conference]]. A copy of the paper can be [http://ieeexplore.ieee.org/abstract/document/5746311/ found here]. | ||
| + | |||
| + | [[File:sandy bridge chop layout.png|right]] | ||
| + | |||
| + | The Sandy Bridge [[floorplan]], [[power planes]], and choppability axes are shown on the right in a diagram from Intel. The master design incorporates the [[quad-core|four]] CPU [[physical cores|cores]], the [[GPU]] with 12 execution units, the 8 MiB shared [[L3 cache]] which is shared between them all, and the {{intel|System Agent}} with the dual-channel [[DDR3]] [[memory controller]], 20 [[PCIe]] lanes controller, and a two parallel pipe display engines. | ||
| + | |||
| + | The design is modular, allowing for two of the cores to be "chopped off" along with their L3 slices to form a dual-core die. Additionally, the GPU can be optimized for a particular segment by reducing the number of execution units. Sandy Bridge allows for half of the execution units (i.e., down to six) to be chopped off for lower-end models. It's worth pointing out the the non-chop area of the GPU is greater due to the unslice and fixed-media functions of the GPU which are offered on all models regardless of the GPU configuration. | ||
| + | |||
| + | With over a dozen variations possible, Sandy Bridge is shipped in three of those configurations as actual fabricated [[dies]]. | ||
| + | |||
| + | * Die 1: 4 CPU Cores, 4 L3 Slices (8 MiB), and a GPU with 12 EUs. 1.16 billion transistors on a 216 mm² die. | ||
| + | * Die 2: 2 CPU Cores, 2 L3 Slices (4 MiB), and a GPU with 12 EUs. 624 million transistors on a 149 mm² die. | ||
| + | * Die 3: 2 CPU Cores, 2 L3 Slices (3 MiB), and a GPU with 6 EUs. 504 million transistors on a 131 mm² die. | ||
| + | |||
| + | It's worth pointing out that the each GPU execution unit is roughly 20 million transistors with 6 of them mounting to 120 million. There is also no [[quad-core]] configuration with a low-end GPU version (i.e., with 6 EUs). Additionally, die area is a much bigger concern with the dual-core die than it is with the quad-core die, hence the chunk of roughly 8 mm² of empty die space on the upper right corner of the die. | ||
| + | |||
| + | === Fused features === | ||
| + | Depending on the price segment, additional features may be disabled. For example, in the low-end value chips such as those under the {{intel|Celeron}} brand may have more of the L3 cache disabled (e.g., 1 MiB of the 2 MiB) while the high-end performance {{intel|Core i7}} will have the entire 2 MiB cache enabled. The L3 cache can be fused off by slice with a granularity of 4-way 512 KiB chunks. For example, the full L3 cache is 2 MiB corresponding to 16-way set associative. Whereas a 1.5 MiB L3 slice which has 512 KiB disabled (4-way) is now 12-way set associative. | ||
| + | |||
| + | In addition to the cache, both {{intel|Hyper-Threading|multi-threading}} and the number of PCIe lanes offered can be disabled or enabled depending on the exact model offered. | ||
| + | |||
| + | === Physical layout === | ||
| + | Bellow are the [[die]] are breakdown for the [[DDR]] [[PHY]], I/O PHY, SA, GPU, L3$, and the core. Note that the area of the DDR and I/O PHYs for the two smaller dies have been extrapolated from sizes of the components of the quad-core die and therefore may be off by a bit. | ||
| + | |||
| + | <gallery widths=500px heights=275px caption="Physical Layout Breakdown" style="float:right"> | ||
| + | File:sandy bridge die area (quad).svg|Quad-core die, GT2 GPU | ||
| + | File:sandy bridge die area (dual, gt2).svg|Dual-core die, GT2 GPU | ||
| + | File:sandy bridge die area (dual, gt1).svg|Dual-core die, GT1 GPU | ||
| + | </gallery> | ||
| + | |||
| + | Some [[macrocells]] remain the same regardless of the die configuration. Below is the percentage breakdown by component for each of the dies. (Values may be rounded and not add to 100 exactly.) | ||
| + | |||
| + | {| class="wikitable" | ||
| + | ! colspan="4" | Area Percentage | ||
| + | |- | ||
| + | ! Die Configuration !! 4+2 !! 2+2 !! 2+1 | ||
| + | |- | ||
| + | | {{intel|System Agent}} || 8.3% || 12.1% || 13.7% | ||
| + | |- | ||
| + | | [[L3$]] + {{intel|Ring}} || 19.9% || 14.4% || 16.4% | ||
| + | |- | ||
| + | | [[physical cores|Cores]] || 34.3% || 24.8% || 28.2% | ||
| + | |- | ||
| + | | [[Integrated Graphics]] || 17.6 % || 25.5% || 16% | ||
| + | |- | ||
| + | | [[DDR]]/[[I/O]] PHYs || 19.9% || 23.2% || 25.6% | ||
| + | |} | ||
| + | |||
| + | == Testability == | ||
| + | With the higher level of integration testing also increases in complexity because the ability to observe data signals becomes increasingly complex as those signals are no longer exposed. Those internal [[signals]] are quite valuable because they can provide the designers with an insight into the flow of threads and data among the cores and caches. Sandy Bridge introduced the {{intel|Generic Debug eXternal Connection}} (GDXC), a debug bus that allows snooping the ring bus in order to monitor the traffic that flows between the cores, GPU, caches, and the {{intel|System Agent}} on the ring bus. GDXC allows chip, system or software debuggers to sample the traffic on ring bus including the ring protocol control signals themselves and dump the data to an external analyzer via a dedicated on-package probe array. GDXC is protected by an Intel patent US20100332927 filed Jun 30, 2009 and should expire on June 30, 2029. | ||
| + | |||
| + | It's worth pointing out the GDX is inherently vulnerable to a [[physical attack|physical]] [[port attack]] if it's made accessible after factory testing. | ||
| + | |||
| + | == Clock Domains == | ||
| + | [[File:sandy bridge clock domains.png|right|500px]] | ||
| + | Sandy Bridge reworked the way clock generation is done. There are now 13 [[phase-locked loop|PLLs]] driving independent clock domains for the individual cores, the cache slices, the integrated graphics, the {{intel|System Agent}}, and the four independent I/O regions. The goal was ensuring uniformity and consistency across all clock domains. | ||
| + | |||
| + | A single external reference clock is provided by the {{intel|Platform Control Hub}} (PCH) chip. The {{intel|BCLK}}, the System Bus Clock which dates back to the {{intel|FSB}}, is now the reference clock which has been set to 100 MHz. Note that this has changed from 133 MHz in previous architectures. The BCLK is the reference edge for all the clock domains. Because the core slices and the integrated graphics have variable frequency which {{intel|turbo boost|scales with workloads}} and voltage requirements, the Slice PLLs and GPU PLL sit behind their own 100 MHz Reference Spine. This was done to ensure clock skew is minimized as much as possible over the different power planes. Intel used low [[jitter]] PLLs (long term jitter σ < 2ps is reported) in addition to the vertical clock spines and embedded [[clock compensator]]s to achieve good [[clock skew]] performance which was measured at 16 [[picoseconds|ps]]. | ||
| + | |||
| + | The System Agent PLL generates a variety of frequencies for the different zones like the PCU, SA, and Display Engine. Additionally, a seperate 133 MHz reference clock is also generated for main memory system. | ||
| + | |||
| + | === Overclocking === | ||
| + | {{oc warning}} | ||
| + | Because of the way clock generation is done in Sandy Bridge, some overclocking capabilities are no longer possible. Overclocking is generally done on [[unlocked]] parts such as the [[Core i5-2500K]] and [[Core i7-2600K]] processors. | ||
| + | |||
| + | [[File:sandy bridge bclk.png|left|300px]] | ||
| + | |||
| + | Some initial bad press surrounded Sandy Bridge overclocking capabilities because it was revealed that it can no longer be overclocked. Since the {{intel|BCLK}} is used as the reference clock to all clock domains - including PCIe, Display Link, and System Agent, increasing the BCLK will most certainly introduces system instability (most likely involving I/O). Note that in the image on the left, the "DMICLK" is the same as the "BCLK". Intel reported very limited overclocking capabilities of ~2 to 3%. It's therefore been recommended to leave the BCLK at the 100 MHz value. | ||
| + | |||
| + | The overclock-able models can be overclocked using their [[clock multiplier]]s, this requires the Desktop "P" PCH. In the diagram on the left '''(xC)''' refers to the Core Frequency and is represented as a multiple of BCLK (Core Frequency = BCLK × Core Freq Multiplier up to x57). Likewise '''(xM)''' refers to the memory ratio (up to 2133 MT/s). | ||
| + | |||
| + | Note that the '''(xP)''' and '''(xD)''' refer to the PEG (PCIe & Graphics) and {{intel|DMI}} Ratios. Those ratios are not adjustable and scale with the BCLK if overclocked. | ||
| + | |||
| + | {{clear}} | ||
| + | |||
| + | == Power == | ||
| + | Power consumption has been a key focus area for Sandy Bridge. The two power vectors that Sandy Bridge tries to address is the active power which is concerned with performance and idle power which is concerned with the average power of battery life. | ||
| + | |||
| + | [[File:sany bridge power planes.png|right|150px]] | ||
| + | The Power Control Unit (PCU) is located at the {{intel|System Agent}} which incorporates the various power management hardware logic as well as a dedicated microcontroller which runs firmware that controls the various power features of the device. Communication with the [[physical cores]] and the graphics is done via a dedicate power management over the ring. The unit constantly reads the physical parameters in real time of the parts of the chip allowing it to optimize the power efficiency of the die. The power unit is exposed to the world via a set of external outputs which allows it to interact with rest of the system to control the voltage regulator and an external power management controller. | ||
| + | |||
| + | Sandy Bridge has two variable power planes and a single fixed power plane for the {{intel|System Agent}}. The first one covers the ring, cache, and the physical cores. Note that this is a single power plane that is shared by all those components which means they all move together up or down in frequency and voltage. Each of the individual cores is capable of being entirely power gated when needed such as when the core goes into a higher [[C state]]. When this happens, the core state is saved into one of the ways of the cache and the core is entirely shut off. As with the cores, the caches can also be power-gated per way. With each deeper idle state, additional ways are invalidated and flushed and turned off. | ||
| + | |||
| + | The [[integrated graphics]] has its own variable power plane which can run at entirely different voltage and frequency than the cores. The graphics are not power gated but the voltage is cut off when the graphics needs to go into a sleep state. As mentioned earlier, the System Agent has a fixed power plane which many different voltages for the various I/Os and logic (e.g., Display, [[PCIe]], [[DDR]], etc..). The System Agent incorporates a programmable power plane which has a set of predefined voltages which the hardware signals can select from. | ||
| + | |||
| + | === Active power optimization === | ||
| + | Optimizing for performance means trying to deliver as much power as possible to demanding components all while meeting stringent constraints. Power algorithms take into account various constraints when considering what [[P-State]] (i.e., voltage and frequency) to operate in, which include the CPU capabilities, the platform specification (e.g. platform cooling capabilities), power delivery, graphics driver and operating system inputs as well as actual user controls (e.g. system preferences) and the type of workload (e.g. [[I/O bound]] workloads will not enjoy performance increase through increased frequency). Improvements in that area comes from throughput improvement and responsiveness (branded under "Turbo Boost 2.0"). | ||
| + | |||
| + | In order to optimize the active power, you need to be able to determine the real time power. Sandy Bridge features Intel's 3rd generation power metering. Power metering is an event-based power meter which incorporates many different counters that track the main activity blocks of the die. Energy cost is then applied to the 100s of different event counters which are then summed up in order to obtain the active power. The die also incorporates fuses on different areas in order to be able to obtain the leakage and idle static power of the system which is used along with the active power to get an estimate of the entire chip's power. Most of this functionality is exposed to software as well via {{x86|MSR}}s. | ||
| + | ==== New thermal capacitance model ==== | ||
| + | [[File:sandy bridge dynamic thermal capacitance.png|right|350px]] | ||
| + | Prior to Sandy Bridge, Intel used a static model for thermal capacitance. That is, traditionally, if a model is certified for a specific TDP wattage, under no circumstance the chip will be allowed to run any hotter than that rating. This has the implication of treating temperature changes as instant. In reality temperature changes are not instant and there is a tiny bit of time early on when the heat sink is relatively cool and can absorb heat considerably faster. With Sandy Bridge, Intel moved to dynamic model which allows the chip to take advantage of the period of time when the heat spreader is still cool and can dissipate more heat quicker. For the desktop parts this can be a period of over a minute in which Sandy Bridge can operate at considerably higher frequencies and run much hotter. | ||
| + | |||
| + | Sandy Bridge uses an exponential average moving filter mode which can be used to estimate the energy budget. | ||
| + | |||
| + | :<math>E_{n+1} = \alpha E_n + (1- \alpha) * (\text{TDP}_n - P_n) \Delta t_n</math> | ||
| + | |||
| + | Where ''P'' is the measured power from the power meter and ''TDP'' is the certified die power allowance. Therefore a chip running at considerably under the certified TDP accumulates energy budget which can then be used up when the chip needs an instantaneous boost in performance. Once the extra energy budget is exhausted, the chip must go back to within its certified TDP. | ||
| + | |||
| + | The driving motivation behind this change is the fact that humans are considerably slower than the computer. This often means that performance-critical actions are fairly sparse and spread out. For example opening an image might require high performance for a short burst of time in which after the user might take a little bit of time to think about his next action. During those pauses the system is more or less idle and can accumulate some extra energy budget which can then be used to speed up the user's next short period of high performance action. This allows the system to be more responsive when needed most. | ||
| + | |||
| + | ==== Turbo Boost Technology 2.0 ==== | ||
| + | [[File:sandy bridge new turbo.png|right|350px]] | ||
| + | Intel introduced '''{{intel|Turbo Boost Technology}} 2.0''' ('''TBT 2.0''') with Sandy Bridge. The ability to temporarily boost core frequency has been refined over the last couple of generations. Back in {{\\|Core}} ({{intel|Merom|l=core}} core), Intel was able to deliver a single bin of turbo when the other [[physical core|core]] was asleep. Intel improved on that in {{\\|Nehalem}} by being able to deliver incrementally more bins the less cores are active. That is, slight speed bump for four cores, a few additional bins for when only two cores are active, and finally higher turbo for a single active core. With the introduction of {{\\|Westmere}}, which integrated the graphics in the same package, introduced dynamic frequency for the graphics domain. What's common to all previous implementations is their conservatives in how many bins they were allowed to boost into, especially when you went into two and four active cores. | ||
| + | |||
| + | With Sandy Bridge and the SoC integration of the graphics and memory controller, Turbo Boost has been expanded substantially. With the new {{intel|System Agent}} and the power control unit, the chip is able to take into account many more variables which were not previously present. This allow the power unit to make more accurate decisions regarding the available power headroom. This improvement allow the unit to allow higher turbo frequency when there is sufficient headroom while still staying within the required power envelope. | ||
| + | |||
| + | === Idle power optimization === | ||
| + | For mobility-specific power improvements, Intel improved battery life with Sandy Bridge as well as the overall power efficiency and reduced [[form factor]]. Key mobile features such as video playback have been substantially improved. The core, graphics, and package [[C-States]] have been enhanced to enable low-power idle and average power usage. Many new algorithms have been implemented which can take platform preferences from BIOS as well. This enables OEM to more finely tune the performance characteristics of the processor by indicating what kind of device this is and how power consumption and saving should be handled. | ||
| + | |||
| + | == Graphics == | ||
| + | {{main|intel/microarchitectures/gen6|l1=Gen6}} | ||
| + | Sandy Bridge supports up to two independent displays. | ||
| + | |||
| + | {| class="wikitable tc2 tc3" | ||
| + | |- | ||
| + | ! colspan="4" | Gen6 [[IGP]] Models !! colspan="7" | Standards | ||
| + | |- | ||
| + | ! rowspan="2" | Name !! rowspan="2" | Execution Units !! rowspan="2" | Tier !! rowspan="2" | Series !! colspan="3" | [[Direct3D]] !! colspan="2" | [[OpenGL]] | ||
| + | |- | ||
| + | | Windows || Linux || [[High Level Shading Language|HLSL]] || Windows || Linux | ||
| + | |- | ||
| + | | {{intel|HD Graphics (Sandy Bridge)|HD Graphics}} || 6 || GT1 || {{intel|Sandy Bridge M|M|l=core}}/{{intel|Sandy Bridge H|H|l=core}} || rowspan="4" style="text-align: center;" | '''10.1''' || rowspan="4" style="text-align: center;" | '''N/A''' || rowspan="4" style="text-align: center;" | '''4.1''' || rowspan="4" style="text-align: center;" | '''3.1''' || rowspan="4" style="text-align: center;" | '''3.3''' | ||
| + | |- | ||
| + | | {{intel|HD Graphics 2000}} || 6 || GT1 || {{intel|Sandy Bridge H|H|l=core}} | ||
| + | |- | ||
| + | | {{intel|HD Graphics 3000}} || 12 || GT2 || {{intel|Sandy Bridge M|M|l=core}}/{{intel|Sandy Bridge H|H|l=core}} | ||
| + | |- | ||
| + | | {{intel|HD Graphics P3000}} || 12 || GT2 || {{intel|Sandy Bridge DT|DT|l=core}} | ||
| + | |} | ||
| + | ==== Hardware Accelerated Video ==== | ||
| + | {{sandy bridge hardware accelerated video table}} | ||
| + | |||
| + | == Sockets/Platform == | ||
| + | Sandy Bridge comes in three different [[C4]] packages: [[PGA]] for mobile computers, [[LGA]] for desktop systems and [[BGA]] for small form factor systems. For each of the three different dies (see [[#Configurability|§ Configurability]]), a different [[package]] [[stack-up]] was developed optimized for a particular vector: 10 layers for the highest power consumption, and 8 or 6 layers for the smaller dies. | ||
| + | |||
| + | {| class="wikitable" style="text-align: center;" | ||
| + | |- | ||
| + | ! Package !! Permanent !! Platform !! Chipset !! Bus | ||
| + | |- | ||
| + | | {{intel|FCBGA-1023}} || Yes || rowspan="4" | 2-chip solution || rowspan="4" | Cougar Point || rowspan="4" | [[DMI 2.0]] | ||
| + | |- | ||
| + | | {{intel|FCBGA-1224}} || Yes | ||
| + | |- | ||
| + | | {{intel|rPGA988B}} || No | ||
| + | |- | ||
| + | | {{intel|LGA-1155}} || No | ||
| + | |} | ||
== Die == | == Die == | ||
| + | Sandy Bridge desktop and mobile consist of 2 and 4 core models, each with their own die. One of the most noticeable changes on die is the integration of the GPU and the memory interface. The major components of the die are: | ||
| + | |||
| + | * System Agent | ||
| + | * CPU Core | ||
| + | * Ring bus interconnect | ||
| + | * Memory Controller | ||
| + | |||
| + | === System Agent === | ||
| + | The System Agent (SA) contains the Display Engine (DE), Power management units, and the various I/O buses. | ||
| + | |||
| + | : [[File:sandy bridge system agent.png|650px]] | ||
| + | |||
| + | |||
| + | : [[File:sandy bridge system agent (annotated).png|650px]] | ||
| + | |||
| + | === Core === | ||
| + | Sandy Bridge Client models come in either 2x core or 4x core setup. | ||
| + | |||
| + | * 18.5 mm² die size | ||
| + | |||
| + | : [[File:sandy bridge core die.png|550px]] | ||
| + | |||
| + | |||
| + | : [[File:sandy bridge core die (annotated).png|550px]] | ||
| + | |||
| + | === Core Group === | ||
| + | Client models come in groups of 2 or 4 cores. | ||
| + | |||
| + | * 2-cores group: | ||
| + | ** 58.5 mm² die size | ||
| + | *** 2 Cores: 2x 18.5 mm² = 37 mm² | ||
| + | *** L3 Cache: 2x 10.75 mm² = 21.5 mm² | ||
| + | |||
| + | * 4-core group | ||
| + | ** 117 mm² die size | ||
| + | *** 4 Cores: 4x 18.5 mm² = 74 mm² | ||
| + | *** L3 Cache: 4x 10.75 mm² = 43 mm² | ||
| + | |||
| + | : [[File:sandy bridge 4x core complex die.png|500px]] | ||
| + | |||
| + | === Dual-Core (GT1) === | ||
| + | * 504,000,000 transistors | ||
| + | * [[32 nm process]] | ||
| + | * 131 mm² die size | ||
| + | * 2 CPU cores | ||
| + | * 1 GPU core | ||
| + | ** 6 EUs | ||
| + | |||
| + | === Dual-Core (GT2) === | ||
| + | * 624,000,000 transistors | ||
| + | * [[32 nm process]] | ||
| + | * 149 mm² die size | ||
| + | * 2 CPU cores | ||
| + | * 1 GPU core | ||
| + | ** 12 EUs | ||
| + | |||
| + | : [[File:sandy bridge (dual-core).jpg|600px]] | ||
| + | |||
| + | === Quad-Core === | ||
Quad-core Sandy Bridge die: | Quad-core Sandy Bridge die: | ||
| − | |||
| − | + | * 1,160,000,000 transistors (995,000,000 transistors pre-layout) | |
| − | * 1,160,000,000 transistors | ||
* [[32 nm process]] | * [[32 nm process]] | ||
| − | * 216 | + | * 216 mm² die size |
* 4 CPU cores | * 4 CPU cores | ||
* 1 GPU core | * 1 GPU core | ||
** 12 EUs | ** 12 EUs | ||
| − | == | + | |
| − | + | : [[File:sandy bridge (quad-core).jpg|850px]] | |
| + | |||
| + | : [[File:sandy bridge (quad-core) (annotated).png|850px]] | ||
| + | |||
| + | === Wafer === | ||
| + | : [[File:sandy bridge partial wafer.png|850px]] | ||
| + | |||
| + | |||
| + | : [[File:sandy bridge partial wafer (annotated).png|850px]] | ||
| + | |||
| + | === Additional Shots === | ||
| + | Additional die and wafer shots provided by Intel: | ||
| + | |||
| + | <gallery mode=slideshow> | ||
| + | File:sandy bridge die on a wafer.png|A partial wafer shot showing a complete quad-core die along with eight other dies around it. | ||
| + | File:sandy bridge whole wafer.png|An entire Sandy Bridge Wafer. | ||
| + | File:sandy bridge wafer angled 1.png|Partial wafer shot, angled. shot 1. | ||
| + | File:sandy bridge wafer angled 2.png|Partial wafer shot, angled. shot 2. | ||
| + | File:sandy bridge wafer angled 3.png|Partial wafer shot, angled. shot 3. | ||
| + | </gallery> | ||
== All Sandy Bridge Chips == | == All Sandy Bridge Chips == | ||
| Line 46: | Line 737: | ||
created and tagged accordingly. | created and tagged accordingly. | ||
| − | Missing a chip? please dump its name here: | + | Missing a chip? please dump its name here: https://en.wikichip.org/wiki/WikiChip:wanted_chips |
--> | --> | ||
| − | <table class=" | + | {{comp table start}} |
| − | <tr | + | <table class="comptable sortable tc6 tc7 tc20 tc21 tc22 tc23 tc24 tc25"> |
| − | + | <tr class="comptable-header"><th> </th><th colspan="19">List of Sandy Bridge Processors</th></tr> | |
| − | <tr><th> | + | <tr class="comptable-header"><th> </th><th colspan="9">Main processor</th><th colspan="5">{{intel|Turbo Boost}}</th><th>Mem</th><th colspan="3">IGP</th></tr> |
| − | {{#ask: [[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Sandy Bridge]] | + | {{comp table header 1|cols=Launched, Price, Family, Core Name, Cores, Threads, %L2$, %L3$, TDP, %Frequency, 1 Core, 2 Cores, 3 Cores, 4 Cores, Max Mem, GPU, %Frequency, Turbo}} |
| + | {{#ask: [[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Sandy Bridge]] [[max cpu count::1]] | ||
|?full page name | |?full page name | ||
|?model number | |?model number | ||
| − | |? | + | |?first launched |
| − | |? | + | |?release price |
| + | |?microprocessor family | ||
|?core name | |?core name | ||
| − | |? | + | |?core count |
| − | |? | + | |?thread count |
| + | |?l2$ size | ||
| + | |?l3$ size | ||
|?tdp | |?tdp | ||
| − | |?base frequency | + | |?base frequency#GHz |
| − | |?max memory | + | |?turbo frequency (1 core)#GHz |
| + | |?turbo frequency (2 cores)#GHz | ||
| + | |?turbo frequency (3 cores)#GHz | ||
| + | |?turbo frequency (4 cores)#GHz | ||
| + | |?max memory#GiB | ||
|?integrated gpu | |?integrated gpu | ||
|?integrated gpu base frequency | |?integrated gpu base frequency | ||
|?integrated gpu max frequency | |?integrated gpu max frequency | ||
|format=template | |format=template | ||
| − | |template=proc table | + | |template=proc table 3 |
| − | |userparam= | + | |searchlabel= |
| + | |sort=microprocessor family, model number | ||
| + | |order=asc,asc | ||
| + | |userparam=20 | ||
|mainlabel=- | |mainlabel=- | ||
| + | |limit=200 | ||
}} | }} | ||
| − | + | {{comp table count|ask=[[Category:microprocessor models by intel]] [[instance of::microprocessor]] [[microarchitecture::Sandy Bridge]]}} | |
</table> | </table> | ||
| + | {{comp table end}} | ||
| + | |||
| + | == References == | ||
| + | * [https://newsroom.intel.com/editorials/sandy-bridge-breaks-the-mold-for-chip-codenames/ Sandy Bridge Breaks the Mold for Chip Codenames], December 29, 2010 | ||
| + | * Lempel, Oded. "2nd Generation Intel® Core Processor Family: Intel® Core i7, i5 and i3." Hot Chips 23 Symposium (HCS), 2011 IEEE. IEEE, 2011. | ||
| + | * Rotem, Efi, et al. "Power management architecture of the 2nd generation Intel® Core microarchitecture, formerly codenamed Sandy Bridge." Hot Chips 23 Symposium (HCS), 2011 IEEE. IEEE, 2011. | ||
| + | * Yuffe, Marcelo, et al. "A fully integrated multi-CPU, GPU and memory controller 32nm processor." Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2011 IEEE International. IEEE, 2011. | ||
| + | * Valentine, Bob. [[:File:introducing sandy bridge.pdf|"Introducing sandy bridge."]] Intel Developer Forum, San Francisco. 2010. | ||
| + | |||
| + | == Documents == | ||
| + | * Valentine, Bob. [[:File:introducing sandy bridge.pdf|"Introducing sandy bridge."]] Intel Developer Forum, San Francisco. 2010. | ||
| + | * [[:File:core-overview-of-2nd-generation-intel-core-processor-family-brief.pdf|2nd Generation Intel® Core Processor Family]] | ||
| + | * [[:File:performance-2nd-gen-core-product-brief.pdf|2nd Generation Intel® Core vPro Processor Family]] | ||
| + | * [[:File:performance-2nd-generation-core-vpro-family-paper.pdf|2nd Generation Intel® Core vPro Processor Family; New levels of security, manageability, and responsiveness]] | ||
Latest revision as of 23:54, 28 December 2020
| Edit Values | |
| Sandy Bridge (client) µarch | |
| General Info | |
| Arch Type | CPU |
| Designer | Intel |
| Manufacturer | Intel |
| Introduction | September 13, 2010 |
| Phase-out | November, 2012 |
| Process | 32 nm |
| Core Configs | 2, 4 |
| Pipeline | |
| Type | Superscalar, Superpipeline |
| OoOE | Yes |
| Speculative | Yes |
| Reg Renaming | Yes |
| Stages | 14-19 |
| Decode | 4-way |
| Instructions | |
| ISA | x86-64 |
| Succession | |
| Contemporary | |
| Sandy Bridge (server) | |
Sandy Bridge (SNB) Client Configuration, formerly Gesher, is Intel's successor to Westmere, a 32 nm process microarchitecture for mainstream workstations, desktops, and mobile devices. Sandy Bridge is the "Tock" phase as part of Intel's Tick-Tock model which added a significant number of enhancements and features. The microarchitecture was developed by Intel's R&D center in Haifa, Israel.
For desktop and mobile, Sandy Bridge is branded as 2nd Generation Intel Core i3, Core i5, Core i7 processors. For workstations it's branded as first generation Xeon E3.
Contents
- 1 Etymology
- 2 Codenames
- 3 Brands
- 4 Process Technology
- 5 Compatibility
- 6 Compiler support
- 7 Architecture
- 8 Overview
- 9 System Architecture
- 10 Core
- 11 Configurability
- 12 Testability
- 13 Clock Domains
- 14 Power
- 15 Graphics
- 16 Sockets/Platform
- 17 Die
- 18 All Sandy Bridge Chips
- 19 References
- 20 Documents
Etymology[edit]

Sandy Bridge was originally called Gesher which literally means "bridge" in Hebrew. The name was requested to be changed by upper management after a meeting between the development group and analysts brought up that it might be a bad idea to be associated with a failed Israeli political party that was eventually dissolved.
The name Sandy Bridge consists of the English translation of "Gesher" with "Sandy" possible referring to the fact that silicon comes from sand.
The Logo on the left was Intel's original ("Gesher") logo for the microarchitecture.
Codenames[edit]
| Core | Abbrev | Target |
|---|---|---|
| Sandy Bridge M | SNB-M | Mobile processors |
| Sandy Bridge | SNB | Desktop performance to value, AiOs, and minis |
| Sandy Bridge E | SNB-E | Workstations & entry-level servers |
Brands[edit]
| Logo | Family | General Description | Differentiating Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Cores | HT | AVX | AES | IGP | TBT | ECC | |||
| |
Celeron | Entry-level Budget | 1 | ✔ | ✔ | ✘ | ✔/✘ | ✘ | ✔/✘ |
| 2 | ✘ | ✔ | ✔/✘ | ✔ | ✘ | ✔/✘ | |||
| |
Pentium | Budget | 2 | ✔/✘ | ✔ | ✔/✘ | ✔/✘ | ✘ | ✔/✘ |
| |
Core i3 | Low-end Performance | 2 | ✔ | ✔ | ✔/✘ | ✔/✘ | ✘ | ✔/✘ |
| |
Core i5 | Mid-range Performance | 2 | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| 4 | ✘ | ✔ | ✔ | ✔/✘ | ✔ | ✘ | |||
| |
Core i7 | High-end Performance | 2 | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| 4 | ✔ | ✔ | ✔ | ✔/✘ | ✔ | ✘ | |||
| 6 | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | |||
| |
Core i7EE | Enthusiasts/High-end Performance | 4 | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| 6 | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | |||
Process Technology[edit]

- Further information: Westmere § Process Technology
Sandy Bridge uses the same 32 nm process used for the Westmere microarchitecture for all mainstream consumer parts.
Compatibility[edit]
| Vendor | OS | Version | Notes |
|---|---|---|---|
| Microsoft | Windows | Windows XP | |
| Windows Vista | |||
| Windows 7 | |||
| Linux | Linux | Kernel ? | Initial Support |
Compiler support[edit]
| Compiler | Arch-Specific | Arch-Favorable |
|---|---|---|
| ICC | -march=sandybridge |
-mtune=sandybridge
|
| GCC | -march=sandybridge |
-mtune=sandybridge
|
| LLVM | -march=sandybridge |
-mtune=sandybridge
|
| Visual Studio | /arch:AVX |
/tune:sandybridge
|
CPUID[edit]
| Core | Extended Family |
Family | Extended Model |
Model |
|---|---|---|---|---|
| M | 0 | 0x6 | 0x2 | 0xA |
| Family 6 Model 42 | ||||
Architecture[edit]
Sandy Bridge features an entirely new architecture with a brand new core design which is both more highly performing and power efficient. The front-end has been entirely redesigned to incorporate a new decoded pipeline using a new µOP cache. The back-end is an entirely new PRF-based renaming architecture with a considerably large parallelism window. Sandy Bridge also provides considerable higher integration versus its predecessors resulting a full system on a chip design.
Key changes from Westmere[edit]

- Entirely brand new microarchitecture
- New client ring architecture
- New last level cache architecture
- Multi-bank LLC/Agent architecture
- 4x the bandwidth
- New System Agent architecture
- New power management unit
- New SVID (Serial Voltage ID bus)
- PECI entirely re-architected
- Chipset
- Ibex Peak → Cougar Point
- Socket H (LGA-1156) → Socket H2 (LGA-1155)
- Core
- Entirely redesigned
- Front-end
- New µOP cache
- Redesigned branch prediction
- Higher accuracy
- BTB is now a single-level design (from two-level)
- Instruction Queue
- Increased to 20 entries/thread (from 18 entries, shared)
- Improved macro-op fusion (covers almost all jump with most arithmetic now)
- Back-end
- Brand new back-end using PRF-based renaming (from a RRF-based)
- ReOrder Buffer (ROB)
- New design and entirely different functionality (only used to track in-flight micro-ops)
- Increased to 168 entries (from 128)
- New Zeroing Idioms optimizations
- New Onces Idioms optimizations
- Scheduler
- Larger buffer (54-entry, up from 26)
- Execution Units
- Ports rebalanced
- 256-bit operations (from 128-bit)
- Double FLOP/cycle
- AES operations enhanced
- Memory Subsystem
- L1I$ change to 8-way (from 4-way)
- Proper support for 1 GiB pages with 4-entry 1 GiB page DTLB (from 0)
- Double load throughput; 2 loads/cycle (from 1)
- AGUs can now do both loads and stores
- 33% larger load buffer (64 entries from 48)
- larger store buffer (36 entries from 32)
- Integrated Graphics
- Integrated graphics is now integrated on the same die (previously was on a second die)
- Dropped QPI controller which linked the two dies
- Improved performance and media capabilities
- On a 32 nm process, same die as the cores (from 45 nm)
- Embedded Display Port (eDP) is now on a dedicated port (from sharing pins with PCIe interface)
- Integrated PCIe Controller
- Integrated Memory Controller
- Integrated on-die is now integrated on the same die (previously was on a second die)
- Dropped QPI controller which linked the two dies
- Testability
- Integrates Generic Debug eXternal Connection (GDXC)
New instructions[edit]
Sandy Bridge introduced a number of new instructions:
-
AVX- Advanced Vector Extensions
Block Diagram[edit]
Entire SoC Overview (dual)[edit]
.svg)
Entire SoC Overview (quad)[edit]

Individual Core[edit]

Gen6[edit]
See Gen6#Gen6.
Memory Hierarchy[edit]
The memory subsystem has been reworked in Sandy Bridge.
- Cache
- L0 µOP cache:
- 1,536 µOPs, 8-way set associative
- 32 sets, 6-µOP line size
- statically divided between threads, per core, inclusive with L1I$
- 1,536 µOPs, 8-way set associative
- L1I Cache:
- 32 KiB, 8-way set associative
- 64 sets, 64 B line size
- shared by the two threads, per core
- 32 KiB, 8-way set associative
- L1D Cache:
- 32 KiB, 8-way set associative
- 64 sets, 64 B line size
- shared by the two threads, per core
- 4 cycles for fastest load-to-use (simple pointer accesses)
- 5 cycles for complex addresses
- 32 B/cycle load bandwidth
- 16 B/cycle store bandwidth
- Write-back policy
- L2 Cache:
- Unified, 256 KiB, 8-way set associative
- 1024 sets, 64 B line size
- Non-inclusive
- 12 cycles for fastest load-to-use
- 32 B/cycle bandwidth to L1$
- Write-back policy
- L3 Cache/LLC:
- Up to 2 MiB Per core, shared across all cores
- Up to 16-way set associative
- Inclusive
- 64 B line size
- Write-back policy
- Per each core:
- Read: 32 B/cycle (@ ring clock)
- Write: 32 B/cycle (@ ring clock)
- 26-31 cycles latency
- System DRAM:
- 2 Channels
- 8 B/cycle/channel (@ memory clock)
- Up to DDR3-1600
- L0 µOP cache:
Sandy Bridge TLB consists of dedicated L1 TLB for instruction cache (ITLB) and another one for data cache (DTLB). Additionally there is a unified L2 TLB (STLB).
- TLBs:
- ITLB
- 4 KiB page translations:
- 128 entries; 4-way set associative
- dynamic partitioning
- 2 MiB / 4 MiB page translations:
- 8 entries per thread; fully associative
- Duplicated for each thread
- 4 KiB page translations:
- DTLB
- 4 KiB page translations:
- 64 entries; 4-way set associative
- fixed partition
- 2 MiB / 4 MiB page translations:
- 32 entries; 4-way set associative
- fixed partition
- 1G page translations:
- 4 entries; fully associative
- fixed partition
- 4 KiB page translations:
- STLB
- 4 KiB page translations:
- 512 entries; 4-way set associative
- fixed partition
- ITLB miss and a STLB hit is 7 cycles
- 4 KiB page translations:
- ITLB
Overview[edit]

Sandy Bridge was an entirely new microarchitecture which combines some of the improvements that were implemented in NetBurst along with the original P6 design. In addition to the new core design, Sandy Bridge took full advantage of Intel's 32 nm process which enabled the integration all the components of the chip on a single monolithic die, including the integrated graphics and the integrated memory controller. Sandy Bridge is the first Intel microarchitecture designed as a true system on a chip for high-volume client mainstream market. Previously (e.g., Nehalem) the integrated graphics and the memory interface were fabricated on a separate die which was packaged together and communicated over Intel's QuickPath Interconnect (QPI). The seperate dies were then packaged together as a system on a package.
As stated earlier, the individual cores are an entirely new design which improved both performance and power. Sandy Bridge introduced a number of performance features that brought better-than-linear performance/power as well as a number of enhancements that improved performance while saving power. Intel introduced a number of new vector computation (SIMD) and security instructions which improved floating point performance and throughput as well as speedup the throughput of various encryption algorithms. Sandy Bridge incorporates either two or four physical cores with either four or eight logical cores.
The block diagram on the right is a complete quad-core Sandy Bridge SoC which integrates the new System Agent (SA), the four physical cores along with their companion last level cache (LLC) slices, and the integrated graphics. Interconnecting everything is a complex high-bandwidth low-latency ring on-die which consists of six agents - one for each core and cache slice, one for the system agent, and one for the graphics. The upper portion of the diagram is the System Agent (SA) which incorporates the display controller, the memory controller, and the various I/O interfaces. Previously that component was referred to as the Memory Controller Hub (MCH) when on a separate die. Sandy Bridge incorporates 20 PCIe 2.0 lanes - x4 are used by the DMI with the other x16 lanes designed for a dedicated GPU. The memory controller supports up to dual-channel DDR3-1600 (depending on model).
System Architecture[edit]

Sandy Bridge was designed with configurability (i.e. modularity) scalability as the primary system goals. With the full integration of the graphics and memory controller hub on-die Intel needed a new way to efficiently interconnect all the individual components. Modularity was a major design goal for Sandy Bridge. Intel wanted to be able to design the cores and the graphics independently of the rest of the system and be able to detach the graphics and added more cores as desired.
The scalability goal was important for Intel's server configuration where the graphics are dropped and more cores can be added to the ring without compromising performance. Sandy Bridge comprised of a fairly robust ring implementation with bandwidth that can scale to more cores as necessary.
Cache Architecture[edit]
As part of the entire system overhaul, the cache architecture has been streamlined and was made more scalable. Sandy Bridge features a high-bandwidth last level cache which is shared by all the cores as well as the integrated graphics and the system agent. The LLC is an inclusive multi-bank cache architecture that is tightly associative with the individual cores. Each core is paired with a "slice" of LLC which is 2 MiB in size (lower amount for lower-end models). This pairing of cores and cache slices scales with the number of cores which provides a significant performance boost while saving power and bandwidth. Partitioning the data also helps simplify coherency as well as reducing localized contentions and hot spots.
Sandy Bridge is Intel's first microarchitecture to integrate the graphics on-die. One of the key enablers for this feature is the new cache architecture. Conceptually, the integrated graphics is treated just like another core. The graphics itself can decide which of its buffers (e.g., display or textures) will sit in the LLC and be coherent. Because it's possible for the graphics to use large amounts of memory, the possibility of thrashing had to be addressed. A Special mechanism has been implemented inside the cache in order to prevent thrashing. In order to prevent the graphics from flushing out all the core's data, that mechanism is capable of capping how much of the cache will be dedicated to the cores and how much will be dedicated to the graphics.
The last level cache is an inclusive cache with a 64 byte cache line organized as 16-way set associative. Each LLC slice is accessible to all cores. With up to 2 MiB per slice per core, a four-core model will sport a total of 8 MiB. Lower-end/budget models feature a smaller cache slice. This is done by disabling ways of cache in 4-way increments (for a granularity of 512 KiB). The LLC to use latency in Sandy Bridge has been greatly improved from 35-40+ in Nehalem to 26-31 cycles (depending on ring hops).
Cache Box[edit]
Within each cache slice is cache box. The cache box is the controller and agent serving as the interface between the LLC and the rest of the system (i.e., cores, graphics, and system agent). The cache box implements the ring logic and the address hashing and arbitration. It is also tasked with communicating with the System Agent on cache misses, non-cacheable accesses (such as in the case of I/O pulls), as well as external I/O snoop requests. The cache box is fully pipelined and is capable of working on multiple requests at the same time. Agent requests (e.g., ones from the GPU) are handled by the individual cache boxes via the ring. This is much different to how it was previously done in Westmere where a single unified cache handled everything. The distribution of slices allows Sandy Bridge to have higher associativity bandwidth while reducing traffic.
The entire physical address space is mapped distributively across all the slices using a hash function. On a miss, the core needs to decode the address to figure out which slice ID to request the data from. Physical addresses are hashed at the source in order to prevent hot spots. The cache box is responsible for the maintaining of coherency and ordering between requests. Because the LLC slices are fully inclusive, it can make efficienct use of an on-die snoop filter. Each slice makes use of Core Valid Bits (CVB) which is used to eliminate unnecessary snoops to the cores. A single bit per cache line is needed to indicate if the line may be in the core. Snoops are therefore only needed if the line is in the LLC and a CVB is asserted on that line. This mechanism helps limits external snoops to the cache box most of the time without resorting to going to the cores.
Note that both the cache slices and the cache boxes reside within the same clock domain as the cores themselves - sharing the same voltage and frequency and scaling along with the cores when needed.
Logic design techniques[edit]

One of the new challenges that Sandy Bridge presented is a consequence of the shared power plane that spans the cores and the L3 cache. Using standard design, the minimum voltage required to keep the L3 cache data alive may limit the minimum operating voltage of the cores. This would consequently adversely affect the average power of the system. In previous designs, this issue could be solved by moving the L3 to its own dedicated power plane that operated at a higher voltage. However, this solution would've substantially increased the power dissipation of the L3 cache and since Sandy Bridge incorporated as much as 8 MiB of L3 for the higher-end quad-core models, this impact would have accounted for a big fraction of die's overall power consumption. Intel used several logic design techniques to minimize the minimum voltage of the L3 cache and the register file to allow it to operate at a lower level than the core logic.

Shown here is a schematic of one of the techniques that were used in the register file in order to lower the minimum Vcc Min voltage. Intel noted that fabrication variations can cause write-ability degradation at low voltages - such as in the case where TP comes out stronger than TN. This method addresses the issue caused by a strong TP by weakening the memory cell pull-up device effective strength. Note the three parallel transistors on the very right side of the schematic (inside the square box) labeled T1, T2, and T3. The effective size of the shared PMOS is set during post-silicon production testing by enabling and disabling any combination of the three parallel transistors to achieve the desired result.
Ring Interconnect[edit]
In the pursuit of modularity, Sandy Bridge incorporates a new and robust high-bandwidth coherent interconnect that links all the separate components together. The ring is a system of interconnects between the cores, the graphics, the last level cache, and the System Agent. The ring allows Intel to scale up and down efficiently depending on the market segmentation which allows for finer balance of performance, power, and cost. The choice to use a ring makes design and validation easier compared to some of the more complex typologies such as packet routing. It's also easier configurability-wise. The concept design for a ring architectural started with the Nehalem-EX server architecture which had eight cores and needed greater bandwidth. When design for the Sandy Bridge client architecture started, Intel realized they needed similar behavior and similar bandwidth to feed the new larger cores and the memory-intensive on-die GPU which could use more bandwidth than all four cores combined.
Internally, the ring is composed of four physical independent rings which handle the communication and enforce coherency.
- 32-byte Data ring
- Request ring
- Acknowledge ring
- Snoop ring

The four rings consists of a considerable amount of wiring and routing. Because the routing runs in the upper metal layers over the LLC, the rings have no real impact on die area. As with the LLC slices, the ring is fully pipelined and operates within the core's clock domain as it scales with the frequency of the core. The bandwidth of the ring also scales in bandwidth with each additional core/$slice pair that is added onto the ring, however with more cores the ring becomes more congested and adding latency as the average hop count increases. Intel expected the ring to support a fairly large amount of cores before facing real performance issues.
It's important to note that the term ring refers to its structure and not necessarily how the data flows. The ring is not a round-robin and requests may travel up or down as needed. The use of address hashing allows the source agent to know exactly where the destination is. In order reduce latency, the ring is designed such as that all accesses on the ring always picks the shortest path. Because of this aspect of the ring and the fact that some requests can take longer than others to complete, the ring might have requests being handled out of order. It is the responsibility of the source agents to handle the ordering requirements. The ring cache coherency protocol is largely an enhancement based on Intel's QPI protocols with MESI-based source snooping protocol. On each cycle, the agents receive an indication whether there is an available slot on the ring for communication in the next cycle. When asserted, the agent can sent any type of communication (e.g. data or snoop) on the ring the following cycle.
The data ring is 32 bytes meaning each slice can pass half a cache line to the ring each cycle. This means that a dual-core operating at 4 GHz on both cores will have a total bandwidth of 256 GB/s with each connection having a bandwidth of 128 GB/s.
System Agent[edit]
- Main article: Intel's System Agent
The System Agent (SA) is a centralized peripheral device integration unit. It contains what was previously the traditional Memory Controller Hub (MCH) which includes all the I/O such as the PCIe, DMI, and others. Additionally the SA incorporates the memory controller and the display engine which works in tandem with the integrated graphics. The major enabler for the new System Agent is in fact the 32 nm process which allowed for considerably higher integration, over a dozen clock domains and PHYs.
The System Agent interfaces with the rest of the system via the ring in a similar manner to the cache boxes in the LLC slices. It is also in charge of handling I/O to cache coherency. The System Agent enables direct memory access (DMA), which allows devices to snoop the cache hierarchy. Address conflicts resulting from multiple concurrent requests associated with the same cache line are also handled by the System Agent.

It should be pointed out the with Sandy Bridge, only a single reference clock is fed into the System Agent. From there are, signals are multiplied and distribute the clocks across the entire system using set of PLLs locked onto the reference signal.
Power[edit]
With Sandy Bridge, Intel introduced a large number of power features to save powers depending on the workload, temperature, and what I/O is being utilized. The new power features are handled at the System Agent. Sandy Bridge introduced a fully-fledged Power Control Unit (PCU). The root concept for this unit started with Nehalem which embedded a discrete microcontroller on-die which handled all the power management related tasks in firmware. The new PCU extends on this functionality with numerous state machines and firmware algorithms. The use of firmware, which Intel Fellow Opher Kahn described at IDF 2010, contains 1000s of lines of code to handle very complex power management tasks. Intel uses firmware to be able to fine-tune chips post-silicon as well as fix problems to extract the best performance.
Sandy Bridge has three separate voltage domains: System Agent, Cores, and Graphics. Both the Cores and Graphics are variable voltage domains. Both of those domains are able to scale up and down with voltage and frequency based on controls from the Power Control Unit. The cores and graphics scale up and down depending on the workloads in order to deliver instantaneous performance boost through higher frequency whenever possible. The System Agent sits on a third power plane which is low voltage (especially on mobile devices) in order to consume as little power as necessary.
Core[edit]
Sandy Bridge can be considered the first brand new microarchitecture since the introduction of NetBurst and P6 prior. Sandy Bridge went back to the drawing board and incorporated many of beneficial elements from P6 as well as NetBurst. While NetBurst ended up being a seriously flawed architecture, its design was driven by a number of key innovations which were re-implemented and enhanced in Sandy Bridge. This is different from earlier architectures (i.e., Core through Nehalem) which were almost exclusively enhancements of P6 with nothing inherited from P4. Every aspect of the core was improved over its predecessors with very functional block being improved.

Pipeline[edit]
The Sandy Bridge core focuses on extracting performance and reducing power in a great number of ways. Intel placed heavy emphasis in the cores on performance enhancing features that can provide more-than-linear performance-to-power ratio as well as features that provide more performance while reducing power. The various enhancements can be found in both the front-end and the back-end of the core.
Broad Overview[edit]
| This section is empty; you can help add the missing info by editing this page. |
Front-end[edit]
The front-end is tasked with the challenge of fetching the complex x86 instructions from memory, decoding them, and delivering them to the execution units. In other words, the front end needs to be able to consistently deliver enough µOPs from the instruction code stream to keep the back-end busy. When the back-end is not being fully utilized, the core is not reaching its full performance. A weak or under-performing front-end will directly affect the back-end, resulting in a poorly performing core. In the case of Sandy Bridge base, this challenge is further complicated by various redirections such as branches and the complex nature of the x86 instructions themselves.
The entire front-end was redesigned from the ground up in Sandy Bridge. The four major changes in the front-end of Sandy Bridge is the entirely new µOP cache, the overhauled branch predictor and further decoupling of the front-end, and the improved macro-op fusion capabilities. All those features not only improve performance but they also reduce power draw at the same time.
Fetch & pre-decoding[edit]
Blocks of memory arrive at the core from either the cache slice or further down the ring from one of the other cache slice. On occasion, far less desirably, from main memory. On their first pass, instructions should have already been prefetched from the L2 cache and into the L1 cache. The L1 is a 32 KiB, 64B line, 8-way set associative cache. The instruction cache is identical in size to that of Nehalem's but its associativity was increased to 8-way. Sandy Bridge fetching is done on a 16-byte fetch window. A window size that has not changed in a number of generations. Up to 16 bytes of code can be fetched each cycle. Note that the fetcher is shared evenly between two threads, so that each thread gets every other cycle. At this point they are still macro-ops (i.e. variable-length x86 architectural instruction). Instructions are brought into the pre-decode buffer for initial preparation.

x86 instructions are complex, variable length, have inconsistent encoding, and may contain multiple operations. At the pre-decode buffer the instructions boundaries get detected and marked. This is a fairly difficult task because each instruction can vary from a single byte all the way up to fifteen. Moreover, determining the length requires inspecting a couple of bytes of the instruction. In addition boundary marking, prefixes are also decoded and checked for various properties such as branches. As with previous microarchitectures, the pre-decoder has a throughput of 6 macro-ops per cycle or until all 16 bytes are consumed, whichever happens first. Note that the predecoder will not load a new 16-byte block until the previous block has been fully exhausted. For example, suppose a new chunk was loaded, resulting in 7 instructions. In the first cycle, 6 instructions will be processed and a whole second cycle will be wasted for that last instruction. This will produce the much lower throughput of 3.5 instructions per cycle which is considerably less than optimal. Likewise, if the 16-byte block resulted in just 4 instructions with 1 byte of the 5th instruction received, the first 4 instructions will be processed in the first cycle and a second cycle will be required for the last instruction. This will produce an average throughput of 2.5 instructions per cycle. Note that there is a special case for length-changing prefix (LCPs) which will incur additional pre-decoding costs. Real code is often less than 4 bytes which usually results in a good rate.
Branch Predictor[edit]
The fetch works along with the branch prediction unit (BPU) which attempts to guess the flow of instructions. All branches utilize the BPU for their predictions, including returns, indirect calls and jumps, direct calls and jumps, and conditional branches. As with almost every iteration of Intel's microarchitecture, the branch predictor has also been improved. An improvement to the branch predictor has the unique consequence of directly improving both performance and power efficiency. Due to the deep pipeline, a flush is a rather expensive event which ends up discarding over 150 instructions that are in-flight. One of the big changes that was done in Nehalem and was carried over into Sandy Bridge is the further decoupling of the BPU between the front-end and the back-end. Prior to Nehalem, the entire pipeline had to be fully flushed before the front-end could resume operations. This was redone in Nehalem and the front-end can start decoding right away as soon as the correct path become known - all while the back-end is still flushing the badly speculated µOPs. This results in a reduced penalty (i.e. lower latency) for wrong target prediction. In addition, a large portion of the branch predictor in Sandy Bridge was actually entirely redesigned. The branch predictor incorporates the same mechanisms found in Nehalem: Indirect Target Array (ITA), the branch target buffer (BTB), Loop Detector (LD), and the renamed return stack buffer (RSB).
For near returns, Sandy Bridge has the same 16-entry return stack buffer. The BTB in Sandy Bridge is a single level structure that holds twice as many entries as Nehalem's L1/2 BTBs. This change should result increase the prediction coverage. It's interesting to note that prior to Nehalem, Intel previously used a single-level design in Core. This is done through compactness. Since most branches do not need nearly as many bits per branch, for larger displacements, a separate table is used. Sandy Bridge appears to have a BTB table with 4096 targets, same as NetBurst, which is organized as 1024 sets of 4 ways.
The global branch history table was not increased with Sandy Bridge, but was enhanced by removing certain branches from history that did not improve predictions. Additionally the unit features retains longer history for data dependent behaviors and has more effective history storage.
Instruction Queue & MOP-Fusion[edit]
| MOP-Fusion Example: | ||
cmp eax, [mem] jne loop |
→ | cmpjne eax, [mem], loop |
- See also: Macro-Operation Fusion
The pre-decoded instructions are delivered to the Instruction Queue (IQ). In Nehalem, the Instruction Queue has been increased to 18 entries which were shared by both threads. Sandy Bridge increased that number to 20 but duplicated over for each thread (i.e. 40 total entries).
One key optimization the instruction queue does is macro-op fusion. Sandy Bridge can fuse two macro-ops into a single complex one in a number of cases. In cases where a test or compare instruction with a subsequent conditional jump is detected, it will be converted into a single compare-and-branch instruction. With Sandy Bridge, Intel expanded the macro-op fusion capabilities further. Macro-fusion can now work with just about jump instruction such as ADD and SUB. This means that more new cases are now fusable. Perhaps the most important case is in most typical loops which have a counter followed by an exist condition. Those should now be fused. Those fused instructions remain fused throughout the entire pipeline and get executed as a single operation by the branch unit thereby saving bandwidth everywhere. Only one such fusion can be performed each cycle.
Decoding[edit]

Up to four instructions (or five in cases where one of the instructions was macro-fused) pre-decoded instructions are sent to the decoders each cycle. Like the fetchers, the decoders alternate between the two threads each cycle. Decoders read in macro-operations and emit regular, fixed length µOPs. The decoders organization in Sandy Bridge has been kept more or less the same as Nehalem. As with its predecessor, Sandy Bridge features four decodes. The decoders are asymmetric; the first one, Decoder 0, is a complex decoder while the other three are simple decoders. A simple decoder is capable of translating instructions that emit a single fused-µOP. By contrast, a complex decoder can decode anywhere from one to four fused-µOPs. Overall up to 4 simple instructions can be decoded each cycle with lesser amounts if the complex decoder needs to emit additional µOPs; i.e., for each additional µOP the complex decoder needs to emit, 1 less simple decoder can operate. In other words, for each additional µOP the complex decoder emits, one less decoder is active.
Sandy Bridge brought about the first 256-bit SIMD set of instructions called AVX. This extension expanded the sixteen pre-existing 128-bit XMM registers to 256-bit YMM registers for floating point vector operations (note that Haswell expanded this further to Integer operations as well). Most of the new AVX instructions have been designed as simple instructions that can be decoded by the simple decoders.
MSROM & Stack Engine[edit]
There are more complex instructions that are not trivial to be decoded even by complex decoder. For instructions that transform into more than four µOPs, the instruction detours through the microcode sequencer (MS) ROM. When that happens, up to 4 µOPs/cycle are emitted until the microcode sequencer is done. During that time, the decoders are disabled.
x86 has dedicated stack machine operations. Instructions such as PUSH, POP, as well as CALL, and RET all operate on the stack pointer (ESP). Without any specialized hardware, such operations would need to be sent to the back-end for execution using the general purpose ALUs, using up some of the bandwidth and utilizing scheduler and execution units resources. Since Pentium M, Intel has been making use of a Stack Engine. The Stack Engine has a set of three dedicated adders it uses to perform and eliminate the stack-updating µOPs (i.e. capable of handling three additions per cycle). Instruction such as PUSH are translated into a store and a subtraction of 4 from ESP. The subtraction in this case will be done by the Stack Engine. The Stack Engine sits after the decoders and monitors the µOPs stream as it passes by. Incoming stack-modifying operations are caught by the Stack Engine. This operation alleviates the burden of the pipeline from stack pointer-modifying µOPs. In other words, it's cheaper and faster to calculate stack pointer targets at the Stack Engine than it is to send those operations down the pipeline to be done by the execution units (i.e., general purpose ALUs).
New µOP cache & x86 tax[edit]

Decoding the variable-length, inconsistent, and complex x86 instructions is a nontrivial task. It's also expensive in terms of performance and power. Therefore, the best way for the pipeline to avoid those things is to simply not decode the instructions. This is exactly what Intel has done with Sandy Bridge and what's perhaps the single biggest feature that has been added to the core. With Sandy Bridge Intel introduced a new µOP cache unit or perhaps more appropriately called the Decoded Stream Buffer (DSB). The micro-op cache is unique in that it not only does substantially improve performance but it does so while significantly reducing power.
On the surface, the µOP cache can be conceptualized as a second instruction cache unit that is subset of the level one instruction cache. What's unique about it is that it stores actual decoded instructions (i.e., µOPs). While it shares many of the goals of NetBurst's trace cache, the two implementations are entirely different, this is especially true as it pertains to how it augments the rest of the front-end. The idea behind both mechanisms is to increase the front-end bandwidth by reducing reliance on the decoders.
The micro-op cache is organized into 32 sets of 8 cache lines with each line holding up to 6 µOP for a total of 1,536 µOPs. The cache is competitively shared between the two threads and can also hold pointers to the microcode sequencer ROM. It's also virtually addressed and is a strict subset of the L1 instruction cache (that is, the L1 is inclusive of the µOP cache). Each line includes additional meta info for the number of contained µOP and their length.
At any given time, the core operates on a contiguous chunks of 32 bytes of the instruction stream. Likewise, the µOP cache operates on full 32 B windows as well. This is by design so that the µOP cache could store and evict entire windows based on a LRU policy. Intel refers to the traditional pipeline path as the "legacy decode pipeline". On initial iteration, all instructions go through the legacy decode pipeline. Once the entire stream window is decoded and makes its to the allocation queue, a copy of the window is inserted into the µOP cache. This occurs simultaneously with all other operations; i.e., no additional cycles or stages are added for this functionality. On all subsequent iterations, the cached pre-decoded stream is sent directly to the allocation queue - bypassing fetching, predecoding, and decoding of actual x86 instructions, saving power and increasing throughput. This is also a much shorter pipeline, so latency is reduced as well.
Note that a single stream window of 32 bytes can only span 3 ways with 6 µOPs per line; this means that a maximum of 18 µOPs per window can be cached by the µOP cache. This consequently means a 32 byte window that generates more than 18 µOPs will not be allocated in the µOP cache and will have to go through the legacy decode pipeline instead. However, such scenarios are fairly rare and most workloads do benefit from this feature.
The µOP cache has an average hit rate of around 80%. During the instruction fetch, the branch predictor will probe the µOPs cache tags. A hit in the cache allows for up to 4 µOPs (possibly fused macro-ops) per cycle to be sent directly to the Instruction Decode Queue (IDQ), bypassing all the pre-decoding and decoding that would otherwise have to be done. During those cycles, the rest of the front-end is entirely clock-gated which is how the substantial power saving is gained. Whereas the legacy decode path works in 16-byte instruction fetch windows, the µOP cache has no such restriction and can deliver 4 µOPs/cycle corresponding to the much bigger 32-byte window. Since a single window can be made of up to 18 µOPs, up to 5 whole cycles may be required to read out the entire decoded stream. Nonetheless, the µOPs cache can deliver consistently higher bandwidth than the legacy pipeline which is limited to the 16-byte fetch window and can be a serious bottleneck if the average instruction length is more than four bytes per window.
It's interesting to note that the µOPs cache only operates on full windows, that is, a full 32B window that has all the µOPs cached. Any partial hits are required to go through the legacy decode pipeline as if nothing was cached. The choice to not handle partial cache hits is rooted in this features efficiency. On partial window hits the core will end up emitting some µOPs from the micro-op cache as well as having the legacy decode pipeline decoding the remaining missed µOPs. Effectively multiple components will end up emitting µOPs. Not only would such mechanism increase complexity, but it's also unclear how much, if any, benefits would be gained by that.
As noted earlier, the µOPs cache has its root in the original NetBurst trace cache, particularly as far as goals are concerned. But that's where the similarities end. The micro-op cache in Sandy Bridge can be seen as a light-weight, efficient µOPs delivery mechanism that can surpass the legacy pipeline whenever possible. This is different to the trace cache that attempted to effectively replace the entire front-end and use vastly inferior and slow fetch/decode for workloads that the trace cache could not handle. It's worth noting that the trace cache was costly and complicated (having dedicated components such as a trace BTB unit) and had various side-effects such as needing to flush on context switches. Deficiencies the µOP cache doesn't have. The trace cache resulted in a lot of duplication as well, for example NetBurst's 12k uops trace cache had a hit rate comparable to an 8 KiB-16 KiB L1I$ whereas this 1.5K µOPs cache cache is comparable to a 6 KiB instruction cache. This implies a significant storage efficiency of four-fold or greater.
Allocation Queue[edit]
The emitted µOPs from the decoders are sent directly to the Allocation Queue (AQ) or Instruction Decode Queue (IDQ). The Allocation Queue acts as the interface between the front-end (in-order) and the back-end (out-of-order). The Allocation Queue in Sandy Bridge has not changed from Nehalem which is still 28-entries per thread. The purpose of the queue is to help absorb bubbles which may be introduced in the front-end, ensuring that a steady stream of 4 µOPs are delivered each cycle.
µOP-Fusion & LSD[edit]
The IDQ does a number of additional optimizations as it queues instructions. The Loop Stream Detector (LSD) is a mechanism inside the IDQ capable of detecting loops that fit in the IDQ and lock them down. That is, the LSD can stream the same sequence of µOPs directly from the IDQ continuously without any additional fetching, decoding, or utilizing additional caches or resources. Streaming continues indefinitely until reaching a branch mis-prediction. The LSD is particularly excellent in for many common algorithms that are found in many programs (e.g., tight loops, intensive calc loops, searches, etc..). The LSD is a very primitive but efficient power saving mechanism because while the LSD is active, the rest of the front-end is effectively disabled - including both the decoders and the micro-op cache.
For loops to take advantage of the LSD they need to be smaller than 28 µOPs. However since this is largely a small power saving feature, in most cases the µOPs can take advantage of the new µOPs cache instead and see no measurable performance difference.
Execution engine[edit]

The back-end or execution engine of Sandy Bridge deals with the execution of out-of-order operations. Sandy Bridge back-end is a clear a happy merger of both NetBurst and P6. As with P6 (through Westmere), Sandy Bridge treats the three classes of µOPs (floating point, integer, and vector) separately. The implementation itself, however, is quite different. Sandy Bridge borrows the tracking and renaming architecture of NetBurst which is far more efficient.
Sandy Bridge uses the tracking technique found in NetBurst which uses a rename which is based on physical register file (PRF). All earlier predecessors, P6 through Westmere, utilized a Retirement Register File (RRF) along with a Re-Order Buffer (ROB) which was used to track the micro-ops and data that are in flight. ROB results are then written into the RRF on retirement. Sandy Bridge returned to a PRF, meaning all of the data is now stored in the PRF with a separate component dedicated for the various meta data such as status information. It's worth pointing out that since Sandy Bridge introduced AVX which extends register to 256-bit, moving to a PRF-based renaming architecture would have more than likely been a hard requirement as the amount of added complexity would've negatively impacted the entire design. Unlike a RRF, retirement is considerably simpler, requiring a simple mapping change between the architectural registers and the PRF, eliminating any actual data transfers - something that would've undoubtedly worsen with the new 256-bit AVX extension. An additional component, the Register Alias Tables (RAT), is used to maintain the mapping of logical registers to physical registers. This includes both architectural state and most recent speculated state. In Sandy Bridge, ReOrder Buffer (ROB) still exists but is a much simpler component that tracks the in-flight µOPs and their status.
In addition to the back-end architectural changes, Intel has also increased most of the buffers significantly, allowing for far more µOPs in-flight than before.
Renaming & Allocation[edit]
On each cycle, up to 4 µOPs can be delivered here from the front-end from one of the two threads. As stated earlier, the Re-Order Buffer is now a light-weight component that tracks the in-flight µOPs. The ROB in Sandy Bridge is 168 entries, allowing for up to 40 additional µOPs in-flight over Nehalem. At this point of the pipeline the µOPs are still handled sequentially (i.e., in order) with each µOP occupying the next entry in the ROB. This entry is used to track the correct execution order and statuses. In order for the ROB to rename an integer µOP, there needs to be an available Integer PRF entry. Likewise, for FP and SIMD µOPs there needs to be an available FP PRF entry. Following renaming, all bets are off and the µOPs are free to execute as soon as their dependencies are resolved.
It is at this stage that architectural registers are mapped onto the underlying physical registers. Other additional bookkeeping tasks are also done at this point such as allocating resources for stores, loads, and determining all possible scheduler ports. Register renaming is also controlled by the Register Alias Table (RAT) which is used to mark where the data we depend on is coming from (after that value, too, came from an instruction that has previously been renamed). Sandy Bridge's move to a PRF-based renaming has a fairly substantial impact on power too. With the new instruction set extension which allows for 256-bit operations, a retirement would've meant large amount of 256-bit values have to be needlessly moved to the Retirement Register File each time. This is entirely eliminated in Sandy Bridge. The decoupling of the PRFs from the RAT/ROB likely means some added latency is at play here, but the overall benefits are more than worth it.
There is no special costs involved in splitting up fused µOPs before execution or retirement and the two fused µOPs only occupy a single entry in the ROB, however the rename registers has more than doubled over Nehalem in order to accommodate those fused operations. The RAT is capable of handling 4 µOPs each cycle. Note that the ROB still operates on fused µOPs, therefore 4 µOPs can effectively be as high as 8 µOPs.
Since Sandy Bridge performs speculative execution, it can speculate incorrectly. When this happens, the architectural state is invalidated and as such needs to be rolled back to the last known valid state. Sandy Bridge has a 48-entry Branch Order Buffer (BOB) that keeps tracks of those states for this very purpose.
Optimizations[edit]
| Zeroing Idiom Example: |
xor eax, eax |
Not only does this instruction get eliminated at the ROB, but it's actually encoded as just 2 bytes 31 C0 vs the 5 bytes for mov eax, 0x0 which is encoded as b8 00 00 00 00.
|
Sandy Bridge introduced a number of new optimizations it performs prior to entering the out-of-order and renaming part. Two of those optimizations are Zeroing Idioms, and Ones Idioms. The first common optimization performed in Sandy Bridge is Zeroing Idioms elimination or a dependency breaking idiom. A number of common zeroing idioms are recognized and consequently eliminated. This is done prior to bookkeeping at the ROB, allowing those µOPs to save resources and eliminating them entirely and breaking any dependency. Eliminated zeroing idioms are zero latency and are entirely removed from the pipeline (i.e., retired).
Sandy Bridge recognizes instructions such as XOR, PXOR, and XORPS as zeroing idioms when the source and destination operands are the same. Those optimizations are done at the same rate as renaming during renaming (at 4 µOPs per cycle) and the architectural register is simply set to zero (no actual physical register is used).
The ones idioms is another dependency breaking idiom that can be optimized. In all the various PCMPEQx instructions that perform packed comparison the same register with itself always set all bits to one. On those cases, while the µOP still has to be executed, the instructions may be scheduled as soon as possible because the current state of the register needs not to be known.
Scheduler[edit]

Following bookkeeping at the ROB, µOPs are sent to the scheduler. Everything here can be done out-of-order whenever dependencies are cleared up and the µOP can be executed. Sandy Bridge features a very large unified scheduler that is dynamically shared between the two threads. The scheduler is exactly one and half times bigger than the reservation station found in Nehalem (a total of 54 entries). The various internal reordering buffers have been significantly increased as well. The use of a unified scheduler has the advantage of dipping into a more flexible mix of µOPs, resulting in a more efficient and higher throughput design.
Sandy Bridge has two distinct physical register files (PRF). 64-bit data values are stored in the 160-entry Integer PRF, while Floating Point and vector data values are stored in the Vector PRF which has been extended to 256 bits in order to accommodate the new AVX YMM registers. The Vector PRF is 144-entry deep which is slightly smaller than the Integer one. It's worth pointing out that prior to Sandy Bridge, code that relied on constant register reading was bottlenecked by a limitation in the register file which was limited to three reads. This restriction has been eliminated in Sandy Bridge.
At this point, µOPs are not longer fused and will be dispatched to the execution units independently. The scheduler holds the µOPs while they wait to be executed. A µOP could be waiting on an operand that has not arrived (e.g., fetched from memory or currently being calculated from another µOPs) or because the execution unit it needs is busy. Once the µOP is ready, they are dispatched through their designated port.
The scheduler will send the oldest ready µOP to be executed on each of the six ports each cycle. Sandy Bridge, like Nehalem has six ports. Port 0, 1, and 5 are used for executing computational operations. Each port has 3 stacks of execution units corresponding to the three classes of data types: Integer, SIMD Integer, and Floating Point. The Integer stack handles 64-bit general-purpose integer operations. The SIMD Integer and the Floating Point stacks are both 128-bit wide.
Each cluster operates within its own domain. Domains help refuse power for less frequently used domains and to simplify the routing networks. Data flowing within its domain (e.g., integer->integer or FP->FP) are effectively free and can be done each cycle. Data flowing between two separate domains (e.g., integer->FP or FP->integer) will incur an additional one or two cycles for the data to be forwarded to the appropriate domain.
Sandy Bridge ports 2, 3, and 4, are used for executing memory related operations such as loads and stores. Those ports all operate within the Integer stack due to integer latency sensitivity.
New 256-bit extension[edit]
Sandy Bridge introduced the AVX extension, a new 256-bit x86 floating point SIMD extension. The new instructions are implemented using an improved Vector EXtension (VEX) prefix byte sequence. Those instructions are in turn decoded into single µOPs most of the time.
In order to have a noticeable effect on performance, Intel opted to not to repeat their initial SSE implementation choices. Instead, Intel doubled the width of all the associated executed units. This includes a full hardware 256-bit floating point multiply, add, and shuffle - all having a single-cycle latency.
As mentioned earlier, both the Integer SIMD and the FP stacks are 128-bit wide. Widening the entire pipeline is a fairly complex undertaking. The challenge with introducing a new 256-bit extension is being able to double the output of one of the stacks while remaining invisible to the others. Intel solved this problem by cleverly dual-purposing the two existing 128-bit stacks during AVX operations to move full 256-bit values. For example a 256-bit floating point add operation would use the Integer SIMD domain for the lower 128-bit half and the FP domain for the upper 128-bit half to form the entire 256-bit value. The re-using of existing datapaths results in a fairly substantial die area and power saving.
Overall, Sandy Bridge achieves double the FLOP of Nehalem, capable of performing 256-bit multiply + 256-bit add each cycle. That is, Sandy Bridge can sustain 16 single-precision FLOP/cycle or 8 double-precision FLOP/cycle.
Scheduler Ports & Execution Units[edit]
Overall, Sandy Bridge is further enhanced with rebalanced ports. For example, the various string operations have been moved to port 0. A second has been augmented with LEA execution capabilities. Ports 0 and 1 gained additional capabilities such as integer blends. The various security enhancements that were added in Westmere have also been improved.
Retirement[edit]
Once a µOP executes, or in the case of fused µOPs both µOPs have executed, they can be retired. Sandy Bridge is able to commit up to four fused (which can be up to 6 unfused) µOPs each cycle. Retirement happens in-order and releases any used resources such as those used to keep track in the reorder buffer.
Memory subsystem[edit]

The memory subsystem in Sandy Bridge has been vastly improved.
One of the most sought-after improvements was increasing the load bandwidth. Loads are one of the most important µOPs in the core. With inadequate load bandwidth, computational code (specifically the new AVX) will effectively starve. Back in Nehalem, there were three ports for memory with two ports for address generation units. In particular, Port 2 was dedicated for data loads and Port 3 was dedicated for stores. Intel treats where you want to store the data and what you want to store as two distinct operations. Port 3 was used for the address calculation whereas Port 4 was used for the actual data. In Sandy Bridge, Intel made both ports symmetric; that is, both Port 2 and Port 3 are AGUs that may be used for load and stores, effectively doubling the load bandwidth. This allows for 2 loads and 1 store (48 bytes) each cycle which is much better suited for many computational operations over 1:1/cycle.
Following an address generation, the address is translated from virtual one to physical at the L1D$. Like Nehalem, the L1D cache is still 32 KiB and 8-way set associative. It is physically tagged, virtuallly index, and uses 64 B lines along with a write-back policy. The load-to-use latency is 4 cycles for integers and a few more cycles for SIMD/FP as they need to cross domains. Westmere added support for 1 GiB "Huge Pages", but those pages lacked dedicated DTLB entries forcing them to be fragmented across 2 MiB entries. This was addressed in Sandy Bridge with four entries for 1 GiB page.
In addition to making the two AGUs more flexible, many of the buffers were enlarged. The load buffer is now 33% larger, allowing for up to 64 load µOPs in-flight. Likewise, the store buffer has been slightly increased from 32 entries to 36. Both buffers are partitioned between the two threads. Altogether, Sandy Bridge can have 100 simultaneous memory operations in-flight. That's almost 60% of the entire capacity of the ROB used for memory operations.
As with the L1D, the L2 is organized the same as Nehalem. It's 256 KiB, 8-way set associative, and is non-inclusive of the L1; that is, L1 may or may not be found in the L2. The L2 to L1 bandwidth is 16 bytes/cycle in either direction. The L1 can either receive data from the L2 or send data to the Load/Store buffers each cycle, but not both. The L2 uses a write-back policy and has a 12-cycle load-to-use latency, which is slightly worse than the 10 cycles in Nehalem. From the CBox (i.e., LLC slice) to the ring, the bandwidth is 32 B/cycle, however Intel has not detailed how L3 to L2 works exactly, making modeling such behavior rather difficult.
Configurability[edit]
Configurability was a major design goal for Sandy Bridge and is something that Intel spent considerable effort on. With a highly-configurable design, using the same macro cells, Intel can meet the different market segment requirements. Sandy Bridge configurabiltiy was presented during the 2011 International Solid-State Circuits Conference. A copy of the paper can be found here.

The Sandy Bridge floorplan, power planes, and choppability axes are shown on the right in a diagram from Intel. The master design incorporates the four CPU cores, the GPU with 12 execution units, the 8 MiB shared L3 cache which is shared between them all, and the System Agent with the dual-channel DDR3 memory controller, 20 PCIe lanes controller, and a two parallel pipe display engines.
The design is modular, allowing for two of the cores to be "chopped off" along with their L3 slices to form a dual-core die. Additionally, the GPU can be optimized for a particular segment by reducing the number of execution units. Sandy Bridge allows for half of the execution units (i.e., down to six) to be chopped off for lower-end models. It's worth pointing out the the non-chop area of the GPU is greater due to the unslice and fixed-media functions of the GPU which are offered on all models regardless of the GPU configuration.
With over a dozen variations possible, Sandy Bridge is shipped in three of those configurations as actual fabricated dies.
- Die 1: 4 CPU Cores, 4 L3 Slices (8 MiB), and a GPU with 12 EUs. 1.16 billion transistors on a 216 mm² die.
- Die 2: 2 CPU Cores, 2 L3 Slices (4 MiB), and a GPU with 12 EUs. 624 million transistors on a 149 mm² die.
- Die 3: 2 CPU Cores, 2 L3 Slices (3 MiB), and a GPU with 6 EUs. 504 million transistors on a 131 mm² die.
It's worth pointing out that the each GPU execution unit is roughly 20 million transistors with 6 of them mounting to 120 million. There is also no quad-core configuration with a low-end GPU version (i.e., with 6 EUs). Additionally, die area is a much bigger concern with the dual-core die than it is with the quad-core die, hence the chunk of roughly 8 mm² of empty die space on the upper right corner of the die.
Fused features[edit]
Depending on the price segment, additional features may be disabled. For example, in the low-end value chips such as those under the Celeron brand may have more of the L3 cache disabled (e.g., 1 MiB of the 2 MiB) while the high-end performance Core i7 will have the entire 2 MiB cache enabled. The L3 cache can be fused off by slice with a granularity of 4-way 512 KiB chunks. For example, the full L3 cache is 2 MiB corresponding to 16-way set associative. Whereas a 1.5 MiB L3 slice which has 512 KiB disabled (4-way) is now 12-way set associative.
In addition to the cache, both multi-threading and the number of PCIe lanes offered can be disabled or enabled depending on the exact model offered.
Physical layout[edit]
Bellow are the die are breakdown for the DDR PHY, I/O PHY, SA, GPU, L3$, and the core. Note that the area of the DDR and I/O PHYs for the two smaller dies have been extrapolated from sizes of the components of the quad-core die and therefore may be off by a bit.
- Physical Layout Breakdown
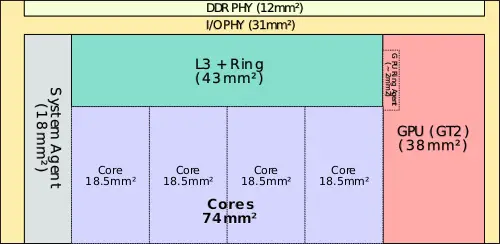
Quad-core die, GT2 GPU
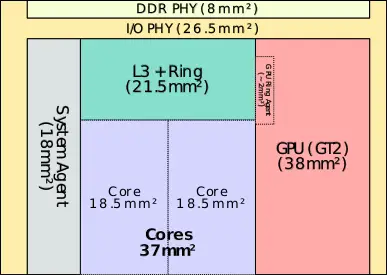
Dual-core die, GT2 GPU
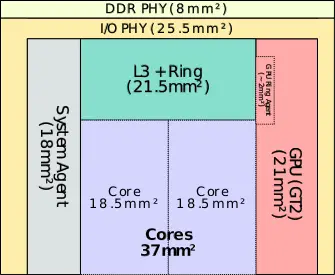
Dual-core die, GT1 GPU
.svg)
.svg)
.svg)
Some macrocells remain the same regardless of the die configuration. Below is the percentage breakdown by component for each of the dies. (Values may be rounded and not add to 100 exactly.)
| Area Percentage | |||
|---|---|---|---|
| Die Configuration | 4+2 | 2+2 | 2+1 |
| System Agent | 8.3% | 12.1% | 13.7% |
| L3$ + Ring | 19.9% | 14.4% | 16.4% |
| Cores | 34.3% | 24.8% | 28.2% |
| Integrated Graphics | 17.6 % | 25.5% | 16% |
| DDR/I/O PHYs | 19.9% | 23.2% | 25.6% |
Testability[edit]
With the higher level of integration testing also increases in complexity because the ability to observe data signals becomes increasingly complex as those signals are no longer exposed. Those internal signals are quite valuable because they can provide the designers with an insight into the flow of threads and data among the cores and caches. Sandy Bridge introduced the Generic Debug eXternal Connection (GDXC), a debug bus that allows snooping the ring bus in order to monitor the traffic that flows between the cores, GPU, caches, and the System Agent on the ring bus. GDXC allows chip, system or software debuggers to sample the traffic on ring bus including the ring protocol control signals themselves and dump the data to an external analyzer via a dedicated on-package probe array. GDXC is protected by an Intel patent US20100332927 filed Jun 30, 2009 and should expire on June 30, 2029.
It's worth pointing out the GDX is inherently vulnerable to a physical port attack if it's made accessible after factory testing.
Clock Domains[edit]

Sandy Bridge reworked the way clock generation is done. There are now 13 PLLs driving independent clock domains for the individual cores, the cache slices, the integrated graphics, the System Agent, and the four independent I/O regions. The goal was ensuring uniformity and consistency across all clock domains.
A single external reference clock is provided by the Platform Control Hub (PCH) chip. The BCLK, the System Bus Clock which dates back to the FSB, is now the reference clock which has been set to 100 MHz. Note that this has changed from 133 MHz in previous architectures. The BCLK is the reference edge for all the clock domains. Because the core slices and the integrated graphics have variable frequency which scales with workloads and voltage requirements, the Slice PLLs and GPU PLL sit behind their own 100 MHz Reference Spine. This was done to ensure clock skew is minimized as much as possible over the different power planes. Intel used low jitter PLLs (long term jitter σ < 2ps is reported) in addition to the vertical clock spines and embedded clock compensators to achieve good clock skew performance which was measured at 16 ps.
The System Agent PLL generates a variety of frequencies for the different zones like the PCU, SA, and Display Engine. Additionally, a seperate 133 MHz reference clock is also generated for main memory system.
Overclocking[edit]
Because of the way clock generation is done in Sandy Bridge, some overclocking capabilities are no longer possible. Overclocking is generally done on unlocked parts such as the Core i5-2500K and Core i7-2600K processors.

Some initial bad press surrounded Sandy Bridge overclocking capabilities because it was revealed that it can no longer be overclocked. Since the BCLK is used as the reference clock to all clock domains - including PCIe, Display Link, and System Agent, increasing the BCLK will most certainly introduces system instability (most likely involving I/O). Note that in the image on the left, the "DMICLK" is the same as the "BCLK". Intel reported very limited overclocking capabilities of ~2 to 3%. It's therefore been recommended to leave the BCLK at the 100 MHz value.
The overclock-able models can be overclocked using their clock multipliers, this requires the Desktop "P" PCH. In the diagram on the left (xC) refers to the Core Frequency and is represented as a multiple of BCLK (Core Frequency = BCLK × Core Freq Multiplier up to x57). Likewise (xM) refers to the memory ratio (up to 2133 MT/s).
Note that the (xP) and (xD) refer to the PEG (PCIe & Graphics) and DMI Ratios. Those ratios are not adjustable and scale with the BCLK if overclocked.
Power[edit]
Power consumption has been a key focus area for Sandy Bridge. The two power vectors that Sandy Bridge tries to address is the active power which is concerned with performance and idle power which is concerned with the average power of battery life.

The Power Control Unit (PCU) is located at the System Agent which incorporates the various power management hardware logic as well as a dedicated microcontroller which runs firmware that controls the various power features of the device. Communication with the physical cores and the graphics is done via a dedicate power management over the ring. The unit constantly reads the physical parameters in real time of the parts of the chip allowing it to optimize the power efficiency of the die. The power unit is exposed to the world via a set of external outputs which allows it to interact with rest of the system to control the voltage regulator and an external power management controller.
Sandy Bridge has two variable power planes and a single fixed power plane for the System Agent. The first one covers the ring, cache, and the physical cores. Note that this is a single power plane that is shared by all those components which means they all move together up or down in frequency and voltage. Each of the individual cores is capable of being entirely power gated when needed such as when the core goes into a higher C state. When this happens, the core state is saved into one of the ways of the cache and the core is entirely shut off. As with the cores, the caches can also be power-gated per way. With each deeper idle state, additional ways are invalidated and flushed and turned off.
The integrated graphics has its own variable power plane which can run at entirely different voltage and frequency than the cores. The graphics are not power gated but the voltage is cut off when the graphics needs to go into a sleep state. As mentioned earlier, the System Agent has a fixed power plane which many different voltages for the various I/Os and logic (e.g., Display, PCIe, DDR, etc..). The System Agent incorporates a programmable power plane which has a set of predefined voltages which the hardware signals can select from.
Active power optimization[edit]
Optimizing for performance means trying to deliver as much power as possible to demanding components all while meeting stringent constraints. Power algorithms take into account various constraints when considering what P-State (i.e., voltage and frequency) to operate in, which include the CPU capabilities, the platform specification (e.g. platform cooling capabilities), power delivery, graphics driver and operating system inputs as well as actual user controls (e.g. system preferences) and the type of workload (e.g. I/O bound workloads will not enjoy performance increase through increased frequency). Improvements in that area comes from throughput improvement and responsiveness (branded under "Turbo Boost 2.0").
In order to optimize the active power, you need to be able to determine the real time power. Sandy Bridge features Intel's 3rd generation power metering. Power metering is an event-based power meter which incorporates many different counters that track the main activity blocks of the die. Energy cost is then applied to the 100s of different event counters which are then summed up in order to obtain the active power. The die also incorporates fuses on different areas in order to be able to obtain the leakage and idle static power of the system which is used along with the active power to get an estimate of the entire chip's power. Most of this functionality is exposed to software as well via MSRs.
New thermal capacitance model[edit]

Prior to Sandy Bridge, Intel used a static model for thermal capacitance. That is, traditionally, if a model is certified for a specific TDP wattage, under no circumstance the chip will be allowed to run any hotter than that rating. This has the implication of treating temperature changes as instant. In reality temperature changes are not instant and there is a tiny bit of time early on when the heat sink is relatively cool and can absorb heat considerably faster. With Sandy Bridge, Intel moved to dynamic model which allows the chip to take advantage of the period of time when the heat spreader is still cool and can dissipate more heat quicker. For the desktop parts this can be a period of over a minute in which Sandy Bridge can operate at considerably higher frequencies and run much hotter.
Sandy Bridge uses an exponential average moving filter mode which can be used to estimate the energy budget.
Where P is the measured power from the power meter and TDP is the certified die power allowance. Therefore a chip running at considerably under the certified TDP accumulates energy budget which can then be used up when the chip needs an instantaneous boost in performance. Once the extra energy budget is exhausted, the chip must go back to within its certified TDP.
The driving motivation behind this change is the fact that humans are considerably slower than the computer. This often means that performance-critical actions are fairly sparse and spread out. For example opening an image might require high performance for a short burst of time in which after the user might take a little bit of time to think about his next action. During those pauses the system is more or less idle and can accumulate some extra energy budget which can then be used to speed up the user's next short period of high performance action. This allows the system to be more responsive when needed most.
Turbo Boost Technology 2.0[edit]

Intel introduced Turbo Boost Technology 2.0 (TBT 2.0) with Sandy Bridge. The ability to temporarily boost core frequency has been refined over the last couple of generations. Back in Core (Merom core), Intel was able to deliver a single bin of turbo when the other core was asleep. Intel improved on that in Nehalem by being able to deliver incrementally more bins the less cores are active. That is, slight speed bump for four cores, a few additional bins for when only two cores are active, and finally higher turbo for a single active core. With the introduction of Westmere, which integrated the graphics in the same package, introduced dynamic frequency for the graphics domain. What's common to all previous implementations is their conservatives in how many bins they were allowed to boost into, especially when you went into two and four active cores.
With Sandy Bridge and the SoC integration of the graphics and memory controller, Turbo Boost has been expanded substantially. With the new System Agent and the power control unit, the chip is able to take into account many more variables which were not previously present. This allow the power unit to make more accurate decisions regarding the available power headroom. This improvement allow the unit to allow higher turbo frequency when there is sufficient headroom while still staying within the required power envelope.
Idle power optimization[edit]
For mobility-specific power improvements, Intel improved battery life with Sandy Bridge as well as the overall power efficiency and reduced form factor. Key mobile features such as video playback have been substantially improved. The core, graphics, and package C-States have been enhanced to enable low-power idle and average power usage. Many new algorithms have been implemented which can take platform preferences from BIOS as well. This enables OEM to more finely tune the performance characteristics of the processor by indicating what kind of device this is and how power consumption and saving should be handled.
Graphics[edit]
- Main article: Gen6
Sandy Bridge supports up to two independent displays.
| Gen6 IGP Models | Standards | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Name | Execution Units | Tier | Series | Direct3D | OpenGL | |||||
| Windows | Linux | HLSL | Windows | Linux | ||||||
| HD Graphics | 6 | GT1 | M/H | 10.1 | N/A | 4.1 | 3.1 | 3.3 | ||
| HD Graphics 2000 | 6 | GT1 | H | |||||||
| HD Graphics 3000 | 12 | GT2 | M/H | |||||||
| HD Graphics P3000 | 12 | GT2 | DT | |||||||
Hardware Accelerated Video[edit]
| [Edit] Sandy Bridge (Gen6) Hardware Accelerated Video Capabilities | |||||||
|---|---|---|---|---|---|---|---|
| Codec | Encode | Decode | |||||
| Profiles | Levels | Max Resolution | Profiles | Levels | Max Resolution | ||
| MPEG-2 (H.262) | ✘ | Main | Main, High | Up to 80 Mbps | |||
| MPEG-4 AVC (H.264) | Main | 4.1 | Up to 40 Mbps | Main, High | 4.1 | Up to 40 Mbps | |
| VC-1 | ✘ | Advanced, Main, Simple | 3, High, Simple | Up to 40 Mbps | |||
Sockets/Platform[edit]
Sandy Bridge comes in three different C4 packages: PGA for mobile computers, LGA for desktop systems and BGA for small form factor systems. For each of the three different dies (see § Configurability), a different package stack-up was developed optimized for a particular vector: 10 layers for the highest power consumption, and 8 or 6 layers for the smaller dies.
| Package | Permanent | Platform | Chipset | Bus |
|---|---|---|---|---|
| FCBGA-1023 | Yes | 2-chip solution | Cougar Point | DMI 2.0 |
| FCBGA-1224 | Yes | |||
| rPGA988B | No | |||
| LGA-1155 | No |
Die[edit]
Sandy Bridge desktop and mobile consist of 2 and 4 core models, each with their own die. One of the most noticeable changes on die is the integration of the GPU and the memory interface. The major components of the die are:
- System Agent
- CPU Core
- Ring bus interconnect
- Memory Controller
System Agent[edit]
The System Agent (SA) contains the Display Engine (DE), Power management units, and the various I/O buses.

.png)
Core[edit]
Sandy Bridge Client models come in either 2x core or 4x core setup.
- 18.5 mm² die size

.png)
Core Group[edit]
Client models come in groups of 2 or 4 cores.
- 2-cores group:
- 58.5 mm² die size
- 2 Cores: 2x 18.5 mm² = 37 mm²
- L3 Cache: 2x 10.75 mm² = 21.5 mm²
- 58.5 mm² die size
- 4-core group
- 117 mm² die size
- 4 Cores: 4x 18.5 mm² = 74 mm²
- L3 Cache: 4x 10.75 mm² = 43 mm²
- 117 mm² die size

Dual-Core (GT1)[edit]
- 504,000,000 transistors
- 32 nm process
- 131 mm² die size
- 2 CPU cores
- 1 GPU core
- 6 EUs
Dual-Core (GT2)[edit]
- 624,000,000 transistors
- 32 nm process
- 149 mm² die size
- 2 CPU cores
- 1 GPU core
- 12 EUs
.jpg)
Quad-Core[edit]
Quad-core Sandy Bridge die:
- 1,160,000,000 transistors (995,000,000 transistors pre-layout)
- 32 nm process
- 216 mm² die size
- 4 CPU cores
- 1 GPU core
- 12 EUs
.jpg)
_(annotated).png)
Wafer[edit]

.png)
Additional Shots[edit]
Additional die and wafer shots provided by Intel:

A partial wafer shot showing a complete quad-core die along with eight other dies around it.

An entire Sandy Bridge Wafer.

Partial wafer shot, angled. shot 1.

Partial wafer shot, angled. shot 2.

Partial wafer shot, angled. shot 3.





All Sandy Bridge Chips[edit]
| List of Sandy Bridge Processors | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Main processor | Turbo Boost | Mem | IGP | ||||||||||||||||
| Model | Launched | Price | Family | Core Name | Cores | Threads | L2$ | L3$ | TDP | Frequency | 1 Core | 2 Cores | 3 Cores | 4 Cores | Max Mem | GPU | Frequency | Turbo | |
| 787 | July 2011 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||||
| 797 | January 2012 | $ 107.00 € 96.30 £ 86.67 ¥ 11,056.31 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||||
| 807 | July 2012 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 1 | 2 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||||
| 807UE | July 2012 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 10 W 10,000 mW 0.0134 hp 0.01 kW | 1 GHz 1,000 MHz 1,000,000 kHz | 4 GiB 4,096 MiB 4,194,304 KiB 4,294,967,296 B 0.00391 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 817 | 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 827 | 2012 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 827E | July 2011 | $ 89.00 € 80.10 £ 72.09 ¥ 9,196.37 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | |||||
| 837 | 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 847 | June 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.1 GHz 1,100 MHz 1,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | |||||
| 847E | June 2011 | $ 111.00 € 99.90 £ 89.91 ¥ 11,469.63 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.1 GHz 1,100 MHz 1,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | |||||
| 857 | July 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.2 GHz 1,200 MHz 1,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 867 | January 2012 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 877 | July 2012 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 887 | September 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| 887E | September 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| 897 | 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| B710 | June 2011 | $ 70.00 € 63.00 £ 56.70 ¥ 7,233.10 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B720 | January 2012 | $ 70.00 € 63.00 £ 56.70 ¥ 7,233.10 | Celeron | Sandy Bridge M | 1 | 1 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B730 | July 2012 | $ 70.00 € 63.00 £ 56.70 ¥ 7,233.10 | Celeron | Sandy Bridge M | 1 | 2 | 0.25 MiB 256 KiB 262,144 B 2.441406e-4 GiB | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B800 | June 2011 | $ 80.00 € 72.00 £ 64.80 ¥ 8,266.40 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B810 | 14 March 2011 | $ 72.00 € 64.80 £ 58.32 ¥ 7,439.76 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||||
| B810E | June 2011 | $ 72.00 € 64.80 £ 58.32 ¥ 7,439.76 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B815 | January 2012 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | |||||
| B820 | July 2012 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | |||||
| B830 | July 2011 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | |||||
| B840 | July 2011 | $ 86.00 € 77.40 £ 69.66 ¥ 8,886.38 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B860E | 2012 | Celeron | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| i3-2308M | February 2011 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ||||||
| i3-2310E | February 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | |||||
| i3-2310M | February 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2312M | June 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2328M | September 2012 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2330E | June 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,050 MHz 1.05 GHz 1,050,000 KHz | |||||
| i3-2330M | June 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2332M | September 2011 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ||||||
| i3-2340UE | June 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | |||||
| i3-2348M | January 2013 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| i3-2350LM | October 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| i3-2350M | October 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| i3-2355M | 2012 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| i3-2357M | June 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||||
| i3-2365M | September 2012 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| i3-2367M | October 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| i3-2370LM | 2012 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ||||||
| i3-2370M | January 2012 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| i3-2375M | January 2013 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| i3-2377M | September 2012 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| i3-2390M | 2012 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ||||||
| i3-2393M | 14 August 2011 | $ 50.00 € 45.00 £ 40.50 ¥ 5,166.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2394M | October 2011 | $ 50.00 € 45.00 £ 40.50 ¥ 5,166.50 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| i3-2395M | 2012 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| i3-2397M | 2012 | Core i3 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| i5-2410M | February 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |||
| i5-2415M | February 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||
| i5-2430M | October 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | ||||
| i5-2435M | October 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||
| i5-2450M | January 2012 | $ 800.00 € 720.00 $ 823.00£ 648.00 ¥ 82,664.00 € 740.70 £ 666.63 ¥ 85,040.59 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||
| i5-2467M | June 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 2.3 GHz 2,300 MHz 2,300,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | ||||
| i5-2475M | 2012 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2477M | June 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | |||||||
| i5-2487M | 2012 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | |||||||
| i5-2490M | October 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2497M | June 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | |||||||
| i5-2510E | February 2011 | $ 266.00 € 239.40 £ 215.46 ¥ 27,485.78 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||
| i5-2515E | February 2011 | $ 266.00 € 239.40 £ 215.46 ¥ 27,485.78 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||
| i5-2520M | February 2011 | $ 225.00 € 202.50 £ 182.25 ¥ 23,249.25 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |||
| i5-2537M | February 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 2.3 GHz 2,300 MHz 2,300,000 kHz | 2 GHz 2,000 MHz 2,000,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 900 MHz 0.9 GHz 900,000 KHz | |||
| i5-2540LM | February 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2540M | February 2011 | $ 266.00 € 239.40 £ 215.46 ¥ 27,485.78 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.6 GHz 2,600 MHz 2,600,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |||
| i5-2547M | June 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2557M | June 2011 | $ 250.00 € 225.00 £ 202.50 ¥ 25,832.50 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |||
| i5-2560LM | October 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2560M | October 2011 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i5-2580M | 2012 | Core i5 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 3 MiB 3,072 KiB 3,145,728 B 0.00293 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i7-2535QM | 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | |||||||
| i7-2570QM | 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i7-2610UE | February 2011 | $ 317.00 € 285.30 £ 256.77 ¥ 32,755.61 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 850 MHz 0.85 GHz 850,000 KHz | |||
| i7-2617M | February 2011 | $ 289.00 € 260.10 £ 234.09 ¥ 29,862.37 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.3 GHz 2,300 MHz 2,300,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 950 MHz 0.95 GHz 950,000 KHz | |||
| i7-2620M | February 2011 | $ 346.00 € 311.40 £ 280.26 ¥ 35,752.18 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |||
| i7-2627M | 2011 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | ||||||
| i7-2629M | February 2011 | $ 311.00 € 279.90 £ 251.91 ¥ 32,135.63 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 500 MHz 0.5 GHz 500,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||
| i7-2630QM | January 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |
| i7-2635QM | January 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |
| i7-2637M | June 2011 | $ 289.00 € 260.10 £ 234.09 ¥ 29,862.37 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 2.8 GHz 2,800 MHz 2,800,000 kHz | 2.5 GHz 2,500 MHz 2,500,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |||
| i7-2640M | 4 September 2011 | $ 346.00 € 311.40 £ 280.26 ¥ 35,752.18 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.8 GHz 2,800 MHz 2,800,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |||
| i7-2649M | February 2011 | $ 346.00 € 311.40 £ 280.26 ¥ 35,752.18 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 500 MHz 0.5 GHz 500,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||
| i7-2655LE | February 2011 | $ 346.00 € 311.40 £ 280.26 ¥ 35,752.18 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 25 W 25,000 mW 0.0335 hp 0.025 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.5 GHz 2,500 MHz 2,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |||
| i7-2655QM | 4 September 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | ||||||
| i7-2657M | February 2011 | $ 317.00 € 285.30 £ 256.77 ¥ 32,755.61 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.4 GHz 2,400 MHz 2,400,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||
| i7-2660M | 2011 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.9 GHz 2,900 MHz 2,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i7-2667M | 2011 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | ||||||
| i7-2669M | 2011 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 500 MHz 0.5 GHz 500,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ||||||
| i7-2670QM | 4 September 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ||||
| i7-2675QM | 4 September 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | ||||
| i7-2677M | June 2011 | $ 317.00 € 285.30 £ 256.77 ¥ 32,755.61 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.6 GHz 2,600 MHz 2,600,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics 3000 | 350 MHz 0.35 GHz 350,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |||
| i7-2685QM | 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | ||||||
| i7-2689M | 2011 | Core i7 | Sandy Bridge M | 2 | 4 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 4 MiB 4,096 KiB 4,194,304 B 0.00391 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 500 MHz 0.5 GHz 500,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | ||||||
| i7-2710QE | January 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |
| i7-2715QE | January 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 2.9 GHz 2,900 MHz 2,900,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 2.7 GHz 2,700 MHz 2,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,200 MHz 1.2 GHz 1,200,000 KHz | |
| i7-2720QM | January 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 3 GHz 3,000 MHz 3,000,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-2740QM | 4 September 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i7-2760QM | 4 September 2011 | $ 378.00 € 340.20 £ 306.18 ¥ 39,058.74 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 6 MiB 6,144 KiB 6,291,456 B 0.00586 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-2820QM | January 2011 | $ 568.00 € 511.20 £ 460.08 ¥ 58,691.44 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 3.1 GHz 3,100 MHz 3,100,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-2840QM | 4 September 2011 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | ||||||
| i7-2860QM | 4 September 2011 | $ 568.00 € 511.20 £ 460.08 ¥ 58,691.44 | Core i7 | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 45 W 45,000 mW 0.0603 hp 0.045 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-2920XM | 9 January 2011 | $ 1,096.00 € 986.40 £ 887.76 ¥ 113,249.68 | Core i7EE | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 55 W 55,000 mW 0.0738 hp 0.055 kW | 2.5 GHz 2,500 MHz 2,500,000 kHz | 3.5 GHz 3,500 MHz 3,500,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 3.2 GHz 3,200 MHz 3,200,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-2960XM | 4 September 2011 | $ 1,096.00 € 986.40 £ 887.76 ¥ 113,249.68 | Core i7EE | Sandy Bridge M | 4 | 8 | 1 MiB 1,024 KiB 1,048,576 B 9.765625e-4 GiB | 8 MiB 8,192 KiB 8,388,608 B 0.00781 GiB | 55 W 55,000 mW 0.0738 hp 0.055 kW | 2.7 GHz 2,700 MHz 2,700,000 kHz | 3.7 GHz 3,700 MHz 3,700,000 kHz | 3.6 GHz 3,600 MHz 3,600,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 3.4 GHz 3,400 MHz 3,400,000 kHz | 32 GiB 32,768 MiB 33,554,432 KiB 34,359,738,368 B 0.0313 TiB | HD Graphics 3000 | 650 MHz 0.65 GHz 650,000 KHz | 1,300 MHz 1.3 GHz 1,300,000 KHz | |
| i7-3960X | 14 November 2011 | Core i7EE | Sandy Bridge E | 6 | 12 | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 15 MiB 15,360 KiB 15,728,640 B 0.0146 GiB | 130 W 130,000 mW 0.174 hp 0.13 kW | 3.3 GHz 3,300 MHz 3,300,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.9 GHz 3,900 MHz 3,900,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | |||||
| i7-3970X | 12 November 2012 | Core i7EE | Sandy Bridge E | 6 | 12 | 1.5 MiB 1,536 KiB 1,572,864 B 0.00146 GiB | 15 MiB 15,360 KiB 15,728,640 B 0.0146 GiB | 150 W 150,000 mW 0.201 hp 0.15 kW | 3.5 GHz 3,500 MHz 3,500,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 4 GHz 4,000 MHz 4,000,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 3.8 GHz 3,800 MHz 3,800,000 kHz | 64 GiB 65,536 MiB 67,108,864 KiB 68,719,476,736 B 0.0625 TiB | |||||
| 907 | 2012 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.7 GHz 1,700 MHz 1,700,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 917 | 2012 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.8 GHz 1,800 MHz 1,800,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 927 | 2012 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.9 GHz 1,900 MHz 1,900,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | ||||||
| 957 | 13 June 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.2 GHz 1,200 MHz 1,200,000 kHz | 8 GiB 8,192 MiB 8,388,608 KiB 8,589,934,592 B 0.00781 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 800 MHz 0.8 GHz 800,000 KHz | |||||
| 967 | 3 October 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.3 GHz 1,300 MHz 1,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 977 | 16 January 2012 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.4 GHz 1,400 MHz 1,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 987 | September 2012 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.5 GHz 1,500 MHz 1,500,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| 997 | September 2012 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 17 W 17,000 mW 0.0228 hp 0.017 kW | 1.6 GHz 1,600 MHz 1,600,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 350 MHz 0.35 GHz 350,000 KHz | 1,000 MHz 1 GHz 1,000,000 KHz | |||||
| B940 | 13 June 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2 GHz 2,000 MHz 2,000,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| B950 | 13 June 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.1 GHz 2,100 MHz 2,100,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| B960 | 3 October 2011 | $ 134.00 € 120.60 £ 108.54 ¥ 13,846.22 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.2 GHz 2,200 MHz 2,200,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,100 MHz 1.1 GHz 1,100,000 KHz | |||||
| B970 | 16 January 2012 | $ 125.00 € 112.50 £ 101.25 ¥ 12,916.25 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.3 GHz 2,300 MHz 2,300,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| B980 | September 2012 | $ 125.00 € 112.50 £ 101.25 ¥ 12,916.25 | Pentium | Sandy Bridge M | 2 | 2 | 0.5 MiB 512 KiB 524,288 B 4.882812e-4 GiB | 2 MiB 2,048 KiB 2,097,152 B 0.00195 GiB | 35 W 35,000 mW 0.0469 hp 0.035 kW | 2.4 GHz 2,400 MHz 2,400,000 kHz | 16 GiB 16,384 MiB 16,777,216 KiB 17,179,869,184 B 0.0156 TiB | HD Graphics (Sandy Bridge) | 650 MHz 0.65 GHz 650,000 KHz | 1,150 MHz 1.15 GHz 1,150,000 KHz | |||||
| Count: 122 | |||||||||||||||||||
References[edit]
- Sandy Bridge Breaks the Mold for Chip Codenames, December 29, 2010
- Lempel, Oded. "2nd Generation Intel® Core Processor Family: Intel® Core i7, i5 and i3." Hot Chips 23 Symposium (HCS), 2011 IEEE. IEEE, 2011.
- Rotem, Efi, et al. "Power management architecture of the 2nd generation Intel® Core microarchitecture, formerly codenamed Sandy Bridge." Hot Chips 23 Symposium (HCS), 2011 IEEE. IEEE, 2011.
- Yuffe, Marcelo, et al. "A fully integrated multi-CPU, GPU and memory controller 32nm processor." Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2011 IEEE International. IEEE, 2011.
- Valentine, Bob. "Introducing sandy bridge." Intel Developer Forum, San Francisco. 2010.
Documents[edit]
- Valentine, Bob. "Introducing sandy bridge." Intel Developer Forum, San Francisco. 2010.
- 2nd Generation Intel® Core Processor Family
- 2nd Generation Intel® Core vPro Processor Family
- 2nd Generation Intel® Core vPro Processor Family; New levels of security, manageability, and responsiveness
| codename | Sandy Bridge (client) + |
| core count | 2 + and 4 + |
| designer | Intel + |
| first launched | September 13, 2010 + |
| full page name | intel/microarchitectures/sandy bridge (client) + |
| instance of | microarchitecture + |
| instruction set architecture | x86-64 + |
| manufacturer | Intel + |
| microarchitecture type | CPU + |
| name | Sandy Bridge (client) + |
| phase-out | November 2012 + |
| pipeline stages (max) | 19 + |
| pipeline stages (min) | 14 + |
| process | 32 nm (0.032 μm, 3.2e-5 mm) + |